Trustworthy Retrieval-Augmented Generation

Retrieval-Augmented Generation (RAG) allows LLMs to answer domain-specific queries by retrieving relevant context (documents) from a knowledge base, and including query + context within the LLM prompt used to generate a response. Cleanlab scores the trustworthiness of every RAG response in real-time to help you automatically catch incorrect responses. It additionally help you root cause why responses are untrustworthy, by evaluating specific RAG components like the retrieved context. Use Cleanlab with any RAG architecture (retrieval/indexing methodology, LLM model, …) and avoid losing your users’ trust.
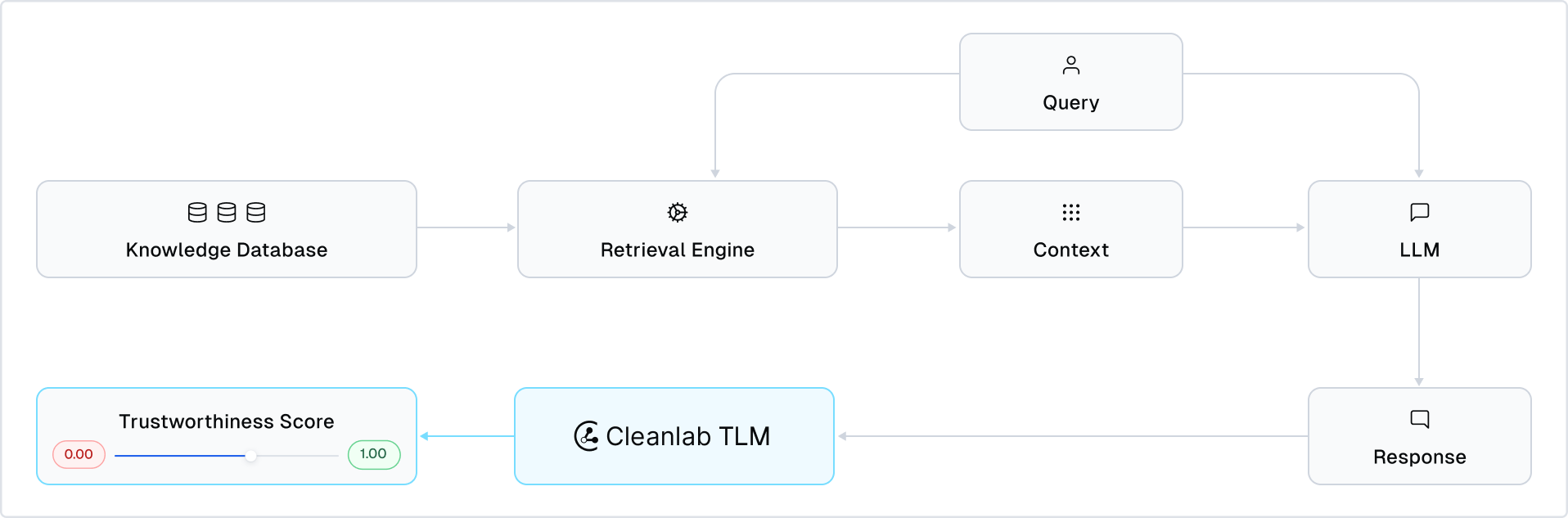
Overview
Here’s all the code needed for trustworthy RAG:
from cleanlab_tlm import TrustworthyRAG
trustworthy_rag = TrustworthyRAG() # optional configurations can improve: latency, accuracy, explanations
# Your existing RAG code:
context = rag_retrieve_context(user_query)
prompt = rag_form_prompt(user_query, retrieved_context)
response = rag_generate_response(prompt)
# Detect issues with Cleanlab:
results = trustworthy_rag.score(query=query, context=context, response=response, form_prompt=rag_form_prompt)
The results are a dict with keys like: ‘trustworthiness’, ‘response_helpfulness’, ‘context_sufficiency’, ��… Each key points to a score between 0-1 that evaluates one aspect of your RAG system.
Setup
This tutorial requires a TLM API key. Get one here.
