Detecting Issues in (Unsupervised) Datasets Without Labels

This tutorial demonstrates how to use Cleanlab Studio’s Python API to analyze and find issues in datasets without labels. This can be useful if you don’t have a single column in your dataset that you want to predict values for but still want to find issues such as low-quality/unsafe image or text content (e.g. NSFW or blurry images, toxic or unreadable text). In machine learning nomenclature, working with such data is called unsupervised learning (because there is no supervised label to predict).
Cleanlab Studio supports analyzing data without labels for text and image modalities. In this tutorial, we’ll look at a text dataset consisting of Tweets about airlines. This tutorial can be generally used to detect issues in any text column of a dataset or collection of images.
Note: analyzing data without labels is currently only supported in the Python API. If you require an interactive interface to improve your unsupervised dataset, please contact us to discuss your use case.
Install and import dependencies
pip install -U cleanlab-studio
import pandas as pd
from cleanlab_studio import Studio
from IPython.display import display
pd.set_option('display.max_colwidth', None)
Prepare and Upload Dataset
Our dataset for this tutorial is a collection of Tweets directed at various airlines.
Load Dataset
We’ll load the dataset into a Pandas DataFrame from a CSV file hosted in S3. The CSV file contains the following columns:
tweet_id,text
0,@VirginAmerica What @dhepburn said.
1,@VirginAmerica plus you've added commercials to the experience... tacky.
<id of tweet>,<tweet text>
You can similarly format any other text or image dataset and run the rest of this tutorial. Details on how to format your dataset can be found in this guide, which also outlines other format options.
dataset_url = "https://cleanlab-public.s3.amazonaws.com/StudioDemoDatasets/tweets-tutorial.csv"
df = pd.read_csv(dataset_url)
display(df.head(3))
| tweet_id | text | |
|---|---|---|
| 0 | 0 | @VirginAmerica What @dhepburn said. |
| 1 | 1 | @VirginAmerica plus you've added commercials to the experience... tacky. |
| 2 | 2 | @VirginAmerica I didn't today... Must mean I need to take another trip! |
Load Dataset into Cleanlab Studio
First instantiate a Studio object, which can be used to analyze your dataset.
# you can find your API key by going to app.cleanlab.ai/upload,
# clicking "Upload via Python API", and copying the API key there
API_KEY = "<insert your API key>"
studio = Studio(API_KEY)
Next load the dataset into Cleanlab Studio (more details/options can be found in this guide). This may take a while for big datasets.
dataset_id = studio.upload_dataset(df, dataset_name="Tweets (no-labels)")
Launch a Project
Let’s now create a project using this dataset. A Cleanlab Studio project will automatically train ML models to provide AI-based analysis of your dataset.
Here, we explicitly set the task_type parameter to unsupervised to specify that there is no supervised ML training task to run. If you would like to run supervised ML training and detect label errors in a labeled dataset or annotate unlabeled data, instead choose another ML task type (e.g. "multi-class", "multi-label", or "regression"; see this guide for details).
project_id = studio.create_project(
dataset_id=dataset_id,
project_name="Tweets (no-labels) Project",
modality="text",
task_type="unsupervised",
model_type="regular", # text issue detection is currently only available in Regular mode
label_column=None,
)
print(f"Project successfully created and training has begun! project_id: {project_id}")
Above, we specified modality="text" because this tutorial uses a text dataset; you can specify modality="image" if you’re using a image dataset. See the documentation for create_project for the full set of options.
Once the project has been launched successfully and you see your project_id, feel free to close this notebook. It will take some time for Cleanlab’s AI to train on your data and analyze it. Come back after training is complete (you will receive an email) and continue with the notebook to review your results.
You should only execute the above cell once per dataset. After launching the project, you can poll for its status to programmatically wait until the results are ready for review. Each project creates a cleanset, an improved version of your original dataset that contains additional metadata for helping you clean up the data. The next code cell simply waits until this cleanset has been created.
Warning! For big datasets, this next cell may take a long time to execute while Cleanlab’s AI model is training. If your notebook has timed out during this process, you can resume work by re-running the below cell (which should return the cleanset_id instantly if the project has completed training). Do not re-run the above cell and create a new project.
cleanset_id = studio.get_latest_cleanset_id(project_id)
print(f"cleanset_id: {cleanset_id}")
project_status = studio.wait_until_cleanset_ready(cleanset_id, show_cleanset_link=True)
Once the above cell completes execution, your project results are ready for review!
Download Cleanlab columns
We can fetch the Cleanlab columns that contain the metadata of this cleanset using its cleanset_id. These columns have the same length as your original dataset and provide metadata about each individual data point, like what types of issues it exhibits and how severe these issues are.
