Trustworthy Retrieval-Augmented Generation with the Trustworthy Language Model

This tutorial demonstrates how to replace the Generator LLM in any RAG system with Cleanlab’s Trustworthy Language Model (TLM), to score the trustworthiness of answers and improve overall reliability. We recommend first completing the TLM quickstart tutorial.
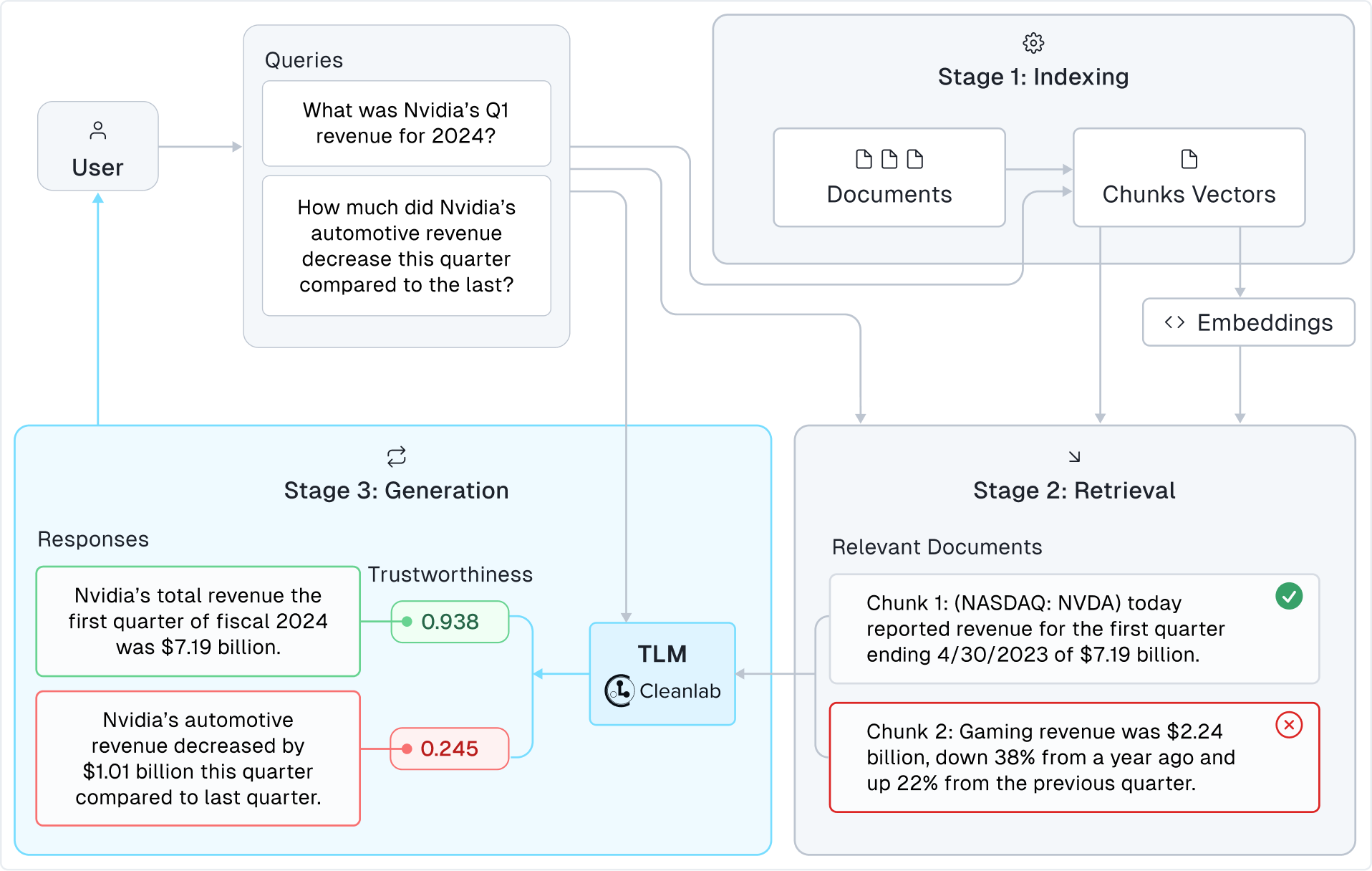
Retrieval-Augmented Generation (RAG) has become popular for building LLM-based Question-Answer systems in domains where LLMs alone suffer from: hallucination, knowledge gaps, and factual inaccuracies. However, RAG systems often still produce unreliable responses, because they depend on LLMs that are fundamentally unreliable. Cleanlab’s Trustworthy Language Model (TLM) offers a solution by providing trustworthiness scores to assess and improve response quality, independent of your RAG architecture or retrieval and indexing processes. To diagnose when RAG answers cannot be trusted, simply swap your existing LLM that is generating answers based on the retrieved context with TLM. This tutorial showcases this for a standard RAG system, based off a tutorial in the popular LlamaIndex framework. Here we merely replace the LLM used in the LlamaIndex tutorial with TLM, and showcase some of the benefits. TLM can be similarly inserted into any other RAG framework.
