Data Curation with Train vs Test Splits
In typical Machine Learning projects, we split our dataset into training data for fitting models and test data to evaluate model performance. For noisy real-world datasets, detecting/correcting errors in the training data is important to train robust models, but it’s less recognized that the test set can also be noisy. For accurate model evaluation, it is vital to find and fix issues in the test data as well. Some evaluation metrics are particularly sensitive to outliers and noisy labels. This tutorial demonstrates a way to use Cleanlab Studio to curate cleaner versions of your training and test data, ensuring robust model training and reliable performance evaluation.
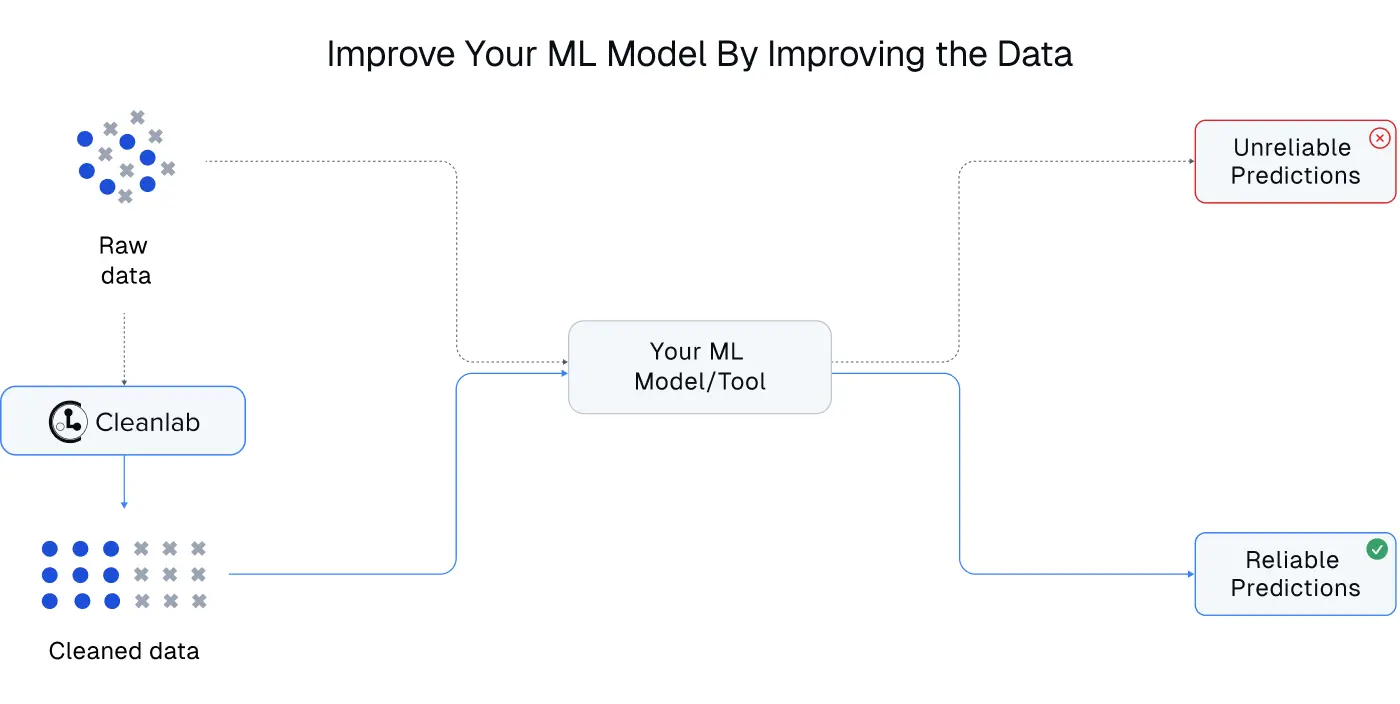
Here’s how we recommend handling noisy training and test data with Cleanlab Studio:
- First focus on detecting issues in the test data. For the best detection, we recommend that you merge your training and test data and then run a Cleanlab Studio Project (which will benefit from more data) – but only focus on project results for the test data.
