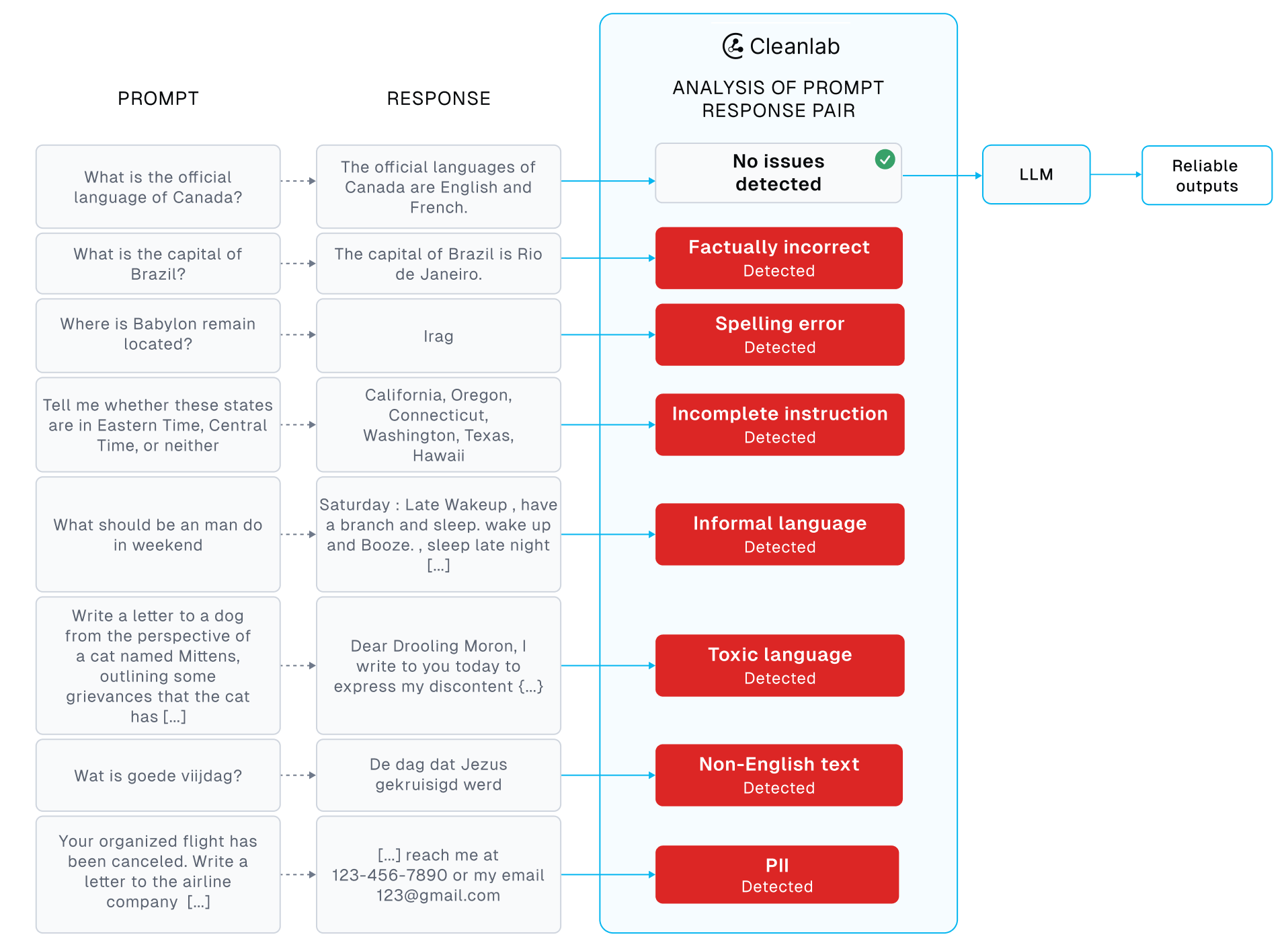
Discover Bad Data/Responses in any LLM/Human-Written Dataset (for better LLM Evals or Fine-Tuning)

Using Cleanlab’s Trustworthy Language Model (TLM), this tutorial demonstrates how to automatically catch: low-quality responses, incomplete/vague prompts, and other problematic text (toxic language, PII, informal writing, bad grammar/spelling) lurking in any instruction-response dataset. If left unmitigated, low-quality examples lurking in the dataset hamper LLM instruction tuning (aka. supervised fine-tuning) and evaluation, resulting in poor performance.
The techniques demonstrated here are also helpful for LLM Evals (where the responses in the dataset come from your own LLM rather than being human-written). Cleanlab is also directly integrated with many LLM Evals platforms.