Setup
RAG is all about connecting LLMs to data, to better inform their answers. This tutorial uses Nvidia’s Q1 FY2024 earnings report as an example dataset.
Use the following commands to download the data (earnings report) and store it in a directory named data/.
wget -nc 'https://cleanlab-public.s3.amazonaws.com/Datasets/NVIDIA_Financial_Results_Q1_FY2024.md'
mkdir -p ./data
mv NVIDIA_Financial_Results_Q1_FY2024.md data/
Let’s next install required dependencies.
%pip install -U cleanlab-studio llama-index llama-index-embeddings-huggingface
We then initialize our Cleanlab client. You can get your Cleanlab API key here: https://app.cleanlab.ai/account after creating an account. For detailed instructions, refer to this guide.
from cleanlab_studio import Studio
studio = Studio("<insert your API key>")
Integrate TLM with LlamaIndex
TLM not only provides a response but also includes a trustworthiness score indicating the confidence that this response is good/accurate. Here we initialize a TLM object with default settings. You can achieve better results by playing with the TLM configurations outlined in the Advanced section of the TLM quickstart tutorial.
tlm = studio.TLM()
Our RAG pipeline closely follows the LlamaIndex guide on Using a custom LLM Model. LLamaIndex’s CustomLLM class exposes two methods, complete() and stream_complete(), for returning the LLM response. Additionally, it provides a metadata property to specify LLM details such as context window, number of output tokens, and name of your LLM.
Here we create a TLMWrapper subclass of CustomLLM that uses our TLM object instantiated above.
from typing import Any, Dict
import json
# Import LlamaIndex dependencies
from llama_index.core.base.llms.types import (
CompletionResponse,
CompletionResponseGen,
LLMMetadata,
)
from llama_index.core.llms.callbacks import llm_completion_callback
from llama_index.core.llms.custom import CustomLLM
from llama_index.core import Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
class TLMWrapper(CustomLLM):
context_window: int = 16000
num_output: int = 256
model_name: str = "TLM"
@property
def metadata(self) -> LLMMetadata:
"""Get LLM metadata."""
return LLMMetadata(
context_window=self.context_window,
num_output=self.num_output,
model_name=self.model_name,
)
@llm_completion_callback()
def complete(self, prompt: str, **kwargs: Any) -> CompletionResponse:
# Prompt tlm for a response and trustworthiness score
response: Dict[str, str] = tlm.prompt(prompt)
output = json.dumps(response)
return CompletionResponse(text=output)
@llm_completion_callback()
def stream_complete(self, prompt: str, **kwargs: Any) -> CompletionResponseGen:
# Prompt tlm for a response and trustworthiness score
response = tlm.prompt(prompt)
output = json.dumps(response)
# Stream the output
output_str = ""
for token in output:
output_str += token
yield CompletionResponse(text=output_str, delta=token)
Build a RAG pipeline with TLM
Now let’s integrate our TLM-based CustomLLM into a RAG pipeline.
Settings.llm = TLMWrapper()
Specify Embedding Model
RAG uses an embedding model to match queries against document chunks to retrieve the most relevant data. Here we opt for a no-cost, local embedding model from Hugging Face. You can use any other embedding model by referring to this LlamaIndex guide.
Settings.embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-en-v1.5")
Load Data and Create Index + Query Engine
Let’s create an index from the documents stored in the data directory. The system can index multiple files within the same folder, although for this tutorial, we’ll use just one document. We stick with the default index from LlamaIndex for this tutorial.
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
The generated index is used to power a query engine over the data.
query_engine = index.as_query_engine()
Note that TLM is agnostic to the index and the query engine used for RAG, and is compatible with any choices you make for these components of your system.
Answering queries with our RAG system
Let’s try out our RAG pipeline based on TLM. Here we pose questions with differing levels of complexity.
