Reliable Zero-Shot Classification with the Trustworthy Language Model

In zero-shot (or few-shot) classification, we use a Foundation model to classify input data into predefined categories (aka. classes), without having to train this model on a manually annotated dataset. This requires much less work than training/deploying classical machine learning models (no data preparation/labeling required either) and can generalize better across evolving environments. The problem with classification with pretrained LLMs is we don’t know which LLM classifications we can trust. LLMs are prone to hallucination and will often predict a category even when their world knowledge does not suffice to justify this prediction.
This tutorial demonstrates how you can easily replace any LLM with Cleanlab’s Trustworthy Language Model (TLM) to:
- Score the trustworthiness of each classification
- Automatically boost classification accuracy
Use TLM to ensure reliable classification where you know which model predictions cannot be trusted.
Setup
This tutorial requires a TLM API key. Get one here.
The Python client package can be installed using pip:
%pip install cleanlab-tlm
# Set your API key
import os
os.environ["CLEANLAB_TLM_API_KEY"] = "<API key>" # Get your free API key from: https://tlm.cleanlab.ai/
import pandas as pd
from cleanlab_tlm import TLM
Let’s load an example classification dataset. Here we consider legal documents from the “US” Jurisdiction of the Multi_Legal_Pile. We aim to classify each document into one of three categories: [caselaw, contracts, legislation].
We’ll prompt our TLM to categorize each document and record its response and associated trustworthiness score. You can use the ideas from this tutorial to improve LLMs for any other classification task!
First download our dataset and load it into a DataFrame.
wget -nc 'https://cleanlab-public.s3.amazonaws.com/Datasets/zero_shot_classification.csv'
df = pd.read_csv('zero_shot_classification.csv')
df.head(2)
| index | text | |
|---|---|---|
| 0 | 0 | Probl2B\n0/NV Form\nRev. June 2014\n\n\n\n ... |
| 1 | 1 | UNITED STATES DI... |
Perform Zero Shot Classification with TLM
Let’s initalize a TLM object using gpt-4o as the underlying base model. Advanced configuration options exist that can produce improved classification accuracy or trustworthiness scoring.
MODEL = "gpt-4o" # which base LLM should TLM utilize
tlm = TLM(options={"model": MODEL}) # to boost accuracy, consider adding: `num_candidate_responses=4` (any number larger than 1, higher number = more accurate response)
Next, let’s define a prompt template to instruct TLM on how to classify each document. Write your prompt just as you would with any other LLM when adapting it for zero-shot classification. A good prompt template might contain all the possible categories a document can be classified as, as well as formatting instructions for the LLM response. Of course the text of the document is crucial.
'You are an expert Legal Document Auditor. Classify the following document into a single category that best represents it. The categories are: {categories}. In your response, first provide a brief explanation as to why the document belongs to a specific category and then on a new line write "Category: <category document belongs to>". \nDocument: {document}'
If you have a couple labeled examples from different classes, you may be able to get better LLM predictions via few-shot prompting (where these examples + their classes are embedded within the prompt). Here we’ll stick with zero-shot classification for simplicity, but note that TLM can also be used for few-shot classification just like any other LLM.
Let’s apply the above prompt template to all documents in our dataset and form the list of prompts we want to run. For one arbitrary document, we print the actual corresponding prompt fed into TLM below.
zero_shot_prompt_template = 'You are an expert Legal Document Auditor. Classify the following document into a single category that best represents it. The categories are: {categories}. In your response, first provide a brief explanation as to why the document belongs to a specific category and then on a new line write "Cateogry: <category document belongs to>". \nDocument: {document}'
categories = ['caselaw', 'contracts', 'legislation']
string_categories = str(categories).replace('\'', '')
# Create a DataFrame to store results and apply the prompt template to all examples
results_df = df.copy()
results_df['prompt'] = results_df['text'].apply(lambda x: zero_shot_prompt_template.format(categories=string_categories, document=x))
print(f"{results_df.at[7, 'prompt']}")
Now we prompt TLM and save the output responses and their associated trustworthiness scores for all examples. We use the constrain_outputs parameter to ensure that TLM always outputs one of the valid categories. The last entry in the constrain_outputs list is treated as the category to fall back to whenever the LLM fails to choose one of the categories (so optionally order your categories such that the last one is what you would choose in cases of high uncertainty).
outputs = tlm.prompt(results_df['prompt'].to_list(), constrain_outputs=categories + ["other"])
results_df[["predicted_category","trustworthiness_score"]] = pd.DataFrame(outputs)
Optional: Define helper methods to better display results.
def display_result(results_df: pd.DataFrame, index: int):
"""Displays TLM result for the example from the dataset whose `index` is provided."""
print(f"TLM predicted category: {results_df.iloc[index].predicted_category}")
print(f"TLM trustworthiness score: {results_df.iloc[index].trustworthiness_score}\n")
print(results_df.iloc[index].text)
Analyze Classification Results
Let’s first inspect the most trustworthy predictions from our model. We sort the TLM outputs over our documents to see which predictions received the highest trustworthiness scores.