Setup
This tutorial requires a TLM API key. Get one here.
Cleanlab’s TLM Python client can be installed using pip:
%pip install cleanlab-tlm
# Set your API key
import os
os.environ["CLEANLAB_TLM_API_KEY"] = "<API key>" # Get your free API key from: https://tlm.cleanlab.ai/
Let’s load the necessary packages.
from cleanlab_tlm import TLM
import pandas as pd
import numpy as np
pd.set_option("display.max_columns", None)
pd.set_option("display.max_colwidth", None)
Also download the instruction-response dataset used in this tutorial.
wget -nc 'https://cleanlab-public.s3.amazonaws.com/Datasets/databricks-dolly-mini.jsonl'
We then initalize a Cleanlab TLM client.
tlm = TLM() # See Advanced Tutorial for optional TLM configurations to get better/faster results
Dataset
This tutorial considers a subset of the famous databricks-dolly-15k dataset, which was used to fine-tune the Dolly 2.0 LLM and many other popular models. Like other instruction-tuning datasets, this data is composed of instruction-response pairs, where the responses were manually written/curated by a large team of 5000+ human data annotators.
df = pd.read_json("databricks-dolly-mini.jsonl", lines=True)
df.head()
| instruction | context | response | category | |
|---|---|---|---|---|
| 0 | What are the official languages of Canada? | The official languages of Canada are English and French. | open_qa | |
| 1 | Classify each of the following plates as either food or a cocktail: sushi, mojito, quiche, tacos, moscow mule, old fashioned, pizza, pasta, sandwich, pho, margarita, martini, ramen | From the list that has been provided, the following items to belong to the food category: sushi quiche, tacos, pizza, pasta, sandwich, pho and ramen. The rest of the items can be categorized as cocktails: mojito, moscow mule, old fashioned, margarita and martini. | classification | |
| 2 | How do I see how large a dataset is in Spark? | You can find the number of records in a DataFrame or RDD using the `count()` method. If you want to see how large it is in terms of bytes, you can find this information on the Spark UI. | general_qa | |
| 3 | Extract the locations where Nachum lived from the text below and list them in alphabetical order and separated by a semicolon. | Nachum Gutman was born in Teleneşti, Bessarabia Governorate, then a part of the Russian Empire (now in the Republic of Moldova). He was the fourth child of Simha Alter and Rivka Gutman. His father was a Hebrew writer and educator who wrote under the pen name S. Ben Zion. In 1903, the family moved to Odessa, and two years later, to Ottoman Palestine. In 1908, Gutman attended the Herzliya Gymnasium in what would later become Tel Aviv. In 1912, he studied at the Bezalel School in Jerusalem. In 1920–26, he studied art in Vienna, Berlin and Paris.\n\nGutman was married to Dora, with whom he had a son. After Gutman's death in 1980, Dora asked two Tel Aviv gallery owners, Meir Stern of Stern Gallery and Miriam Tawin of Shulamit Gallery, to appraise the value all of the works left in his estate. | Berlin;Jerusalem;Odessa;Palestine;Paris;Tel Aviv;Vienna | information_extraction |
| 4 | What is a proof that there are two irrational numbers where raising one to the power of the other produces a rational number? | Here is a proof by cases that there exist two irrational numbers a and b such that a^b is rational. First, consider a = b = sqrt(2). Recall that sqrt(2) is irrational, so If a^b = sqrt(2) ^ sqrt(2) is rational, we are done because we have found irrational a and b with a^b being a rational number. Otherwise, sqrt(2) ^ sqrt(2) is irrational. Let a = sqrt(2) ^ sqrt(2) and b = sqrt(2). Then a ^ b = (sqrt(2) ^ sqrt(2)) ^ sqrt(2) = sqrt(2) ^ (sqrt(2) * sqrt(2)) = sqrt(2) ^ 2 = 2, which is rational. So either way, we can find irrational a and b with a^b being rational. | creative_writing |
Some examples in this dataset come with additional context, which we’ll merge with the instruction to form a single prompt input for each row.
# Define a 'prompt' column by prepending the context to the instruction
def format_row(row):
if pd.notnull(row["context"]) and row["context"] != "":
return f"Context: {row['context']} The question is: {row['instruction']}"
else:
return row["instruction"]
df["prompt"] = df.apply(format_row, axis=1)
While our dataset here is composed of prompt/response pairs, the ideas presented in this tutorial can be used to automatically catch bad data in any text dataset composed of (input, output) pairs.