- Manually review/correct Cleanlab-detected issues in your test data. To avoid bias, we caution against automated correction of test data. Instead, test data changes should be individually verified to ensure they will lead to more accurate model evaluation.
- Run a separate Cleanlab Studio project on the training data alone to detect issues in the training data (without any test set information leakage).
- Optionally, use automated Cleanlab suggestions to algorithmically refine the training data (or manually review/correct Cleanlab-detected issues in your training data).
- Estimate the final model’s performance on the cleaned test data. Do not compare the performance of different ML models estimated across different versions of your test data. These estimates are incomparable.
Even if you effectively clean noisy training data, the resulting model may not appear to be better, unless you properly clean the noisy test data as well. Thus we recommend curating clean test data to first establish reliable model evaluation, before curating the training data for improved model training. Automated data correction of test data may bias model evaluation, so we recommend that you manually correct test data issues reported by Cleanlab. You can rely on automated correction of training data once you have trustworthy model evaluation in place.
Consider this tutorial as a blueprint for using Cleanlab Studio in ML projects spanning various data modalities and tasks. Let’s get started!
Load the data
First install and import required dependencies for this tutorial.
pip install xgboost scikit-learn pandas
from xgboost import XGBClassifier
from sklearn import preprocessing
from sklearn.metrics import accuracy_score
import pandas as pd
This tutorial demonstrates our strategy on a tabular dataset of student grades which has some data entry errors. The same idea can be applied to any dataset, whether structured or unstructured (images/text). Our student grades dataset records three exam scores (numerical features), a written note (a categorical feature with missing values), and a potentially erroneous letter grade (categorical label to predict) for each student. Let’s load the training data for fitting our ML model and test data for model evaluation.
df_train = pd.read_csv(
"https://cleanlab-public.s3.amazonaws.com/Datasets/student-grades/train.csv"
)
df_test = pd.read_csv(
"https://cleanlab-public.s3.amazonaws.com/Datasets/student-grades/test.csv"
)
df_train.head()
| stud_ID | exam_1 | exam_2 | exam_3 | notes | noisy_letter_grade | |
|---|---|---|---|---|---|---|
| 0 | 37fd76 | 99 | 59 | 70 | missed class frequently -10 | D |
| 1 | 018bff | 94 | 41 | 91 | great participation +10 | B |
| 2 | b3c9a0 | 91 | 74 | 88 | NaN | B |
| 3 | 076d92 | 0 | 79 | 65 | cheated on exam, gets 0pts | F |
| 4 | 68827d | 91 | 98 | 75 | missed class frequently -10 | C |
Curate clean test data
We first demonstrate the process of improving the quality of noisy test data to facilitate more accurate model evaluation.
Merge train and test data
We merge our training and test data into a larger dataset that will better enable Cleanlab Studio to detect issues (remember Cleanlab’s AI is trained on the provided data and performs better with more data). In the merged dataset, we add a column is_train to distinguish between samples from the training vs test set. We’ll use this column to focus on reviewing issues detected in the test data only.
df_train_c = df_train.copy()
df_test_c = df_test.copy()
df_train_c["is_train"] = True
df_test_c["is_train"] = False
df_full = pd.concat([df_train_c, df_test_c]).reset_index(drop=True)
df_full.head()
| stud_ID | exam_1 | exam_2 | exam_3 | notes | noisy_letter_grade | is_train | |
|---|---|---|---|---|---|---|---|
| 0 | 37fd76 | 99 | 59 | 70 | missed class frequently -10 | D | True |
| 1 | 018bff | 94 | 41 | 91 | great participation +10 | B | True |
| 2 | b3c9a0 | 91 | 74 | 88 | NaN | B | True |
| 3 | 076d92 | 0 | 79 | 65 | cheated on exam, gets 0pts | F | True |
| 4 | 68827d | 91 | 98 | 75 | missed class frequently -10 | C | True |
We save the merged dataset as a CSV file.
df_full.to_csv("full.csv", index=None)
Create a Project
Let’s launch a project in Cleanlab Studio to auto-detect issues in this dataset. Below is a video demonstrating how to load your dataset and run a project to analyze it. When loading the data, you can optionally override the inferred column types for your dataset (for our tutorial dataset, we specify stud_ID as an identifier column and the exam columns as numeric). After loading the data, we create a Cleanlab Studio Project. During project setup, we specify the label column as noisy_letter_grade, and exam_1, exam_2, exam_3, and notes as predictive columns used by Cleanlab’s AI to estimate label issues. Note we ignore the ID column and the is_train boolean that we added.