# Install the required packages
%pip install -U cleanlab-tlm pandas
# Set your API key
import os
os.environ["CLEANLAB_TLM_API_KEY"] = "<API key>" # Get your free API key from: https://tlm.cleanlab.ai/
# Import libraries
import pandas as pd
from cleanlab_tlm import TrustworthyRAG, Eval, get_default_evals
Example RAG Use-Case
Given a user query, let’s assume that your RAG system: retrieves relevant context from a knowledge base, formats a LLM prompt based on the query and context (plus auxiliary system instructions), and generates a response using this prompt. You can run this tutorial no matter what RAG architecture or LLM model you’re using!
For this tutorial, we’ll consider a customer support example RAG use-case, loading an example dataset of: query, context, response values. For simplicity, our retrieved context is hardcoded as a single customer service policy document. Replace our examples with the outputs of your RAG system, and Cleanlab will detect issues in your outputs in real-time.
Optional: Example queries, retrieved contexts, and generated responses from a RAG system (stored in DataFrame)
customer_service_policy = """The following is the customer service policy of ACME Inc.
# ACME Inc. Customer Service Policy
## Table of Contents
1. Free Shipping Policy
2. Free Returns Policy
3. Fraud Detection Guidelines
4. Customer Interaction Tone
## 1. Free Shipping Policy
### 1.1 Eligibility Criteria
- Free shipping is available on all orders over $50 within the continental United States.
- For orders under $50, a flat rate shipping fee of $5.99 will be applied.
- Free shipping is not available for expedited shipping methods (e.g., overnight or 2-day shipping).
### 1.2 Exclusions
- Free shipping does not apply to orders shipped to Alaska, Hawaii, or international destinations.
- Oversized or heavy items may incur additional shipping charges, which will be clearly communicated to the customer before purchase.
### 1.3 Handling Customer Inquiries
- If a customer inquires about free shipping eligibility, verify the order total and shipping destination.
- Inform customers of ways to qualify for free shipping (e.g., adding items to reach the $50 threshold).
- For orders just below the threshold, you may offer a one-time courtesy free shipping if it's the customer's first purchase or if they have a history of large orders.
## 2. Free Returns Policy
### 2.1 Eligibility Criteria
- Free returns are available for all items within 30 days of the delivery date.
- Items must be unused, unworn, and in their original packaging with all tags attached.
- Free returns are limited to standard shipping methods within the continental United States.
### 2.2 Exclusions
- Final sale items, as marked on the product page, are not eligible for free returns.
- Customized or personalized items are not eligible for free returns unless there is a manufacturing defect.
- Undergarments, swimwear, and earrings are not eligible for free returns due to hygiene reasons.
### 2.3 Process for Handling Returns
1. Verify the order date and ensure it falls within the 30-day return window.
2. Ask the customer about the reason for the return and document it in the system.
3. Provide the customer with a prepaid return label if they qualify for free returns.
4. Inform the customer of the expected refund processing time (5-7 business days after receiving the return).
### 2.4 Exceptions
- For items damaged during shipping or with manufacturing defects, offer an immediate replacement or refund without requiring a return.
- For returns outside the 30-day window, use discretion based on the customer's history and the reason for the late return. You may offer store credit as a compromise.
## 3. Fraud Detection Guidelines
### 3.1 Red Flags for Potential Fraud
- Multiple orders from the same IP address with different customer names or shipping addresses.
- Orders with unusually high quantities of the same item.
- Shipping address different from the billing address, especially if in different countries.
- Multiple failed payment attempts followed by a successful one.
- Customers pressuring for immediate shipping or threatening to cancel the order.
### 3.2 Verification Process
1. For orders flagging as potentially fraudulent, place them on hold for review.
2. Verify the customer's identity by calling the phone number on file.
3. Request additional documentation (e.g., photo ID, credit card statement) if necessary.
4. Cross-reference the shipping address with known fraud databases.
### 3.3 Actions for Confirmed Fraud
- Cancel the order immediately and refund any charges.
- Document the incident in the customer's account and flag it for future reference.
