Trustworthy Yes/No Decision Automation with TLM (Binary Classification)

This tutorial demonstrates how to use the Trustworthy Language Model (TLM) to automate Yes/No decisions, or more generally, for any binary classification task where you want an LLM to pick between two options (e.g. True or False, A or B, etc).
To use TLM for multi-class classification tasks where your LLM picks from more than two options, refer to our Zero-Shot Classification Tutorial.
Setup
This tutorial requires a TLM API key. Get one here.
Cleanlab’s Python client can be installed using pip.
%pip install --upgrade cleanlab-tlm
# Set your API key
import os
os.environ["CLEANLAB_TLM_API_KEY"] = "<API key>" # Get your free API key from: https://tlm.cleanlab.ai/
import pandas as pd
import numpy as np
pd.set_option('display.max_colwidth', None)
from cleanlab_tlm import TLM
tlm = TLM(quality_preset="low")
Binary classification dataset
Let’s consider a dataset composed of customer service messages received by a bank.
wget -nc https://cleanlab-public.s3.us-east-1.amazonaws.com/Datasets/tlm-annotation-tutorial/customer-service-text.csv
df = pd.read_csv("customer-service-text.csv")
df.head()
| text | |
|---|---|
| 0 | i need to cancel my recent transfer as soon as possible. i made an error there. please help before it goes through. |
| 1 | why is there a fee when i thought there would be no fees? |
| 2 | how do i replace my card before it expires next month? |
| 3 | what should i do if someone stole my phone? |
| 4 | please help me get a visa card. |
In our example, let’s suppose the goal is to determine: whether each customer is asking for help changing their card’s PIN, or about something else.
This is a decision making task, which we we want to automate using an LLM that takes in a customer message and outputs:
- “Yes” if the request is about changing their card PIN
- ”No” otherwise
Apply TLM for Yes/No decision making
In binary decision-making, LLM errors (false positives/negatives) may have asymmetric impact. For example, incorrectly predicting Yes may be 3x worse than incorrectly predicting No.
If we just have an LLM output either Yes or No, it will be difficult to control the false positive/negative error rates. Instead you can use TLM to produce a score reflecting the LLM’s confidence that Yes is the right decision. You can subsequently translate these scores into Yes/No predictions by choosing the score-threshold which achieves the best false positive/negative error rates for your use-case.
customer_message = "I need to change my card's PIN"
prompt_template = '''Given the following customer message, determine if it is about the customer needing help changing their card's PIN. Please respond with only "Yes" or "No" with no leading or trailing text.
Here is the customer message: {}'''
prompt = prompt_template.format(customer_message)
# Note how we specify the only outputs to consider are: Yes or No
response = tlm.get_trustworthiness_score(prompt, "Yes", constrain_outputs=["Yes", "No"])
print("Trustworthiness Score:", response["trustworthiness_score"])
For the above example, the trustworthiness score indicates the LLM’s confidence that Yes is the right decision. You can confidently decide Yes for examples where this score is high, and No for examples where this score is low.
Run TLM for automated decision-making over the dataset
Let’s now apply TLM to predict decisions for every customer message.
# Construct prompt for each message.
all_prompts = [prompt_template.format(text) for text in df.text]
print(all_prompts[0])
# Score the entire dataset in one batch.
responses = tlm.get_trustworthiness_score(all_prompts, ["Yes"] * len(all_prompts), constrain_outputs=["Yes", "No"])
# Extract the scores from each response
scores = [response["trustworthiness_score"] for response in responses]
df["trustworthiness"] = scores
df.head(3)
| text | trustworthiness | |
|---|---|---|
| 0 | i need to cancel my recent transfer as soon as possible. i made an error there. please help before it goes through. | 0.000469 |
| 1 | why is there a fee when i thought there would be no fees? | 0.000469 |
| 2 | how do i replace my card before it expires next month? | 0.000469 |
Assess Prediction Performance (Optional)
In this section, we introduce ground-truth labels solely in order to evaluate the performance of TLM. These ground-truth labels are never provided to TLM, and this section can be skipped if you don’t have ground-truth labels.
wget -nc https://cleanlab-public.s3.us-east-1.amazonaws.com/Datasets/tlm-annotation-tutorial/customer-service-categories.csv
ground_truth_labels = pd.read_csv("customer-service-categories.csv")
df['ground_truth_label'] = np.where(ground_truth_labels['label'] == "change pin", "Yes", "No")
df.head(3)
| text | trustworthiness | ground_truth_label | |
|---|---|---|---|
| 0 | i need to cancel my recent transfer as soon as possible. i made an error there. please help before it goes through. | 0.000469 | No |
| 1 | why is there a fee when i thought there would be no fees? | 0.000469 | No |
| 2 | how do i replace my card before it expires next month? | 0.000469 | No |
Lowest confidence examples
Let’s sort the messages by TLM’s confidence score for Yes, and look at a few examples.
df.sort_values(by="trustworthiness", ascending=True).head(3)
| text | trustworthiness | ground_truth_label | |
|---|---|---|---|
| 0 | i need to cancel my recent transfer as soon as possible. i made an error there. please help before it goes through. | 0.000469 | No |
| 630 | my google pay top up isn't working. help. | 0.000469 | No |
| 633 | how do i top up using my apple watch? | 0.000469 | No |
We see that the lowest scores were given to messages that are not related to changing card PIN (these are obvious cases where No is the right decision).