Manually review and address issues in test data
The Project will take a while for Cleanlab’s AI to train on your data and analyze it. When finished running, it will be marked Ready for Review and you’ll get an email. In the project, you can quickly review the issues detected in your data. We focus solely on the test data by setting the filter is_train=True and then manually review individual test data examples.
It is important not to auto-correct training data at this point in order to prevent test set information leakage. Beware that automated curation of the test data can introduce unforeseen biases in model evaluation. Thus, we recommend carefully reviewing the test data detected to have issues and only making corrections in cases where you are confident the changed test data will provide more reliable model evaluation. For instance, do not re-label a test data point unless you are certain the new label is right and do not exclude test data unless you are certain it is unrepresentative of the setting in which the model will be deployed.
The video below demonstrates how this manual data correction process might be conducted for our tutorial dataset. During this process, we re-label certain test data points that Cleanlab Studio correctly identified as mislabeled. To expedite this data correction process, utilize the Analytics tab to review similar types of mislabeled data points. For example, all of the students annotated as F’s which Cleanlab Studio estimates should have been annotated as A’s instead. After addressing Label Issues detected by Cleanlab, you might also review examples flagged as Ambiguous or Outliers. Once we have addressed the detected issues in our test data, we export the cleaned dataset with Cleanlab-generated metadata columns back into CSV format.
Construct a clean version of the test data
To construct our cleaned test dataset, we filter out the train rows and only keep the relevant columns.
# You should generally create your own cleanlab_columns_full.csv file by curating your dataset in Cleanlab Studio and exporting it.
# For this tutorial, you can fetch the export file that we used here: https://cleanlab-public.s3.amazonaws.com/Datasets/student-grades/cleanlab_columns_full.csv
cleanlab_columns = pd.read_csv("cleanlab_columns_full.csv")
df_test_cleaned = cleanlab_columns[cleanlab_columns["is_train"] == False].copy()
The cleanlab_corrected_label column contains corrected labels for rows that were mislabeled and corrected in the Cleanlab Studio interface. For rows without any issues, we backfill this column with the original labels.
df_test_cleaned["cleanlab_corrected_label"] = df_test_cleaned[
"cleanlab_corrected_label"
].fillna(df_test_cleaned["noisy_letter_grade"])
df_test_cleaned = df_test_cleaned[
[
"stud_ID",
"exam_1",
"exam_2",
"exam_3",
"notes",
"cleanlab_corrected_label",
]
]
Our cleaned test dataset is shown below. By correcting badly annotated data, we can more reliably evaluate any ML models on this test set (and determine important decisions like when to deploy an updated model). Clean test labels are particularly important for sensitive evaluation metrics like precision/recall with imbalanced class frequencies.
df_test_cleaned.head()
| stud_ID | exam_1 | exam_2 | exam_3 | notes | cleanlab_corrected_label | |
|---|---|---|---|---|---|---|
| 1 | 0094d7 | 94 | 91 | 93 | great participation +10 | A |
| 9 | 01dd6e | 92 | 99 | 87 | missed homework frequently -10 | B |
| 12 | 02c7df | 90 | 73 | 91 | NaN | B |
| 14 | 03d6b7 | 93 | 47 | 79 | great participation +10 | B |
| 15 | 042686 | 87 | 74 | 95 | missed class frequently -10 | C |
Evaluate model performance on clean test data
The data curation principles demonstrated here can be applied to enhance model evaluation and training, irrespective of the specific type of ML model you’re using. Here we choose an XGBoost model, an popular implementation of gradient-boosting decision trees (GBDT) for tabular data. XGBoost (>v1.6) is able to handle mixed data types (numerical and categorical) by setting enable_categorical=True, thereby simplifying the modeling process.