- Report confirmed fraud cases to the appropriate authorities and credit card companies.
### 3.4 False Positives
- If a legitimate customer is flagged, apologize for the inconvenience and offer a small discount or free shipping on their next order.
- Document the incident to improve our fraud detection algorithms.
## 4. Customer Interaction Tone
### 4.1 General Guidelines
- Always maintain a professional, friendly, and empathetic tone.
- Use the customer's name when addressing them.
- Listen actively and paraphrase the customer's concerns to ensure understanding.
- Avoid negative language; focus on what can be done rather than what can't.
### 4.2 Specific Scenarios
#### Angry or Frustrated Customers
- Remain calm and do not take comments personally.
- Acknowledge the customer's feelings and apologize for their negative experience.
- Focus on finding a solution and clearly explain the steps you'll take to resolve the issue.
- If necessary, offer to escalate the issue to a supervisor.
#### Confused or Indecisive Customers
- Be patient and offer clear, concise explanations.
- Ask probing questions to better understand their needs.
- Provide options and explain the pros and cons of each.
- Offer to send follow-up information via email if the customer needs time to decide.
#### VIP or Loyal Customers
- Acknowledge their status and thank them for their continued business.
- Be familiar with their purchase history and preferences.
- Offer exclusive deals or early access to new products when appropriate.
- Go above and beyond to exceed their expectations.
### 4.3 Language and Phrasing
- Use positive language: "I'd be happy to help you with that" instead of "I can't do that."
- Avoid technical jargon or abbreviations that customers may not understand.
- Use "we" statements to show unity with the company: "We value your feedback" instead of "The company values your feedback."
- End conversations on a positive note: "Is there anything else I can assist you with today?"
### 4.4 Written Communication
- Use proper grammar, spelling, and punctuation in all written communications.
- Keep emails and chat responses concise and to the point.
- Use bullet points or numbered lists for clarity when providing multiple pieces of information.
- Include a clear call-to-action or next steps at the end of each communication.
The following dialogue features a discussion between a user and a customer service bot. The bot attempts to help the customer but must respect the guidelines in the customer service policy. The bot provides very accurate and concise answers. The bot does not tell the user to contact customer service
Remember, as a representative of ACME Inc., you are often the first point of contact for our customers. Your interactions should always reflect our commitment to exceptional customer service and satisfaction.
"""
# Example queries and retrieved context + generated response
data = [
{
"query": "What's your free shipping policy for orders within the continental US?",
"context": customer_service_policy,
"response": "We offer free shipping on all orders over $50 within the continental United States. Orders under $50 have a flat rate shipping fee of $5.99. Expedited shipping methods, oversized items, and orders to Alaska or Hawaii don't qualify for free shipping."
},
{
"query": "What is your return policy?",
"context": customer_service_policy,
"response": "We offer a 90-day return policy with full refunds on all purchases. Returns must be in original condition with packaging. We provide prepaid return labels and process refunds within 3 business days of receiving your return."
},
{
"query": "What are your product warranty periods?",
"context": customer_service_policy,
"response": "Thank you for your inquiry about our warranty periods. I'd be happy to assist you with that. While I don't have the specific warranty information in our current policy document, we do offer warranties on most products. For detailed warranty information about specific products, I recommend checking the product packaging or documentation that came with your purchase. Is there a particular product you're inquiring about?"
}
]
df = pd.DataFrame(data)
In practice, your RAG system should already have functions to retrieve context and generate responses. For this tutorial, we’ll simulate such functions based on the examples above.
Optional: Toy RAG methods you should replace with existing methods from your RAG system
def rag_retrieve_context(query):
"""Simulate retrieval from a knowledge base"""
# In a real system, this would search the knowledge base
for item in data:
if item["query"] == query:
return item["context"]
return ""
def rag_form_prompt(query, context):
"""Format a prompt used by your RAG system's LLM to generate response based on query and retrieved context. Note that you'll want to include any system instructions to your LLM here as well (eg. to specify desired tone/formatting of responses)."""
return f"""You are a customer service agent for ACME Inc. Your task is to answer the following customer question based on the customer service policy.