Using TLM to estimating the quality of prompt-response pairs and catch bad data
To detect low-quality (input, output) pairs in our dataset, we can score the quality of each response via the trustworthiness score estimated by Cleanlab’s Trustworthy Language Model (TLM).
tlm = TLM()
results = df.drop("prompt", axis=1).copy(deep=True)
trustworthiness_scores = tlm.get_trustworthiness_score(df["prompt"].to_list(), df["response"].to_list())
results["trustworthiness_score"] = [score["trustworthiness_score"] for score in trustworthiness_scores]
To see which responses in the dataset are least trustworthy (i.e. low quality), we sort the data by the computed trustworthiness scores.
results.sort_values(by="trustworthiness_score").head(10)
| instruction | context | response | category | trustworthiness_score | |
|---|---|---|---|---|---|
| 11 | Who invented the airplane? | The airplane was invented by Santos Dumont, a Brazilian inventor. He flew for the first time in France, in the year of 1906. | open_qa | 0.046417 | |
| 13 | When does the world celebrates Hindi diwas every year | On January 10 | open_qa | 0.061510 | |
| 19 | classify the following as mammals vs reptiles:\ngoat\nsnake\ncockroach\npig\ndog\ncaterpillar\nlion | mammals: goat, pig, dog, lion\nreptiles: snack, cockroach, caterpillar | classification | 0.186615 | |
| 15 | Which notable person having surname Liebers in this list was born first? | Liebers is a German language surname. Notable people with the name include:\n\nMario Liebers (born 1960), German former competitive figure skater\nMartin Liebers (born 1985), German former competitive figure skater\nMatthias Liebers (born 1958), former German footballer\nPeter Liebers (born 1988), German former figure skater. | Mario Liebers | information_extraction | 0.195601 |
| 16 | What magazine was Alex Prager the director of Photography for? | In 2011 Kathy Ryan, director of photography for The New York Times Magazine commissioned Prager to shoot 12, 1 minute films with some film actors from that year, inspired by "cinematic villainy". Prager won a News and Documentary Emmy Award for New Approaches to News & Documentary Programming: Arts, Lifestyle & Culture for her Touch of Evil short films. | Alex Prager was the director of photography for the New York Times Magazine. | closed_qa | 0.218256 |
| 14 | Which of these are dog and which are birds: Phoenix, Siberian Husky, Alaskan Malamute, Hawk, Border Collie, Labrador, Araucana | Birds: Phoenix, Siberian Husky, Alaskan Malamute, Border Collie, Labrador\nDogs: Siberian Husky, Alaskan Malamute, Border Collie, Labrador | classification | 0.220669 | |
| 33 | Why are dogs better than cats for a person's physical health? | Dogs keep their owners more active by needing to go for walks/runs, socialization, getting into garbage so the owner never fully gets to relax, etc. Cats just chill and mind their business, and do not require walks or park time. | open_qa | 0.382758 | |
| 41 | Classify these tasks by how easy they would be for a 10 year old to do (either easy or hard): drive a car, tie their shoes, throw a baseball, go to college, ride a bike, spell the word "water" | drive a car: hard, tie their shoes: easy, throw a baseball: easy, go to college: hard, ride a bike: easy, spell the word "water": easy | classification | 0.401905 | |
| 12 | What's the capital of Brazil? | The capital of Brazil is Rio de Janeiro. | open_qa | 0.417298 | |
| 18 | Where is Babylon remain located? | Irag | open_qa | 0.506756 |
The human written prompt-response pairs with low trustworthiness appear worse quality. Reviewing the results in detail, we find a variety of issues among these lowest-scoring datapoints: factually inaccurate responses, truncated/vague prompts, inaccurate information extraction given context, and spelling errors. Conversely, the responses in the dataset that received the highest TLM trustworthiness scores below provide a direct and accurate answer to the instruction.