Preprocess the dataset
Before training an XGBoost model, we preprocess the notes and noisy_letter_grade columns into categorical columns.
# Create label encoders for the grade and notes columns
grade_le = preprocessing.LabelEncoder()
notes_le = preprocessing.LabelEncoder()
# Prepare the feature columns
train_features = df_train.drop(["stud_ID", "noisy_letter_grade"], axis=1).copy()
train_features["notes"] = notes_le.fit_transform(train_features["notes"])
train_features["notes"] = train_features["notes"].astype("category")
# Encode the label column into a cateogorical feature
train_labels = grade_le.fit_transform(df_train["noisy_letter_grade"].copy())
Let’s view the training set features after preprocessing.
train_features.head()
| exam_1 | exam_2 | exam_3 | notes | |
|---|---|---|---|---|
| 0 | 99 | 59 | 70 | 3 |
| 1 | 94 | 41 | 91 | 2 |
| 2 | 91 | 74 | 88 | 5 |
| 3 | 0 | 79 | 65 | 0 |
| 4 | 91 | 98 | 75 | 3 |
Next we repeat the same preprocessing steps for our clean test data.
test_features = df_test_cleaned.drop(
["stud_ID", "cleanlab_corrected_label"], axis=1
).copy()
test_features["notes"] = notes_le.transform(test_features["notes"])
test_features["notes"] = test_features["notes"].astype("category")
test_labels = grade_le.transform(df_test_cleaned["cleanlab_corrected_label"].copy())
Train model with original (noisy) training data
model = XGBClassifier(tree_method="hist", enable_categorical=True)
model.fit(train_features, train_labels)
Using clean test data to evaluate the performance of model trained on noisy training data
Although curating clean test data does not directly help train a better ML model, more reliable model evaluation can improve our overall ML project. For instance, clean test data can enable better informed decisions regarding when to deploy a model and better model/hyperparameter selection.
preds = model.predict(test_features)
acc_original = accuracy_score(test_labels, preds)
print(
f"Accuracy of model fit to noisy training data, measured on clean test data: {round(acc_original*100,1)}%"
)
Curate clean training data
To actually improve our model, we’ll want to improve the quality of our noisy training data. We follow the same steps as before, but this time, we only use the train data to detect issues. This prevents information from the test data from potentially influencing the training data (and subsequently trained ML models), which is critical for unbiased model evaluation.
Here we simply load the train.csv file into Cleanlab Studio and create a project as demonstrated previously. For the training data, feel free to rely on Cleanlab’s automated suggestions to more efficiently fix issues in the dataset. After curating clean training data, we export it in the same way as before.
The video below demonstrates how this process might look for our tutorial training data. Here Cleanlab Studio has identified a large number of mislabeled examples, which can be time-consuming to address individually. To expedite the data correction process for our training set, we use the Analytics tab to pinpoint subsets of the data suitable for automated correction. In this specific video, we automatically correct all data points for which Cleanlab Studio estimated a grade F was mislabeled as a grade A. Subsequently, we individually examine examples flagged as Ambiguous. We exclude some particularly confusing examples that might hamper our model’s learning. Excluding and relabeling data can be done more freely/automatically in the training data, because as long as we have reliable model evaluation in place, we will see when we have poorly altered the training data and are producing worse models. Cleanlab’s automated suggestions can be useful for correcting many data points at once in large training datasets.
# You should generally create your own cleanlab_columns_full.csv file by curating your dataset in Cleanlab Studio and exporting it.