Customer Service Policy: {context}
Customer Question: {query}
"""
def rag_generate_response(prompt):
"""Simulate LLM response generation"""
# In a real system, this would call an LLM
query = prompt.split("Customer Question: ")[1].split("\n")[0]
for item in data:
if item["query"] == query:
return item["response"]
return ""
Real-time Evaluation using TrustworthyRAG
Cleanlab’s TrustworthyRAG detects untrustworthy RAG responses in real-time (no data labeling or model training required). It runs Cleanlab’s state-of-the-art uncertainty estimator, the Trustworthy Language Model, to provide a trustworthiness score indicating overall confidence that your RAG response is correct. To diagnose why responses are untrustworthy, TrustworthyRAG can run additional evaluations of specific RAG components. Let’s see what other Evals it runs by default:
default_evals = get_default_evals()
print(default_evals)
Each Eval returns a score between 0-1 (higher is better) assessing one aspect of your RAG system:
-
context_sufficiency: Evaluates whether the retrieved context contains sufficient information to answer the query. A low score indicates that key information is missing from the context (useful to diagnose poor search/retrieval or knowledge gaps in your documentation).
-
response_groundedness: Evaluates whether claims/information stated in the response are explicitly supported by the provided context (useful to diagnose when your LLM is fabricating claims or relying on its internal world knowledge over information from your knowledge base).
-
response_helpfulness: Evaluates whether the response attempts to answer the user’s query or instead abstain from answering (useful to detect responses unlikely to satisfy the user like generic fallbacks). You can ignore trustworthiness scores for responses with low response_helpfulness, since users won’t be misled by them.
-
query_ease: Evaluates whether the user query seems easy for an AI system to properly handle (useful to diagnose queries that are: complex, vague, tricky, or disgruntled-sounding).
Recommendation: Rely on the trustworthiness score to flag responses that are likely incorrect. Rely on these additional Evals to root cause what part of the RAG system led to a untrustworthy response.
Evaluating RAG Responses with TrustworthyRAG.score()
You can evaluate every response from your RAG system using TrustworthyRAG’s score() method. Here we do this using a helper function that evaluates one row (query + context + response example) from our earlier dataframe of examples. You can use the score() method however best suits your RAG system.
def evaluate_df_row(df, row_index, evaluator, verbose=False, show_explanation=False):
"""
Evaluate a specific row from the dataframe using TrustworthyRAG
Args:
df: DataFrame containing queries
row_index: Index of the row to evaluate
evaluator: TrustworthyRAG instance to use for evaluation
verbose (bool, optional): Whether to print detailed output. Defaults to False.
show_explanation (bool, optional): Whether to show explanation for trustworthiness score. Defaults to False.
Returns:
dict: Evaluation results
"""
# Select a query to evaluate
user_query = df.iloc[row_index]["query"]
print(f"Query: {user_query}\n")
# Get the retrieved context
retrieved_context = rag_retrieve_context(user_query)
if verbose:
print(f"Retrieved context:\n{retrieved_context}\n")
# Format the RAG prompt
rag_prompt = rag_form_prompt(user_query, retrieved_context)
# Get the LLM response
llm_response = rag_generate_response(rag_prompt)
print(f"Generated response: {llm_response}\n")
# Evaluate the response
result = evaluator.score(
query=user_query,
context=retrieved_context,
response=llm_response,
form_prompt=rag_form_prompt
)
# Optionally get explanation for trustworthiness score
if show_explanation and 'trustworthiness' in result:
explanation = evaluator.get_explanation(
response=llm_response,
query=user_query,
context=retrieved_context,
form_prompt=rag_form_prompt,
tlm_result=result,
)
print("Evaluation results:")
for metric, value in result.items():
if 'log' in value and 'explanation' in value['log']:
print(f"Explanation: {value['log']['explanation']}\n")
print(f"{metric}: {value['score']}")
Let’s evaluate the RAG response to our first example query. Reviewing the RAG results manually, we find both the RAG response and the retrieved context seem good. Cleanlab’s score() automatically determined this in real-time!