results_df = results_df.sort_values(by='trustworthiness_score', ascending=False)
display_result(results_df, index=0)
A document about “SENIOR MANAGEMENT BONUS PLAN, Effective January 1, 2012” is clearly a contract, so it makes sense that TLM classifies it into the “contracts” category with high trustworthiness.
display_result(results_df, index=1)
Another document titled as “AMENDMENT No. 4 TO EMPLOYMENT AGREEMENT” is clearly a contract, so it makes sense that TLM classifies it into the “contracts” category with high trustworthiness.
display_result(results_df, index=3)
This document about “DEPARTMENT OF DEFENSE, GENERAL SERVICES ADMINISTRATION, NATIONAL AERONAUTICS AND SPACE ADMINISTRATION” clearly belongs to some legislation measure, so it makes sense that TLM classifies it into the “legislation” category with high trustworthiness.
Least Trustworthy Predictions
Now let’s see which classifications predicted by the model are least trustworthy. We sort the data by trustworthiness scores in the opposite order to see which predictions received the lowest scores. Observe how model classifications with the lowest trustworthiness scores are often incorrect, corresponding to examples with vague/irrelevant text or documents possibly belonging to more than one category.
results_df = results_df.sort_values(by='trustworthiness_score')
display_result(results_df, index=0)
This example is clearly not legislation nor any other category since the document is just a list of JPG file names. TLM’s low trust score alerts us that this example cannot be confidently classified.
How to use Trustworthiness Scores?
If you have time, your team can manually review/correct the least trustworthy LLM classifications. Inspecting the least trustworthy examples also helps you discover how to improve your prompt (e.g. how to handle edge-cases, which few-shot examples to provide, etc).
Alternatively, you can determine a trustworthiness threshold below which LLM predictions seem too unreliable, and abstain from classifying such cases. The overall magnitude/range of the trustworthiness scores may differ between datasets, so we recommend selecting any thresholds to be application-specific. First consider the relative trustworthiness levels between different data points before considering the overall magnitude of these scores for individual data points.
Measuring Classification Accuracy with Ground Truth Labels
Our example dataset happens to have labels for each document, so we can load them in to assess the accuracy of our model predictions. We’ll study the impact on accuracy as we abstain from making predictions for examples receiving lower trustworthiness scores.
wget -nc 'https://cleanlab-public.s3.amazonaws.com/Datasets/zero_shot_classification_labels.csv'
df_ground_truth = pd.read_csv('zero_shot_classification_labels.csv')
df = pd.merge(results_df, df_ground_truth, on=['index'], how='outer')
df['is_correct'] = df['type'] == df['predicted_category']
df.head()
| index | text | prompt | predicted_category | trustworthiness_score | type | is_correct | |
|---|---|---|---|---|---|---|---|
| 0 | 0 | Probl2B\n0/NV Form\nRev. June 2014\n\n\n\n ... | You are an expert Legal Document Auditor. Clas... | caselaw | 0.778880 | caselaw | True |
| 1 | 1 | UNITED STATES DI... | You are an expert Legal Document Auditor. Clas... | caselaw | 0.809627 | caselaw | True |
| 2 | 2 | \n \n FEDERAL COMMUNICATIONS COMMI... | You are an expert Legal Document Auditor. Clas... | legislation | 0.923114 | legislation | True |
| 3 | 3 | \n \n DEPARTMENT OF COMMERCE\n ... | You are an expert Legal Document Auditor. Clas... | legislation | 0.767369 | legislation | True |
| 4 | 4 | EXHIBIT 10.14\n\nAMENDMENT NO. 1 TO\n\nCHANGE ... | You are an expert Legal Document Auditor. Clas... | contracts | 0.843782 | contracts | True |
print('TLM zero-shot classification accuracy over all documents: ', df['is_correct'].sum() / df.shape[0])
Next we plot the accuracy of the TLM-predicted categories (computed with respect to ground-truth labels). Here we assume predictions from TLM are only considered for the subset of data where the trustworthiness score is sufficiently high, so accuracy is only computed over this data subset (the remaining data could be manually reviewed by humans). Our plot depicts the resulting accuracy across different choices of the trustworthiness score threshold, which determine how much of the data gets auto-labeled by the LLM (see X-axis below).