Optional: Define `display_response` helper function (click to expand)
# This method presents formatted responses from our TLM-based RAG pipeline. It parses the output to display both the response itself and the corresponding trustworthiness score.
def display_response(response):
response_str = response.response
output_dict = json.loads(response_str)
print(f"Response: {output_dict['response']}")
print(f"Trustworthiness score: {round(output_dict['trustworthiness_score'], 2)}")
Easy Questions
We first pose straightforward questions that can be directly answered by the provided data and can be easily located within a few lines of text.
response = query_engine.query(
"What was NVIDIA's total revenue in the first quarter of fiscal 2024?"
)
display_response(response)
response = query_engine.query(
"What was the percentage increase in NVIDIA's GAAP net income from Q4 FY23 to Q1 FY24?"
)
display_response(response)
response = query_engine.query(
"What significant transitions did Jensen Huang, NVIDIA's CEO, comment on?"
)
display_response(response)
TLM returns high trustworthiness scores for these responses, indicating high confidence they are accurate. After doing a quick fact-check (reviewing the original earnings report), we can confirm that TLM indeed accurately answered these questions. In case you’re curious, here are relevant excerpts from the data context for these questions:
NVIDIA (NASDAQ: NVDA) today reported revenue for the first quarter ended April 30, 2023, of $7.19 billion, …
GAAP earnings per diluted share for the quarter were $0.82, up 28% from a year ago and up 44% from the previous quarter.
Jensen Huang, founder and CEO of NVIDIA, commented on the significant transitions the computer industry is undergoing, particularly accelerated computing and generative AI, …
Questions without Available Context
Now let’s see how TLM responds to queries that cannot be answered using the provided data.
response = query_engine.query(
"How does the report explain why NVIDIA's Gaming revenue decreased year over year?"
)
display_response(response)
response = query_engine.query(
"How does NVIDIA's dividend payout for this quarter compare to the industry average?",
)
display_response(response)
We observe that TLM demonstrates the ability to recognize the limitations of the available information. It refrains from generating speculative responses or hallucinations, thereby maintaining the reliability of the question-answering system. This behavior showcases an understanding of the boundaries of the context and prioritizes accuracy over conjecture. The lower TLM trustworthiness score indicate a bit more uncertainty about the response, which aligns with the lack of information available.
Challenging Questions
Let’s see how our RAG system responds to harder questions, some of which may be misleading.
response = query_engine.query(
"How much did Nvidia's revenue decrease this quarter compared to last quarter, in dollars?"
)
display_response(response)
response = query_engine.query(
"There were 20 companies mentioned in the report. List all of them.",
)
display_response(response)
TLM automatically alerts us that these answers are unreliable, by the low trustworthiness score. RAG systems with TLM help you properly exercise caution when you see low trustworthiness scores. Here are the correct answers to the aforementioned questions:
NVIDIA’s revenue increased by $1.14 billion this quarter compared to last quarter.
There are only 10 companies mentioned in total.
Comparing TLM Trustworthiness Scores vs. OpenAI GPT-4 Logprobs
One approach that OpenAI recommends to rate confidence in a response is via the average log probabilities of the tokens output by the LLM neural network model.
We built the same LlamaIndex RAG system using GPT-4 in place of TLM via this code. We then asked the GPT-4 RAG system the following query and report its response and the associated average token-probability from this model. We also repeated this with our TLM RAG system (both systems have the same context).
| Query | GPT-4 Response | GPT-4 Average Token Probability | TLM Response | TLM Trustworthiness Score |
|---|---|---|---|---|
| True or False: Nvidia’s Professional Visualization division is performing better than their Gaming division in terms of percent change in revenue compared to the previous quarter. | False | 99.19% | False | 0.55 |
This is an example of a difficult question. Gaming increased by 22% compared to the previous quarter whereas Visualization increased by 31%, so the correct answer is True. Both TLM and GPT-4 arrived at the same incorrect answer. While the GPT-4 probabilities are misleading, suggesting a confident answer, the TLM trustworthiness score is much lower, correcting suggesting that this answer is untrustworthy.
Relying solely on token probabilities only captures aleatoric uncertainty in the ML model, whereas TLM trustworthiness scores capture all forms of uncertainty to better flag unreliable answers. Average token probabilities also tend to be highly influenced by the specific syntax and words used to express the answer, whereas TLM quantifies our confidence that the answer is good overall.
With TLM, you can easily increase trust in any RAG system!