If at any point you want to re-run the remaining parts of this notebook (without creating another project), simply call studio.download_cleanlab_columns(cleanset_id) with the cleanset_id printed from the previous cell.
cleanlab_columns_df = studio.download_cleanlab_columns(cleanset_id)
cleanlab_columns_df.head()
| tweet_id | is_empty_text | text_num_characters | is_PII | PII_score | PII_types | PII_items | is_informal | informal_score | is_non_english | non_english_score | predicted_language | is_toxic | toxic_score | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | False | 35 | True | 0.2 | ["Twitter username"] | ["@VirginAmerica", "@dhepburn"] | True | 0.548850 | False | 0.471635 | <NA> | False | 0.088318 |
| 1 | 1 | False | 72 | True | 0.2 | ["Twitter username"] | ["@VirginAmerica"] | True | 0.695925 | False | 0.049899 | <NA> | False | 0.613281 |
| 2 | 2 | False | 71 | True | 0.2 | ["Twitter username"] | ["@VirginAmerica"] | True | 0.579822 | False | 0.035695 | <NA> | False | 0.111877 |
| 3 | 3 | False | 126 | True | 0.2 | ["Twitter username"] | ["@VirginAmerica"] | False | 0.333150 | False | 0.088203 | <NA> | False | 0.651367 |
| 4 | 4 | False | 55 | True | 0.2 | ["Twitter username"] | ["@VirginAmerica"] | True | 0.625234 | False | 0.059800 | <NA> | False | 0.296875 |
Review detected data issues
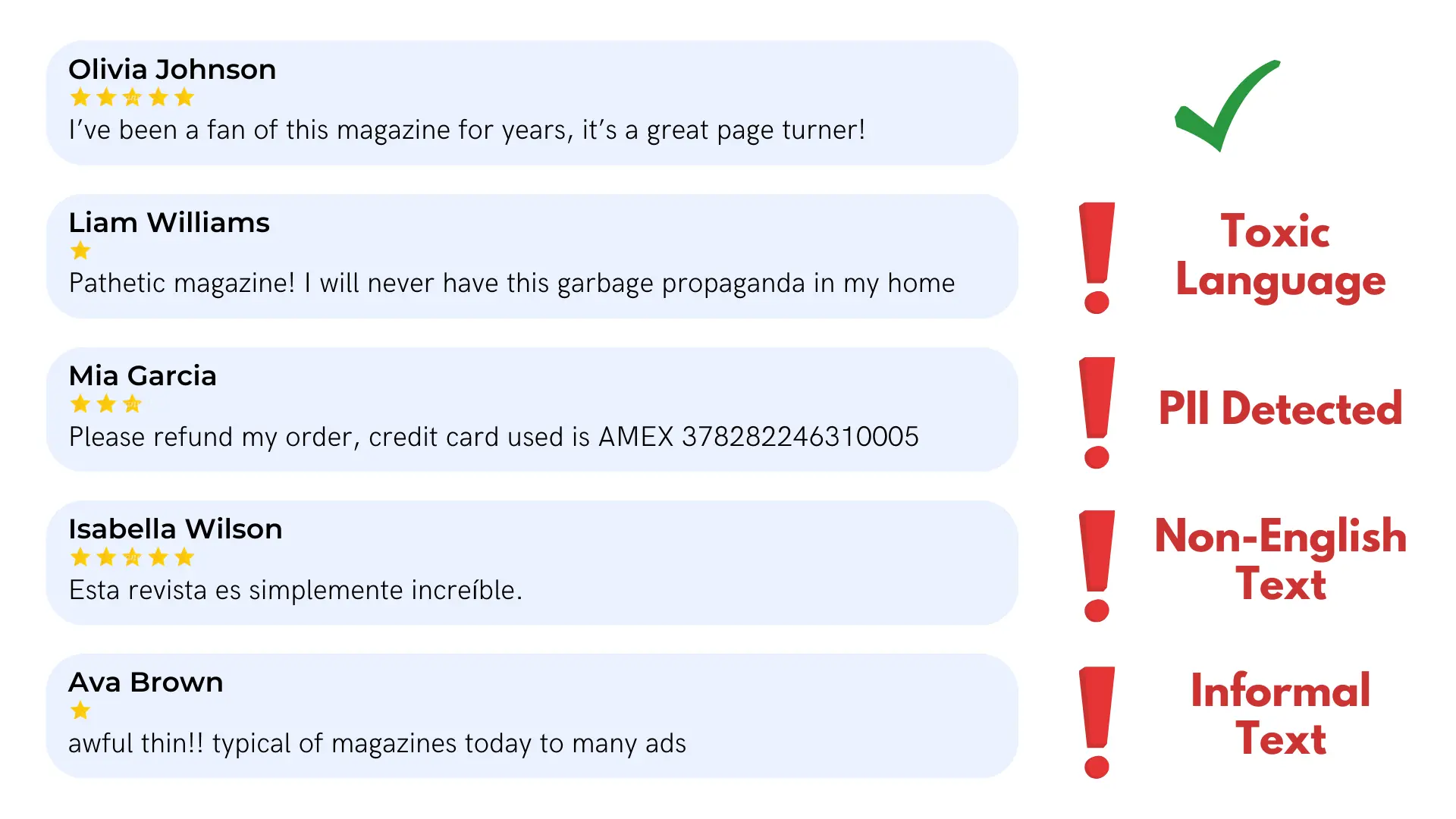
Details about all of the Cleanlab columns and their meanings can be found in this guide. Here we briefly showcase some of the Cleanlab columns that correspond to issues detected in our tutorial dataset. Since our dataset only has a text column, this tutorial focuses on issues specific to text fields such as the occurence of personally identifiable information (PII) and toxic language (see here for details).