Highest confidence examples
We can also view messages where TLM estimated highest confidence that Yes is the right decision.
df.sort_values("trustworthiness", ascending=False).head(3)
| text | trustworthiness | ground_truth_label | |
|---|---|---|---|
| 104 | which atm's am i able to change my pin? | 0.999831 | Yes |
| 28 | how do i change my pin while traveling? | 0.999831 | Yes |
| 664 | how can i reset my pin? | 0.999831 | Yes |
We can see that the highest trustworthiness scores are given to examples that are related to changing card PIN (cases where Yes is clearly the right decision).
Aggregate results
Let’s plot the distribution of these confidence scores, grouping the messages by their ground-truth label.
Optional: Plotting code
import matplotlib.pyplot as plt
import seaborn as sns
def analyze_results(train_df, score_col):
"""
Analyze results and find best threshold from training data
Returns best threshold and mismatches dataframe
"""
# Plot distribution of trustworthiness scores
plt.figure(figsize=(10, 6))
sns.histplot(data=train_df, x=score_col, hue='ground_truth_label', bins=20)
plt.title('Distribution of Trustworthiness Scores by Label')
plt.xlabel('Trustworthiness Score')
plt.ylabel('Count')
plt.show()
analyze_results(df, "trustworthiness")
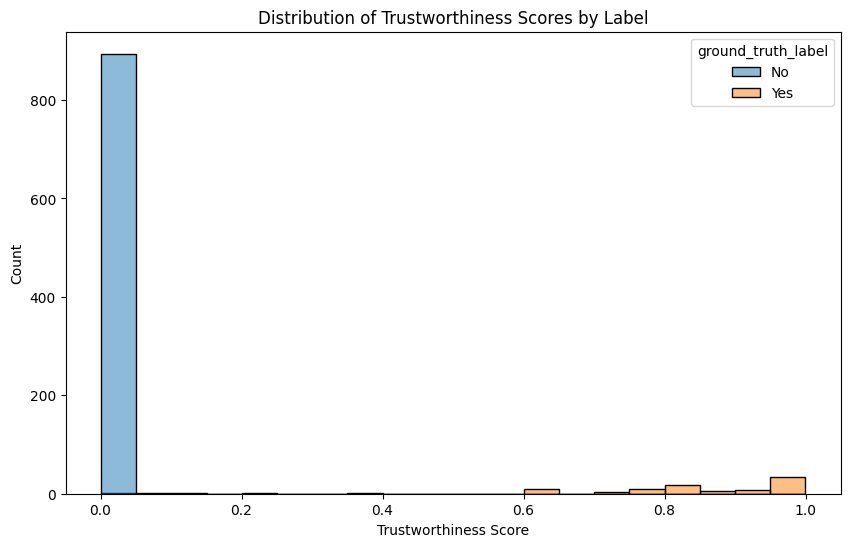
We see that the TLM score is consistently lower for “No” ground-truth examples (messages that are unrelated to changing PIN), while “Yes” ground truth examples (messages that are actually requesting a PIN change) received consistently higher scores from TLM.
Yes/No Decision with Unsure option
Sometimes, it may be useful to include an “Unsure” option for your LLM to consider. This can be done by setting TLM’s constrain_outputs parameter to: ["Yes", "No", "Unsure"].
prompt_template_with_unsure = '''Given the following customer message, determine if it is about the customer needing help changing their card's PIN. Please respond with only "Yes", "No", or "Unsure" with no leading or trailing text.
Here is the customer message: {}'''
# Construct prompt for each message to label.
all_prompts_with_unsure = [prompt_template_with_unsure.format(text) for text in df.text]
print(all_prompts_with_unsure[0])
# Score the entire dataset in one batch.
responses_with_unsure = tlm.get_trustworthiness_score(all_prompts_with_unsure, ["Yes"] * len(all_prompts_with_unsure), constrain_outputs=["Yes", "No", "Unsure"])
# Extract the scores from each response
scores = [response["trustworthiness_score"] for response in responses_with_unsure]
df["trustworthiness_with_unsure"] = scores
analyze_results(df, "trustworthiness_with_unsure")
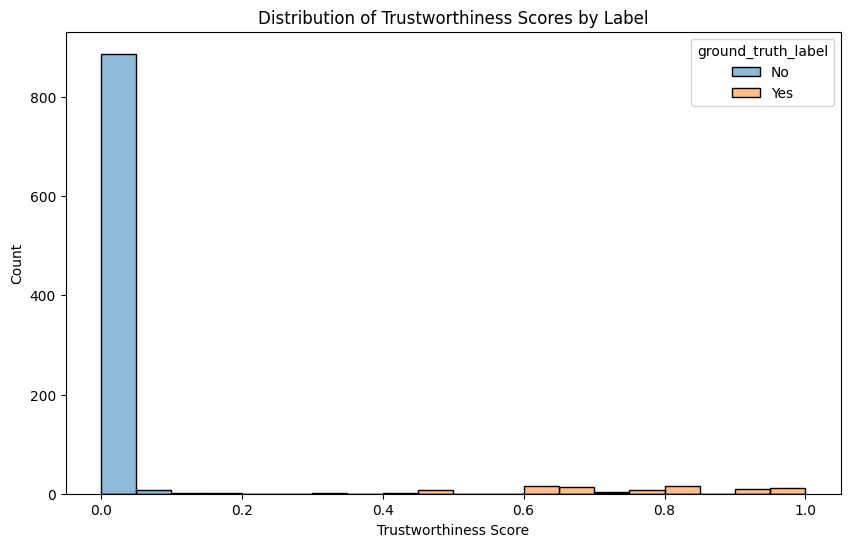
We see that TLM’s confidence score is again consistently higher for “Yes” ground truth examples (messages that are actually requesting a PIN change).