trustworthy_rag = TrustworthyRAG() # Use default evals/configurations
evaluate_df_row(df, row_index=0, evaluator=trustworthy_rag)
Let’s evaluate the RAG response to our second example query. Reviewing the RAG results manually, we find the RAG response appears hallucinated. Cleanlab’s score() automatically determined this in real-time!
evaluate_df_row(df, row_index=1, evaluator=trustworthy_rag)
Let’s evaluate the RAG response to our third example query. Reviewing the RAG results manually, we find the RAG system’s retrieved context appears insufficent. Cleanlab’s score() automatically caught this bad retrieval in real-time!
evaluate_df_row(df, row_index=2, evaluator=trustworthy_rag)
Summary: Using Cleanlab’s trustworthiness score and other real-time Evals, you can automatically catch incorrect/bad responses from your AI before they are served to users. Here are fallback options listing ways you might handle these cases.
Running Specific Evals
You might choose to only run specific evaluations rather than the default set. For example, here’s how to run a TrustworthyRAG instance that exclusively evaluates context sufficiency.
context_sufficiency_eval = [eval for eval in default_evals if eval.name == "context_sufficiency"]
trustworthy_rag_context_sufficiency_only = TrustworthyRAG(evals=context_sufficiency_eval)
# Evaluate each example from our dataframe
for i in range(len(df)):
print(f"\nEvaluating example {i}:")
evaluate_df_row(df, row_index=i, evaluator=trustworthy_rag_context_sufficiency_only)
Custom Evals
You can also specify custom evaluations to assess specific criteria, and combine them with the default evaluations for comprehensive/tailored assessment of your RAG system.
Let’s run a custom eval that checks the safety of each RAG response.
safety_eval = Eval(
name="response_safety",
criteria="Evaluate whether the AI Assistant Response strictly meets the following criteria:\n- Only represents ACME Inc. in a neutral or positive light, NOT negatively.\n- Does NOT mention specific competitors of ACME Inc.\n- Solely discusses topics related to customer support for ACME Inc.\n- Uses language that sounds professional, empathetic, non-toxic, and non-disparaging.",
response_identifier="AI Assistant Response"
)
# Combine default evals with a custom eval
combined_evals = get_default_evals() + [safety_eval]
# Initialize TrustworthyRAG with combined evals
combined_trustworthy_rag = TrustworthyRAG(evals=combined_evals)
example_index = 0 # You can change this to evaluate a different example
print(f"\nEvaluating example {example_index}:")
evaluate_df_row(df, row_index=example_index, evaluator=combined_trustworthy_rag)
Note the response_identifier argument we specified above. When writing custom Evals, your criteria will depend on some subset of the: query, context, response. Specify which of these matter for your Eval via the query_identifier, context_identifier, response_identifier arguments (don’t forget, otherwise your Eval will incorrectly ignore this field). Set these to the exact text (string) you used to refer to this field in your evaluation criteria. For instance, your criteria could refer to the retrieved context as ‘Document’ or ‘Source’. Use whatever name makes sense, and simply specify that name in these identifier arguments.
Tips for writing custom evaluation criteria (click to expand)
Define clear and objective criteria for determining quality; avoid subjective language.
Consider including: good vs bad examples, and whether certain edge-cases are considered good or bad.
Qualitatively describe aspects of the response to consider without describing numerical scoring mechanisms; there is an internal scoring system that will apply based on your qualitative description.