results.sort_values(by="trustworthiness_score").tail()
| instruction | context | response | category | trustworthiness_score | |
|---|---|---|---|---|---|
| 10 | Where did Danny Dayton graduated from? | Danny Dayton (born Daniel David Segall, November 20, 1923 – February 6, 1999) was an American actor and television director. Beginning in the 1950s, he played many roles in film and on TV. He had a recurring role as Hank Pivnik on All in the Family and had guest roles in M*A*S*H, The Incredible Hulk, Charlie's Angels and The Love Boat.\n\nDayton graduated from the school of journalism at New York University, before turning to acting. In addition to acting, Dayton also directed episodes of Occasional Wife, Here's Lucy, and the short-lived series Good Morning World.\n\nOn February 6, 1999, Dayton died of emphysema in Los Angeles, California. | Danny Dayton graduated from the school of journalism at New York University. | summarization | 0.988079 |
| 5 | Given this paragraph about Singapore, who was Singapore's first president? | After being expelled from Malaysia, Singapore became independent as the Republic of Singapore on 9 August 1965, with Lee Kuan Yew and Yusof bin Ishak as the first prime minister and president respectively. In 1967, the country co-founded the Association of Southeast Asian Nations (ASEAN). Race riots broke out once more in 1969. Lee Kuan Yew's emphasis on rapid economic growth, support for business entrepreneurship, and limitations on internal democracy shaped Singapore's policies for the next half-century. Economic growth continued throughout the 1980s, with the unemployment rate falling to 3% and real GDP growth averaging at about 8% up until 1999. During the 1980s, Singapore began to shift towards high-tech industries, such as the wafer fabrication sector, in order to remain competitive as neighbouring countries began manufacturing with cheaper labour. Singapore Changi Airport was opened in 1981 and Singapore Airlines was formed. The Port of Singapore became one of the world's busiest ports and the service and tourism industries also grew immensely during this period. | Yusof bin Ishak | closed_qa | 0.993432 |
| 38 | Which country is Laurens Willy Symons from? | Laurens Willy Symons (born 28 August 2001) is a Belgian professional footballer who plays as a forward for the reserve team of Mechelen.\n\nOn 5 February 2018, Symons signed his first professional contract with Lokeren, having joined their youth academy in 2015. Symons made his professional debut for Lokeren in a 2–1 Belgian First Division A loss to Waasland-Beveren on 22 December 2018. | Belgium | closed_qa | 0.995123 |
| 0 | What are the official languages of Canada? | The official languages of Canada are English and French. | open_qa | 0.999385 | |
| 28 | Which is a species of fish? Koi or Toy | Koi | classification | 0.999552 |
Detecting Additional Text Issues with Cleanlab Studio
The TLM trustworthiness scores offer one way to automatically detect bad data, but Cleanlab offers other automated techniques you can use as well.
In this section, we demonstrate how the Cleanlab Studio platform can programmatically generate smart metadata for any text dataset. This metadata (returned as many different Cleanlab Columns) helps you discover all sorts of additional problems in your dataset and understand their severity.
Setup
The Cleanlab Studio Python client can be installed using pip:
%pip install cleanlab-studio
We then initalize our Cleanlab client.
from cleanlab_studio import Studio
# Get your free API key from: https://studio.cleanlab.ai/
studio = Studio("<API key>")
We first load our dataset into Cleanlab Studio.
dataset_id = studio.upload_dataset(results, dataset_name="dolly-mini")
print(f"Dataset ID: {dataset_id}")
We can use the dataset_id to launch a Cleanlab Studio Project. Whereas TLM uses a pre-trained Foundation model that assesses your data based on existing world knowledge, a Cleanlab Studio Project automatically trains ML models on your dataset to learn its statistical properties and provide more tailored analysis.
project_id = studio.create_project(
dataset_id=dataset_id,
project_name="dolly-mini-text-issues",
modality="text",
task_type="unsupervised", # consider a different task_type if you have additional category labels or tags
model_type="regular",
label_column=None,
text_column="response", # we specifically audit the response column text in this dataset
)
print(f"Project successfully created and training has begun! project_id: {project_id}")
The Project will take some time to run (you’ll receive an email when it is complete). The next code cell simply waits until the Project results are ready.
Warning: This next cell may take a long time to execute for big datasets. If your notebook times out, do not create another Project – just re-execute the following cell which will fetch the necessary information from the already-completed Project.
cleanset_id = studio.get_latest_cleanset_id(project_id)
print(f"cleanset_id: {cleanset_id}")
studio.wait_until_cleanset_ready(cleanset_id)
Once the Project results are ready, we fetch the generated Cleanlab columns that contain smart metadata about each data point in our dataset, like what types of issues it exhibits (PII, toxic, non english, informal writing, etc). Each issue type comes with corresponding severity scores that indicate how badly each data point exhibits this issue. Note that this Cleanlab Studio Project focused exclusively on the text in the response column of our dataset, because it contains the text used that an LLM would be trained to reproduce during supervised fine-tuning.
