Add LLM Trustworthiness Scoring to any LangChain or LangGraph application

LLMs are prone to unchecked hallucinations where they occasionally produce plausible but incorrect responses. The Trustworthy Language Model (TLM) scores the trustworthiness of responses from any LLM using state-of-the-art model uncertainty estimation techniques.
This tutorial shows how to produce a real-time trustworthiness score for every LLM call in a simple LangChain application. The same method can be applied in any LangChain/LangGraph applications, to migitate unchecked hallucination.
Setup
This tutorial requires a TLM API key. Get one here.
Let’s install the Python packages required for this tutorial.
%pip install -qU langchain_core langchain_openai langgraph cleanlab-tlm
# Set your API key
import os
os.environ["CLEANLAB_TLM_API_KEY"] = "<API key>" # Get your free API key from: https://tlm.cleanlab.ai/
import logging
from langchain_core.callbacks import BaseCallbackHandler
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.messages import HumanMessage, AIMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import START, MessagesState, StateGraph
from cleanlab_tlm import TLM
Create a simple chain
This tutorial is based on LangChain’s chatbot tutorial. Start there if you aren’t familiar with LangChain or LangGraph.
Let’s create a simple conversational chain using standard concepts like: prompt_template, graph, memory, and model.
# Define prompt template with placeholder for messages
prompt_template = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant."),
MessagesPlaceholder(variable_name="messages"),
])
# Define graph for managing state
workflow = StateGraph(state_schema=MessagesState)
# Function that calls the LLM given current state
def call_model(state: MessagesState):
# Given the current state of messages, prompt the model
response = model.invoke(state["messages"])
return {"messages": response}
# Define single node in the graph
workflow.add_edge(START, "model")
workflow.add_node("model", call_model)
# Add memory
memory = MemorySaver()
app = workflow.compile(checkpointer=memory)
Next we instantiate the LLM object.
model = ChatOpenAI(model="gpt-4o-mini", api_key="<openai_api_key>")
# config ID to capture unique state
config = {"configurable": {"thread_id": "without-tlm"}}
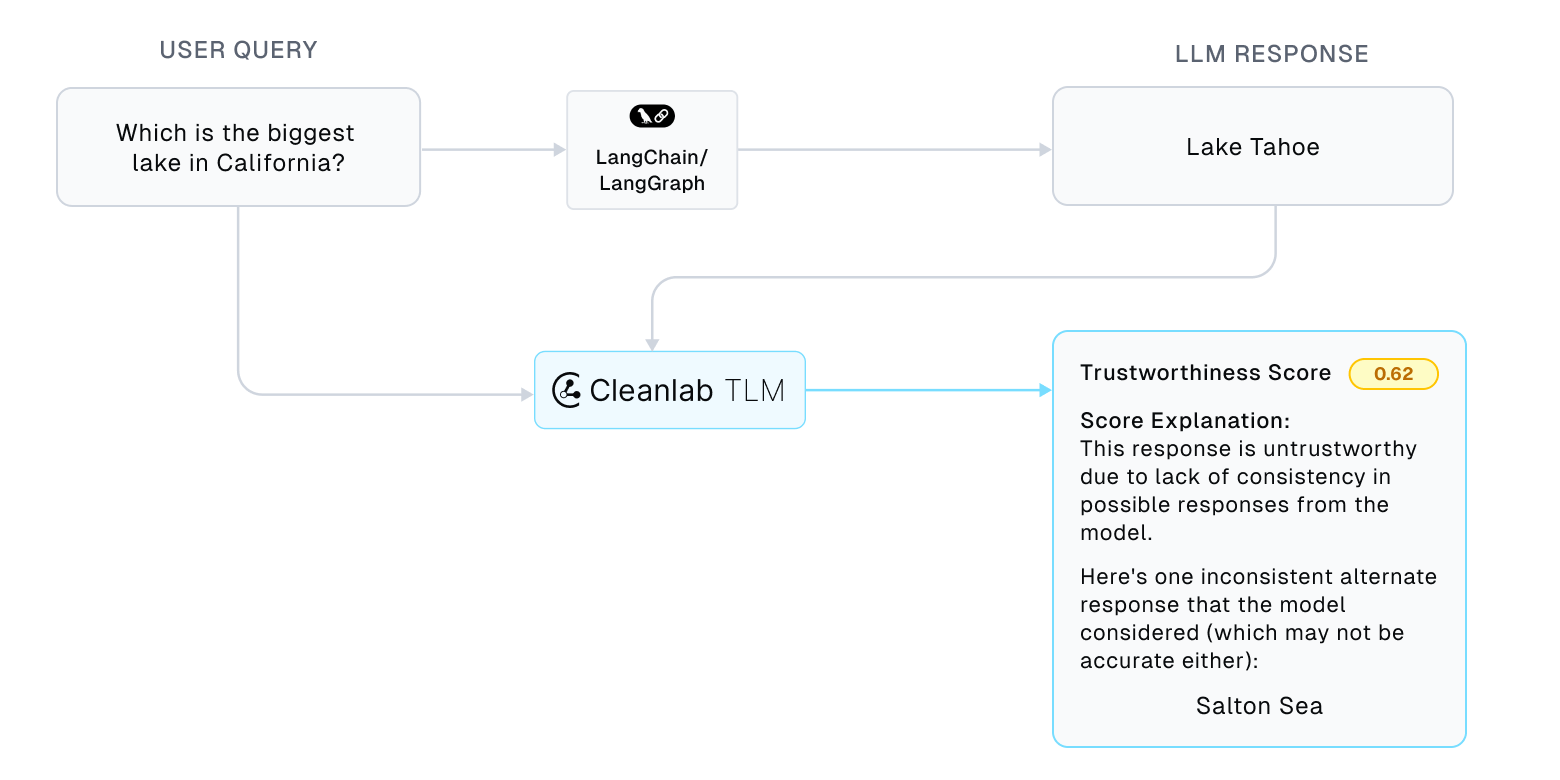
The simple chain offers conversations with the LLM. Let’s ask an example question about lakes in California.