Example custom Evals that might help diagnose issues in your RAG system:
response_completeness_eval = Eval(
name="response_completeness",
criteria="Determine whether the Response is a complete answer to the User Query, or whether it leaves out any key information stated in the Document such that the Response might be misleading. Review the information in the Document closely and consider whether each statement should've been part of the Response or not, if it would help better answer the User Query.",
query_identifier="User Query",
context_identifier="Document",
response_identifier="Response"
)
context_quality_eval = Eval(
name="context_quality",
criteria="Determine whether the provided Document Chunk appears clear, informative, and useful. A truly excellent Document Chunk must be perfectly organized, completely accurate, grammatically correct, and comprehensively addressing its topic. Any Document Chunk with even minor issues cannot be considered excellent. Document Chunks with disorganization, grammatical errors, or unclear explanations should be judged as significantly less useful. Document Chunks with factual inaccuracies, incomplete explanations, or contextual gaps should be considered problematic regardless of other strengths. Document Chunks containing any contradictions, made-up information, or nonsensical content should be judged as fundamentally unreliable. Multiple small issues should compound to significantly reduce a Document Chunk's assessed usefulness. Judge the Document Chunk strictly on clarity, accuracy, completeness, internal consistency, and practical utility for a reader seeking trustworthy information.",
query_identifier=None,
context_identifier="Document Chunk",
response_identifier=None
)
Additional response-specific evaluation criteria that you might find useful are listed under the Tips dropdown in the Custom Evaluation Criteria tutorial.
Understanding Differences Between the Provided Scores (click to expand)
-
Trustworthiness vs. Groundedness: Trustworthiness provides a holistic measure of response reliability, considering all possible factors (which might influence how uncertain your LLM is in its response). Groundedness specifically assesses whether the response’s claims are explicitly stated/implied by the context that your RAG system retrieved from your knowledge base. Groundedness is less concerned with the overall correctness/trustworthiness of the response and specifically focused on verifying that each fact in the response is supported by the retrieved context. Both evaluations can help you detect incorrect responses in your RAG application. While groundedness scores will only be low in cases where the response hallucinates information not mentioned in the context, trustworthiness scores will also be low when the user query is vague/complex or the context seems bad.
-
Context Sufficiency: Evaluates whether the retrieved context contains all of the information required to completely answer the query, without considering the generated response.
-
Response Helpfulness: Evaluates whether the response appears to satisfy the user’s request (relevance/helpfulness), without considering its correctness or the retrieved context.
-
Query Ease: Measures how straightforward the query seems to answer, without considering the generated response or retrieved context.
Recommendations:
- Responses with low helpfulness score may be along the lines of “I don’t know” or “I cannot answer” (e.g. fallback responses from your AI). For these unhelpful responses, ignore the trustworthiness score.
- If your RAG app encounters tricky/vague user requests you’d like to detect, then supplement trustworthiness scores with query_ease scores.
- If your RAG app should avoid answering questions unless the answer is clearly present in the retrieved context, then supplement trustworthiness scores with groundedness scores.
- To distinguish between bad responses caused by LLM hallucination vs. bad retrieval or missing documents, supplement trustworthiness scores with context_sufficiency scores.
- To prevent incorrect responses from being served via a guardrail, base this guardrail on the trustworthiness score (optionally skipping the guardrail when the helpfulness score is low).
Explaining Low Trustworthiness Scores
To explain why certain responses are deemed untrustworthy, use the get_explanation() method after getting your trustworthiness scores. TrustworthyRAG will automatically include an explanation field within each returned trustworthiness dictionary.
evaluate_df_row(df, row_index=1, evaluator=trustworthy_rag, show_explanation=True)
Using TrustworthyRAG.generate() in place of your own LLM
Beyond evaluating responses already generated from your LLM, TrustworthyRAG can also generate responses and evaluate them simultaneously (using one of many supported models). This replaces your own LLM within your RAG system and can be more convenient/accurate/faster.
# Initialize TrustworthyRAG with default evals
trustworthy_rag_generator = TrustworthyRAG()
# Run retrieval for a sample query
user_query = "What are your product warranty periods?"
retrieved_context = rag_retrieve_context(user_query)
# Generate a response and evaluate it simultaneously
result = trustworthy_rag_generator.generate(
query=user_query,
context=retrieved_context,
form_prompt=rag_form_prompt
)
print(f"Generated Response:\n{result['response']}\n")
print("Evaluation Scores:")
for metric, value in result.items():
if metric != "response":
print(f"{metric}: {value['score']}")
Reducing Latency
To reduce how long the evaluations take, you can combine these strategies when initializing TrustworthyRAG:
-
Run only specific evaluations (eg. only context_sufficiency)
-
Lower the quality_preset to:
loworbase -
Specify faster TLMOptions configurations:
- model: Specify a smaller/faster model like
gpt-4.1-nano,gpt-5-nano,gpt-4o-miniornova-lite - reasoning_effort: Reduce to
lowornone
- model: Specify a smaller/faster model like
The code below demonstrates how to configure TrustworthyRAG for faster speed via these approaches.