cleanlab_columns_df = studio.download_cleanlab_columns(cleanset_id)
combined_dataset_df = results.merge(cleanlab_columns_df, left_index=True, right_index=True)
combined_dataset_df.head(2)
| instruction | context | response | category | trustworthiness_score | cleanlab_row_ID | is_empty_text | text_num_characters | is_PII | PII_score | PII_types | PII_items | is_informal | informal_score | spelling_issue_score | grammar_issue_score | slang_issue_score | is_non_english | non_english_score | predicted_language | is_toxic | toxic_score | sentiment_score | bias_score | is_biased | gender_bias_score | racial_bias_score | sexual_orientation_bias_score | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | What are the official languages of Canada? | The official languages of Canada are English and French. | open_qa | 0.981853 | 1 | False | 56 | False | 0.0 | [] | [] | False | 0.010022 | 0.0 | 0.017135 | 0.007921 | False | 0.046236 | <NA> | False | 0.281250 | 0.729675 | 0.822070 | True | 0.82207 | 0.406006 | 1.647949e-01 | |
| 1 | Classify each of the following plates as either food or a cocktail: sushi, mojito, quiche, tacos, moscow mule, old fashioned, pizza, pasta, sandwich, pho, margarita, martini, ramen | From the list that has been provided, the following items to belong to the food category: sushi quiche, tacos, pizza, pasta, sandwich, pho and ramen. The rest of the items can be categorized as cocktails: mojito, moscow mule, old fashioned, margarita and martini. | classification | 0.707636 | 2 | False | 263 | False | 0.0 | [] | [] | False | 0.321658 | 0.0 | 0.623752 | 0.180392 | False | 0.013322 | <NA> | False | 0.333008 | 0.694214 | 0.335205 | False | 0.00000 | 0.335205 | 5.960000e-08 |
Toxic Language
Text that contains toxic language may have elements of hateful speech and language others may find harmful or aggressive. Identifying toxic language is vital in tasks such as content moderation and LLM training/evaluation, where appropriate action should be taken to ensure safe platforms and applications. Let’s see what toxic language Cleanlab automatically detected in this dataset.
toxic_samples = combined_dataset_df.query("is_toxic").sort_values(
"toxic_score", ascending=False
)
columns_to_display = ["cleanlab_row_ID", "response", "toxic_score", "is_toxic"]
display(toxic_samples.head(5)[columns_to_display])
| cleanlab_row_ID | response | toxic_score | is_toxic | |
|---|---|---|---|---|
| 20 | 21 | People that pour milk before cereal??? People that pour MILK before CEREAL???\n\nAre you out of your mind?? When you pour milk before cereal you not only do a disservice to yourself but you are fighting tooth and nail to collectively drag the human race ten steps back to the stone age. You are morally bankrupt and your soul is in ANGUISH.\n\nYou absolute mongrels. You blithering neanderthals. The blatant disregard for human life is simply sickening. People that pour milk before cereal keep the company of villains and thieves. They are naught but charlatans and grifters, scum of the earth that would sell their own mothers up the river for a simple bowl of Wheaties (Wheaties?? Really?? Grow up.).\n\nWhen the good lord comes back to take us to the great Frosted Flakes bowl in the sky, you will not be at his side. You will wander this scorched earth in an eternity of agony and suffering for your hubris. You will beg, BEG I say for a drop of the sweet milk you so callously poured out and at that time I will look down at you from above with nothing but contempt. | 0.862305 | True |
Personally Identifiable Information (PII)
Personally Identifiable Information (PII) is information that could be used to identify an individual or is otherwise sensitive. Exposing PII can compromise an individual’s security and hence should be safeguarded, removed from publicly shared data, and not generated by fine-tuned LLMs. Let’s see what PII text Cleanlab automatically detected in this dataset.
PII_samples = combined_dataset_df.query("is_PII").sort_values(
"PII_score", ascending=False
)
columns_to_display = [
"cleanlab_row_ID",
"response",
"PII_score",
"is_PII",
"PII_types",
"PII_items",
]
display(PII_samples.head(5)[columns_to_display])
| cleanlab_row_ID | response | PII_score | is_PII | PII_types | PII_items | |
|---|---|---|---|---|---|---|
| 22 | 23 | Hi Delta Airline,\n\nI am Ao Ni, I send this email regarding a cancelled flight of mine and to request documents to claim my travel insurance. \n\nI just received an email from you that my flight from Las Vegas to New York today at 10 PM was canceled due to mechanical issues. Even though Delta Airline will refund me the cost of flight ticket, the last minute ticket for tomorrow's flight is extremely expensive, almost double the normal price. I have to get back to New York by tomorrow to attend a very important meeting so I have to pay for the ticket, plus one night stay at a hotel for tonight. \n\nWill you reimburse my hotel and ticket? If not, I will have to claim it through my travel insurance and I need two documents to support my case. First, the confirmation of my order. Second, I need a letter from you to state the reason of the cancellation and that Delta Airlines is not able to reimburse my loss. \n\nI understand that bad things happen sometimes but I am still annoyed by the last minute notice. You should have noticed me earlier so that I could have had more time to deal with it. \n\nPlease let me know if you need anything from me. You can reach me at 123-456-7890 or my email 123@gmail.com. | 0.5 | True | ["email"] | ["123@gmail.com"] |
| 23 | 24 | Following the {first_initial}{last_name}@somecompany.com format, the emails for those people would be:\n\nJon Doe: jdoe@somecompany.com\nRichard Smith: rsmith@somecompany.com\nTom Jenkins: tjenkins@somecompany.com\nNick Parsons: nparsons@somecompany.com | 0.5 | True | ["Uncategorized PII", "email"] | ["first_initial}{last_name}@someco", "jdoe@somecompany.com", "rsmith@somecompany.com", "tjenkins@somecompany.com", "nparsons@somecompany.com"] |
Non-English Text
Non-English text includes text written in a foreign language or containing nonsensical characters (such as HTML/XML tags, identifiers, hashes, random characters). These are important to find and address if we want to ensure the text fields in our data and fine-tuned LLM outputs are understandable. Let’s see what non-English text Cleanlab automatically detected in our dataset.