Optional: Plotting code
import numpy as np
import matplotlib.pyplot as plt
# Calculate the number of examples, percentage of data, and accuracy of TLM's predictions for each threshold value
threshold_analysis = pd.DataFrame([{
"threshold": t,
"num_examples": len(filtered := df[df["trustworthiness_score"] > t]),
"percent_data": len(filtered) / len(df) * 100,
"accuracy": np.mean(filtered["predicted_category"] == filtered["type"]) * 100
} for t in np.arange(0, 1.0, 0.01)]).round(2)
# Plot the accuracy of TLM's predictions and percentage of data for each trustworthiness score threshold value
def create_enhanced_line_plot(threshold_analysis):
plt.figure(figsize=(8.25, 6.6))
points = plt.scatter(threshold_analysis['percent_data'], threshold_analysis['accuracy'],
c=threshold_analysis['threshold'], cmap='viridis', s=40) # Increased marker size
plt.plot(threshold_analysis['percent_data'], threshold_analysis['accuracy'],
alpha=0.3, color='gray', zorder=1, linewidth=2) # Increased line width
plt.colorbar(points).set_label('trustworthiness Threshold', fontsize=14) # Increased font size
plt.grid(True, alpha=0.3)
plt.xlabel('Percentage of Data Included', fontsize=14) # Increased font size
plt.ylabel('Classification Accuracy', fontsize=14) # Increased font size
plt.title('Accuracy vs Auto Classification Threshold', fontsize=16) # Increased font size
plt.xticks(fontsize=14) # Increased tick label size
plt.yticks(fontsize=14) # Increased tick label size
plt.xlim(85, 100)
plt.tight_layout()
return plt.gcf()
# Apply the function to your data
fig = create_enhanced_line_plot(threshold_analysis)
plt.show()
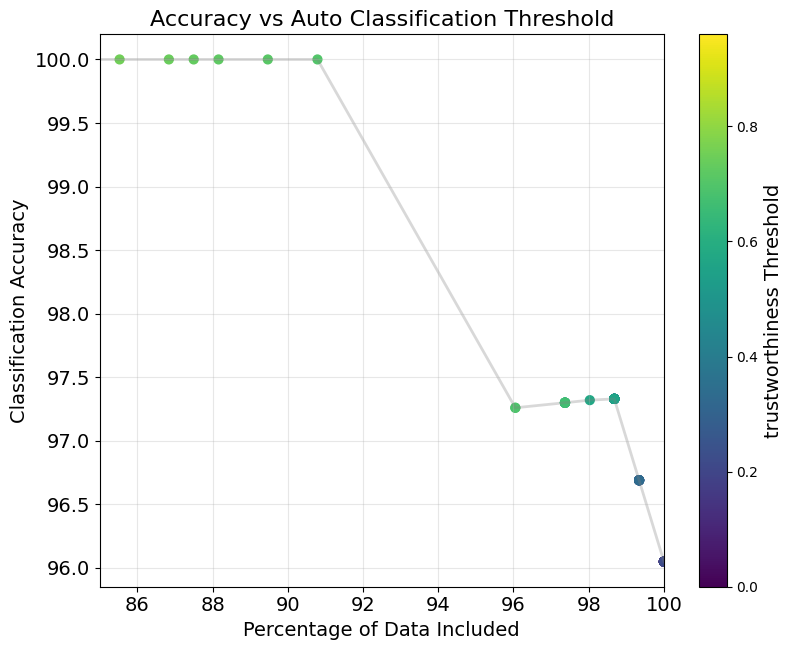
The above plot shows the accuracy of TLM predicted labels, if we only have the LLM handle the subset of the data where TLM’s trustworthiness score exceeds a certain threshold. This shows how TLM can ensure a target labeling accuracy for examples above a certain trustworthiness score. You can escalate to humans who manually categorize the remaining data whose trustworthiness falls below a score threshold.
For this task, we can achieve 100% accuracy in automated classification with TLM by setting the trustworthiness score threshold near 0.7, which allows us to automatically categorize 91% of the data. This means you only need to manually handle 9% of the data to achieve perfect accuracy. Use TLM trust scores to guarantee reliable LLM classifications.
Automatically Boost Accuracy
Beyond scoring trustworthiness, TLM can auto-improve the accuracy of LLM predictions if you specify a higher number of num_candidate_responses in TLMOptions. Additionally consider setting TLM’s base model option to a more powerful LLM that works well in your domain. TLM can automatically improve the accuracy of any LLM model, no change to your prompts/code required!
base_accuracy = np.mean(df["predicted_category"] == df["type"])
print(f"Base accuracy: {base_accuracy:.1%}")
# Here we set a higher number of candidate responses to auto-improve accuracy
tlm_best = TLM(options={"model": MODEL, "num_candidate_responses": 6})
best_responses = tlm_best.prompt(df['prompt'].to_list(), constrain_outputs=categories + ["other"])
df[["best_predicted_category","best_trustworthiness_score"]] = pd.DataFrame(best_responses)
boosted_accuracy = np.mean(df['type'] == df['best_predicted_category'])
print(f"Boosted accuracy: {boosted_accuracy:.1%}")
Next Steps
If you are enforcing Structured Outputs on your LLM, learn how you can still apply TLM via our OpenAI API. For classification tasks: structured outputs may degrade accuracy, so using TLM’s constrain_outputs argument is generally recommended over using structured outputs.
For binary classification tasks (i.e. Yes/No or True/False decisions), learn how you can control false positive/negative error rates with TLM via our tutorial: Yes/No Decisions.
Learn how to auto-label data using TLM and save human data annotation costs via our tutorial on: Data Annotation/Labeling.