The data points exhibiting each type of issue are indicated with boolean values in the respective is_<issue> column, and the severity of this issue in each data point is quantified in the respective <issue>_score column (on a scale of 0-1 with 1 indicating the most severe instances of the issue).
Let’s take a closer look at some issues flagged in our dataset. We merged the columns from our original dataset with the Cleanlab columns (metadata) produced by Cleanlab Studio:
# Load the dataset into a DataFrame
df = pd.read_csv(dataset_url)
# Combine the dataset with the cleanlab columns
combined_dataset_df = df.merge(cleanlab_columns_df, left_index=True, right_index=True)
Personally Identifiable Information (PII) is information that could be used to identify an individual or is otherwise sensitive. Exposing PII can compromise an individual’s security and hence should be safeguarded and anonymized/removed if discovered in publicly shared data.
Cleanlab’s PII detection also returns two extra columns, PII_items and PII_types, which list the specific PII detected in the text and its type. Possible types of PII that can be detected are detailed in the guide and scored according to how sensitive each type of information is.
Here are some examples of PII detected in the dataset:
PII_samples = combined_dataset_df.query("is_PII").sort_values("PII_score", ascending=False)
columns_to_display = ["tweet_id", "text", "PII_score", "is_PII", "PII_types", "PII_items"]
display(PII_samples.head(5)[columns_to_display])
| tweet_id | text | PII_score | is_PII | PII_types | PII_items | |
|---|---|---|---|---|---|---|
| 407 | 407 | @VirginAmerica FYI the info@virginamerica.com email address you say to contact in password reset emails doesn't exist. Emails bounce. | 0.5 | True | ["Twitter username", "email"] | ["@VirginAmerica", "info@virginamerica.com"] |
| 3377 | 3377 | @united Need to track lost luggage being shipped to me. Need ph # for human. Not automated 800-335-2247. | 0.5 | True | ["Twitter username", "phone number"] | ["@united", "800-335-2247"] |
| 742 | 742 | @united I send you an urgent message via eservice@united.com. BG0KWM Narayanan. Please respond ASAP. Also, NO local United Tel # @ KUL | 0.5 | True | ["Twitter username", "email"] | ["@united", "eservice@united.com"] |
| 3872 | 3872 | @united delayed about 8 hours because of missed connections due to mechanical issues on 1st flight. rebooked, but please call me 9148445695 | 0.5 | True | ["Twitter username", "phone number"] | ["@united", "9148445695"] |
| 960 | 960 | @united iCloud it is not there yet -- PLEASE HELP 917 703 1472 | 0.5 | True | ["Twitter username", "phone number"] | ["@united", "917 703 1472"] |
Text that contains toxic language may have elements of hateful speech and language others may find harmful or aggressive. Identifying toxic language is vital in tasks such as content moderation and LLM training/evaluation, where appropriate action should be taken to ensure safe platforms, chatbots, or other applications depending on this dataset.
Here are some examples in this dataset detected to contain toxic language:
toxic_samples = combined_dataset_df.query("is_toxic").sort_values("toxic_score", ascending=False)
columns_to_display = ["tweet_id", "text", "toxic_score", "is_toxic"]
display(toxic_samples.head(5)[columns_to_display])
| tweet_id | text | toxic_score | is_toxic | |
|---|---|---|---|---|
| 1197 | 1197 | @united you are the worst airline in the world! From your crap website to your worthless app to your Late Flight flight. You SUCK! Just shut down. | 0.911133 | True |
| 2122 | 2122 | @united I hope your corporate office is ready to deal with the rage created by your shitty service and bullshit pilots. #UnitedAirlinesSucks | 0.904297 | True |
| 2039 | 2039 | @united thanks for letting me sleep at DIA to ensure you ruin as much of my vacation as possible. Wait, no, fuck you. #unitedairlinessucks | 0.895996 | True |
| 2566 | 2566 | @united no. U guys suck. I'll never fly with u again. And ur supervisors suck too. | 0.893066 | True |
| 2185 | 2185 | @united please fire the captain of flight 6232 today. He single handedly ruined every passengers day by being a piece of shit. #unitedsucks | 0.888672 | True |
The above only showcases a small subset of all the different types of issues and metadata that Cleanlab Studio can provide for an unsupervised dataset with no labels. See this guide for the full set of issues that Cleanlab Studio audits your data for to help you prevent problems.
Using these results
Depending on your goal, you may want to take some steps to improve your dataset based on these results (i.e. by removing text detected to be low-quality or unsafe from your dataset). Alternatively, you might use the Cleanlab-generated metadata to better understand your dataset (e.g. understanding the prevalence of toxic language). Determining how to use the results of these analyses will vary based on your dataset and use case. Remember that Cleanlab Studio can also auto-detect low-quality or unsafe images as well. If you’d like to discuss your use case, please contact us.