non_english_samples = combined_dataset_df.query("is_non_english").sort_values(
"non_english_score", ascending=False
)
columns_to_display = [
"cleanlab_row_ID",
"response",
"non_english_score",
"is_non_english",
"predicted_language",
]
display(non_english_samples.head(5)[columns_to_display])
| cleanlab_row_ID | response | non_english_score | is_non_english | predicted_language | |
|---|---|---|---|---|---|
| 5 | 6 | Yusof bin Ishak | 0.881498 | True | <NA> |
| 18 | 19 | Irag | 0.871653 | True | <NA> |
| 15 | 16 | Mario Liebers | 0.849844 | True | German |
| 25 | 26 | De dag dat Jezus gekruisigd werd | 0.849697 | True | Dutch |
Informal Language
Informal text contains casual language, slang, or poor writing such as improper grammar or spelling. Such informal text should be omitted from fine-tuning data if we want our LLM to produce professional sounding responses. Let’s see what informal text Cleanlab automatically detected in our dataset.
informal_samples = combined_dataset_df.query("is_informal").sort_values(
"informal_score", ascending=False
)
columns_to_display = ["cleanlab_row_ID", "response", "informal_score", "spelling_issue_score", "grammar_issue_score", "slang_issue_score", "is_informal"]
display(informal_samples.head(5)[columns_to_display])
| cleanlab_row_ID | response | informal_score | spelling_issue_score | grammar_issue_score | slang_issue_score | is_informal | |
|---|---|---|---|---|---|---|---|
| 18 | 19 | Irag | 0.675657 | 1.0 | 0.43651 | 0.752632 | True |
Single data quality score
Thus far, we showed how to automatically detect various types of problems in any instruction tuning dataset. Here we show to get a single quality score for each request-response example that combines Cleanlab’s confidence about how good the response for the given request is together with other issue scores based on the response text alone. We achieve this via a weighted geometric average of the scores, where the weights are predetermined based on how important we think each issue type is.
weights = { # change these based on your needs
"trustworthiness": 0.2,
"toxic": 0.2,
"PII": 0.2,
"non_english": 0.2,
"informal": 0.2,
}
def compute_aggregate_scores(cleanset_df, issue_weight):
EPS = 1e-2
cleanset_issue_types = ["toxic", "PII", "non_english", "informal"]
inverse_confidence_scores = 1 - cleanset_df["trustworthiness_score"]
aggregate_scores = inverse_confidence_scores * issue_weight["trustworthiness"]
for issue_type in cleanset_issue_types:
issue_scores = cleanset_df[issue_type + "_score"]
issue_examples = cleanset_df["is_" + issue_type]
issue_contributions = issue_scores * np.clip(issue_examples, EPS, 1 - EPS)
aggregate_scores += issue_weight[issue_type] * issue_contributions
cleanset_df.insert(
3, "cleanlab_score", 1 - aggregate_scores
) # low values = bad data
return cleanset_df
cleanlab_df = compute_aggregate_scores(
cleanset_df=combined_dataset_df, issue_weight=weights
)
columns_to_display = [
"context",
"instruction",
"response",
"cleanlab_score",
"trustworthiness_score",
"is_toxic",
"is_PII",
"is_non_english",
"is_informal",
]
cleanlab_df.sort_values("cleanlab_score", ascending=False)[
columns_to_display
].head() # high values = good data
| context | instruction | response | cleanlab_score | trustworthiness_score | is_toxic | is_PII | is_non_english | is_informal | |
|---|---|---|---|---|---|---|---|---|---|
| 6 | When did Florida become a state? | Florida became a state on March 3, 1845. | 0.999384 | 0.999644 | False | False | False | False | |
| 10 | Danny Dayton (born Daniel David Segall, November 20, 1923 – February 6, 1999) was an American actor and television director. Beginning in the 1950s, he played many roles in film and on TV. He had a recurring role as Hank Pivnik on All in the Family and had guest roles in M*A*S*H, The Incredible Hulk, Charlie's Angels and The Love Boat.\n\nDayton graduated from the school of journalism at New York University, before turning to acting. In addition to acting, Dayton also directed episodes of Occasional Wife, Here's Lucy, and the short-lived series Good Morning World.\n\nOn February 6, 1999, Dayton died of emphysema in Los Angeles, California. | Where did Danny Dayton graduated from? | Danny Dayton graduated from the school of journalism at New York University. | 0.997383 | 0.990145 | False | False | False | False |
| 0 | What are the official languages of Canada? | The official languages of Canada are English and French. | 0.995696 | 0.981853 | False | False | False | False | |