# For this tutorial, you can fetch the export file that we used here: https://cleanlab-public.s3.amazonaws.com/Datasets/student-grades/cleanlab_columns.csv
df_train_cleaned = pd.read_csv("cleanlab_columns.csv")
To construct our clean training set, we again backfill the cleanlab_corrected_label column with the original labels for training rows where no issues were detected.
df_train_cleaned["cleanlab_corrected_label"] = df_train_cleaned[
"cleanlab_corrected_label"
].fillna(df_train_cleaned["noisy_letter_grade"])
df_train_cleaned = df_train_cleaned[
[
"stud_ID",
"exam_1",
"exam_2",
"exam_3",
"notes",
"cleanlab_corrected_label",
]
]
df_train_cleaned.head()
| stud_ID | exam_1 | exam_2 | exam_3 | notes | cleanlab_corrected_label | |
|---|---|---|---|---|---|---|
| 0 | 5686d8 | 65 | 0 | 57 | cheated on exam, gets 0pts | F |
| 1 | 6fd557 | 97 | 98 | 92 | NaN | A |
| 2 | 96968e | 90 | 84 | 97 | great participation +10 | A |
| 3 | ccd8c8 | 53 | 0 | 76 | cheated on exam, gets 0pts | F |
| 4 | 50bebd | 54 | 80 | 81 | NaN | A |
Preprocess the clean training data
cleaned_train_features = df_train_cleaned.drop(
["stud_ID", "cleanlab_corrected_label"], axis=1
).copy()
cleaned_train_features["notes"] = notes_le.transform(cleaned_train_features["notes"])
cleaned_train_features["notes"] = cleaned_train_features["notes"].astype("category")
cleaned_train_labels = grade_le.transform(
df_train_cleaned["cleanlab_corrected_label"].copy()
)
Train model with clean training data
cleaned_model = XGBClassifier(tree_method="hist", enable_categorical=True)
cleaned_model.fit(cleaned_train_features, cleaned_train_labels)
Using clean test data to evaluate the performance of model trained on the clean training data
preds = cleaned_model.predict(test_features)
acc_original = accuracy_score(test_labels, preds)
print(
f"Accuracy of model fit to clean training data, measured on clean test data: {round(acc_original*100,1)}%"
)
We see that for our tutorial dataset, finding and fixing issues in the training data significantly improved ML model performance. The automated corrections suggested by Cleanlab Studio have allowed us to easily improve our ML model. Furthermore, such training data corrections should directly improve various different types of ML models in case we decide to switch the model later on.
Note: We are reliably evaluating performance here based on clean test data. If you only make training data improvements but have a noisy test set, you may fail to realize when you have actually improved your model. In fact, only correcting the training data may make model performance appear go down on the original test data in datasets with systematic errors (even if the training data corrections were actually beneficial, they may introduce a distribution shift in such cases).
Review performance on noisy test data
For completeness, let’s see what the above model performances would be estimated as if we had used original (noisy) test data instead of our cleaned test data.
We first preprocess the features of the original test data.
noisy_test_features = df_test.drop(
[
"stud_ID",
"noisy_letter_grade",
],
axis=1,
).copy()
noisy_test_features["notes"] = notes_le.transform(noisy_test_features["notes"])
noisy_test_features["notes"] = noisy_test_features["notes"].astype("category")
noisy_test_labels = grade_le.transform(df_test["noisy_letter_grade"].copy())
Using noisy test data to evaluate the performance of model trained on noisy training data
preds = model.predict(noisy_test_features)
acc_original = accuracy_score(noisy_test_labels, preds)
print(
f"Accuracy of model fit to noisy training data, measured on noisy test data: {round(acc_original*100,1)}%"
)
Using noisy test data to evaluate the performance of model trained on clean training data
preds = cleaned_model.predict(noisy_test_features)
acc_original = accuracy_score(noisy_test_labels, preds)
print(
f"Accuracy of model fit to clean training data, measured on noisy test data: {round(acc_original*100,1)}%"
)
It’s evident how curating clean test data can significantly affect model performance evaluations. Relying on noisy test data can be misleading and lead to bad decisions.
We again emphasize that even if you effectively clean noisy training data, the resulting model may not appear to be better, unless you properly clean the noisy test data as well. This tutorial demonstrated a strategy to curate clean test data for reliable model evaluation as well as clean training data for improved model training. Remember that automated data correction of test data may bias model evaluation, so manually correct test data issues reported by Cleanlab. You can rely on automated correction of training data once you have trustworthy model evaluation in place, since then you can reliably measure the resulting effect on models fit to the altered training data.
If you have any questions, feel free to ask in our Slack community.