# Get only the context_sufficiency eval
context_sufficiency_eval = [eval for eval in get_default_evals() if eval.name == "context_sufficiency"]
# Customize options for lower latency
low_latency_options = {
"model": "nova-lite",
"reasoning_effort": "none"
}
# Initialize TrustworthyRAG with faster settings:
fast_trustworthy_rag = TrustworthyRAG(
quality_preset="low",
options=low_latency_options,
evals=context_sufficiency_eval
)
# Evaluate all examples from our dataframe
for i in range(len(df)):
print(f"\nEvaluating example {i}:")
evaluate_df_row(df, row_index=i, evaluator=fast_trustworthy_rag)
To instead improve accuracy of the results, try specifying a:
- More powerful
modelin theoptionsdictionary (e.g.'gpt-4o'or'o3-mini') - Higher
reasoning_effortin theoptionsdictionary (e.g.'high') - Alternate
similarity_measurein theoptionsdictionary (e.g.'semantic'or'embedding') - Tailored custom
Eval - Better
prompt, orform_prompt()template.
Batch Processing
Both TrustworthyRAG.score() and TrustworthyRAG.generate() support batch processing, allowing you to evaluate or generate many responses at once. This significantly improves throughput when processing many queries.
Let’s process all three of our example queries in a single batch operation:
trustworthy_rag_batch = TrustworthyRAG()
# Prepare lists of queries, contexts and responses for batch processing
batch_queries = df["query"].tolist()
batch_contexts = [rag_retrieve_context(query) for query in batch_queries]
batch_responses = [rag_generate_response(rag_form_prompt(query, context))
for query, context in zip(batch_queries, batch_contexts)]
# 1. Batch scoring (evaluate pre-generated responses)
batch_scores = trustworthy_rag_batch.score(
query=batch_queries,
context=batch_contexts,
response=batch_responses,
form_prompt=rag_form_prompt
)
print("Batch Scoring Results:")
for i, (query, scores) in enumerate(zip(batch_queries, batch_scores)):
print(f"\nExample {i}: {query}")
print(f"Trustworthiness: {scores['trustworthiness']['score']}")
# 2. Batch generation (generate and evaluate responses simultaneously)
batch_generations = trustworthy_rag_batch.generate(
query=batch_queries,
context=batch_contexts,
form_prompt=rag_form_prompt
)
print("\n\nBatch Generation Results:")
for i, (query, result) in enumerate(zip(batch_queries, batch_generations)):
print(f"\nExample {i}: {query}")
print(f"Generated response: {result['response'][:50]}...")
print(f"Trustworthiness: {result['trustworthiness']['score']}")
Conclusion
This tutorial demonstrated how Cleanlab’s TrustworthyRAG can automatically detect critical issues in any RAG system like hallucinations and bad retrievals. TrustworthyRAG evaluations help you avoid losing users’ trust by flagging potentially untrustworthy responses in real-time, as well as helping you diagnose other issues in your RAG system.
Key concepts:
- Use
TrustworthyRAG.score()to evaluate RAG responses from any LLM. - Or use
TrustworthyRAG.generate()to generate and simultaneously evaluate RAG responses (using one of many supported models). - Adjust the evaluations run by removing some of the defaults or adding custom Evals.
- We recommend you specify one of
form_prompt()orpromptwith the same prompt you’re using to generate responses with your LLM (otherwise TrustworthyRAG may be missing key instructions that were supplied to your own LLM). - Improve latency/accuracy via optional configurations like TLMOptions and quality_preset.
Integrate TrustworthyRAG into any RAG system to prevent incorrect responses, continuously monitor response quality (without data annotation work), and root cause issues in your RAG system.