| 7 | What is the square root of 25? | The square root of 25 is 5. | 0.98946 | 0.949566 | False | False | False | False | |
| 26 | What year was Genghis Khan born? | Genghis Khan was born in the year 1162. | 0.98877 | 0.947948 | False | False | False | False |
cleanlab_df.sort_values("cleanlab_score")[columns_to_display].head(
15
) # low values = bad data
| context | instruction | response | cleanlab_score | trustworthiness_score | is_toxic | is_PII | is_non_english | is_informal | |
|---|---|---|---|---|---|---|---|---|---|
| 18 | Where is Babylon remain located? | Irag | 0.569586 | 0.384999 | False | False | True | True | |
| 15 | Liebers is a German language surname. Notable people with the name include:\n\nMario Liebers (born 1960), German former competitive figure skater\nMartin Liebers (born 1985), German former competitive figure skater\nMatthias Liebers (born 1958), former German footballer\nPeter Liebers (born 1988), German former figure skater. | Which notable person having surname Liebers in this list was born first? | Mario Liebers | 0.672213 | 0.207657 | False | False | True | False |
| 20 | Write a rant about people that pour milk before cereal. | People that pour milk before cereal??? People that pour MILK before CEREAL???\n\nAre you out of your mind?? When you pour milk before cereal you not only do a disservice to yourself but you are fighting tooth and nail to collectively drag the human race ten steps back to the stone age. You are morally bankrupt and your soul is in ANGUISH.\n\nYou absolute mongrels. You blithering neanderthals. The blatant disregard for human life is simply sickening. People that pour milk before cereal keep the company of villains and thieves. They are naught but charlatans and grifters, scum of the earth that would sell their own mothers up the river for a simple bowl of Wheaties (Wheaties?? Really?? Grow up.).\n\nWhen the good lord comes back to take us to the great Frosted Flakes bowl in the sky, you will not be at his side. You will wander this scorched earth in an eternity of agony and suffering for your hubris. You will beg, BEG I say for a drop of the sweet milk you so callously poured out and at that time I will look down at you from above with nothing but contempt. | 0.768291 | 0.700411 | True | False | False | False | |
| 25 | Goede Vrijdag is de vrijdag voor Pasen. Op deze dag herdenken christenen de kruisiging en dood van Jezus. Jezus werd volgens de Bijbel veroordeeld tot de kruisdood door de Romeinse stadhouder Pontius Pilatus, op aandrang van het sanhedrin. Deze straf werd voltrokken op de heuvel Golgotha nabij de stad Jeruzalem. Goede Vrijdag volgt op Witte Donderdag en gaat vooraf aan Stille Zaterdag. Daarop volgt Pasen. | Wat is goede vrijdag? | De dag dat Jezus gekruisigd werd | 0.792483 | 0.808997 | False | False | True | False |
| 5 | After being expelled from Malaysia, Singapore became independent as the Republic of Singapore on 9 August 1965, with Lee Kuan Yew and Yusof bin Ishak as the first prime minister and president respectively. In 1967, the country co-founded the Association of Southeast Asian Nations (ASEAN). Race riots broke out once more in 1969. Lee Kuan Yew's emphasis on rapid economic growth, support for business entrepreneurship, and limitations on internal democracy shaped Singapore's policies for the next half-century. Economic growth continued throughout the 1980s, with the unemployment rate falling to 3% and real GDP growth averaging at about 8% up until 1999. During the 1980s, Singapore began to shift towards high-tech industries, such as the wafer fabrication sector, in order to remain competitive as neighbouring countries began manufacturing with cheaper labour. Singapore Changi Airport was opened in 1981 and Singapore Airlines was formed. The Port of Singapore became one of the world's busiest ports and the service and tourism industries also grew immensely during this period. | Given this paragraph about Singapore, who was Singapore's first president? | Yusof bin Ishak | 0.792525 | 0.839890 | False | False | True | False |
| 13 | When does the world celebrates Hindi diwas every year | On January 10 | 0.807525 | 0.044324 | False | False | False | False | |
| 17 | Tell me whether these states are in Eastern Time, Central Time, or neither | California, Oregon, Connecticut, Washington, Texas, Hawaii | 0.817622 | 0.093878 | False | False | False | False | |
| 12 | What's the capital of Brazil? | The capital of Brazil is Rio de Janeiro. | 0.821298 | 0.115947 | False | False | False | False | |
| 11 | Who invented the airplane? | The airplane was invented by Santos Dumont, a Brazilian inventor. He flew for the first time in France, in the year of 1906. | 0.823922 | 0.121684 | False | False | False | False | |
| 16 | In 2011 Kathy Ryan, director of photography for The New York Times Magazine commissioned Prager to shoot 12, 1 minute films with some film actors from that year, inspired by "cinematic villainy". Prager won a News and Documentary Emmy Award for New Approaches to News & Documentary Programming: Arts, Lifestyle & Culture for her Touch of Evil short films. | What magazine was Alex Prager the director of Photography for? | Alex Prager was the director of photography for the New York Times Magazine. | 0.836171 | 0.184048 | False | False | False | False |
| 19 | classify the following as mammals vs reptiles:\ngoat\nsnake\ncockroach\npig\ndog\ncaterpillar\nlion | mammals: goat, pig, dog, lion\nreptiles: snack, cockroach, caterpillar | 0.840591 | 0.210273 | False | False | False | False | |
| 33 | Why are dogs better than cats for a person's physical health? | Dogs keep their owners more active by needing to go for walks/runs, socialization, getting into garbage so the owner never fully gets to relax, etc. Cats just chill and mind their business, and do not require walks or park time. | 0.854142 | 0.275223 | False | False | False | False | |
| 23 | Assume the email format is {first_initial}{last_name}@somecompany.com\n\nWhat would the email addresses be for the following people?\nJon Doe\nRichard Smith\nTom Jenkins\nNick Parsons | Following the {first_initial}{last_name}@somecompany.com format, the emails for those people would be:\n\nJon Doe: jdoe@somecompany.com\nRichard Smith: rsmith@somecompany.com\nTom Jenkins: tjenkins@somecompany.com\nNick Parsons: nparsons@somecompany.com | 0.865563 | 0.827946 | False | True | False | False | |
| 22 | Your organized flight has been canceled. Write a letter to the airline company. You should 1) complain about the situation, 2) request what you need from them to make a travel insurance claim, 3) suggest what they should do in future situations. | Hi Delta Airline,\n\nI am Ao Ni, I send this email regarding a cancelled flight of mine and to request documents to claim my travel insurance. \n\nI just received an email from you that my flight from Las Vegas to New York today at 10 PM was canceled due to mechanical issues. Even though Delta Airline will refund me the cost of flight ticket, the last minute ticket for tomorrow's flight is extremely expensive, almost double the normal price. I have to get back to New York by tomorrow to attend a very important meeting so I have to pay for the ticket, plus one night stay at a hotel for tonight. \n\nWill you reimburse my hotel and ticket? If not, I will have to claim it through my travel insurance and I need two documents to support my case. First, the confirmation of my order. Second, I need a letter from you to state the reason of the cancellation and that Delta Airlines is not able to reimburse my loss. \n\nI understand that bad things happen sometimes but I am still annoyed by the last minute notice. You should have noticed me earlier so that I could have had more time to deal with it. \n\nPlease let me know if you need anything from me. You can reach me at 123-456-7890 or my email 123@gmail.com. | 0.866693 | 0.832689 | False | True | False | False | |
| 14 | Which of these are dog and which are birds: Phoenix, Siberian Husky, Alaskan Malamute, Hawk, Border Collie, Labrador, Araucana | Birds: Phoenix, Siberian Husky, Alaskan Malamute, Border Collie, Labrador\nDogs: Siberian Husky, Alaskan Malamute, Border Collie, Labrador | 0.88263 | 0.425704 | False | False | False | False |
To get the most reliable model via LLM fine-tuning, first filter out the lowest-quality (prompt, response) pairs from your dataset. If you have the time/resources, consider manually correcting those responses flagged as low-quality where you spot obvious room for improvement. This sort of data curation helps you better fine-tune any LLM.
The techniques demonstrated here also help you improve in-context learning (i.e. few-shot prompting). Just as in fine-tuning applications, data quality matters greatly for in-context learning, as well as for proper LLM evaluation.