query = "Which is the biggest lake in California?"
input_messages = [HumanMessage(query)]
output = app.invoke({"messages": input_messages}, config)
output["messages"][-1].pretty_print()
Being a stateful chain with memory, we can ask follow-up questions and the LLM will automatically refer back to previous messages as necessary.
query = "How deep is it?"
input_messages = [HumanMessage(query)]
output = app.invoke({"messages": input_messages}, config)
output["messages"][-1].pretty_print()
So far the responses from the LLM looks good. Let’s integrate trustworthiness scoring to this chain to see if there’s a scope for hallucination.
Add trustworthiness scoring
It’s easy to integrate TLM’s trustworthiness score in any existing chain, irrespective of the LLM model (streaming or batch, async or not).
We simply define a Langchain callback that triggers whenever the LLM generates a response. TLM considers both the prompt (with system, user, context messages) and the LLM response in its trustworthiness scoring.
Let’s define this custom callback handler.
class TrustworthinessScoreCallback(BaseCallbackHandler):
def __init__(self, tlm, threshold = 0.7, explanation = True):
# Cleanlab's TLM client
self.tlm = tlm
# Keep track of the prompt
self.prompt = ""
# Threshold to trigger actions
self.threshold = threshold
# Boolean to enable/disable explanation
self.explanation = explanation
def on_llm_start(self, serialized, prompts, run_id, **kwargs):
# Store input prompt
self.prompt = prompts[0]
def on_llm_end(self, response, **kwargs):
# Extract response text from LLMResult object
response_text = response.generations[0][0].text
# Call trustworthiness score method, and extract the score
resp = self.tlm.get_trustworthiness_score(self.prompt, response_text)
score = resp['trustworthiness_score']
# Log score
# This can be replaced with any action that the application requires
# We just print it along with its tag, trustworthy or otherwise
if score < self.threshold:
print(f"[TLM Score]: {score} (Untrustworthy)")
else:
print(f"[TLM Score]: {score} (Trustworthy)")
# Log explanation
# Reasoning for the predicted trustworthiness score
if self.explanation and resp.get("log", {}).get("explanation"):
print(f"[TLM Score Explanation]: {resp['log']['explanation']}")
elif self.explanation:
print("[TLM Warning]: Enable `explanation` in TLM client.")
We then instantiate the TLM object used by this callback. Here we specify explanation in TLM’s options argument to obtain rationales for why LLM responses are deemed untrustworthy.
tlm = TLM(options={'log':['explanation']}) # You can also omit explanations, or specify configurations for faster/better results (see Advanced Tutorial)
Finally, we instantiate an instance of the callback with the TLM object. Currently, the callback would print the trustworthiness score and explanation, but you can modify what actions to take based on the trustworthiness score to meet your needs. For instance, you might threshold the scores and revert to some fallback action whenever LLM responses are deemed untrustworthy
The callback is attached to the LLM so it triggers whenever the LLM is called in a chain. You can attach the callback to multiple LLMs, agents, and other objects that generate a responses when given a prompt.
trustworthiness_callback = TrustworthinessScoreCallback(tlm, explanation=True)
model.callbacks = [trustworthiness_callback]
Now let’s reset the memory of the assistant and ask the same questions, now with trustworthiness scoring enabled.
app = workflow.compile(checkpointer=MemorySaver())
config = {"configurable": {"thread_id": "with-tlm"}}
query = "Which is the biggest lake in California?"
input_messages = [HumanMessage(query)]
output = app.invoke({"messages": input_messages}, config)
output["messages"][-1].pretty_print()
query = "How deep is it?"
input_messages = [HumanMessage(query)]
output = app.invoke({"messages": input_messages}, config)
output["messages"][-1].pretty_print()
We see that the LLM hallucinated for this simple question. The low trustworthiness score from TLM helps you automatically catch such problems in real-time.
TLM optionally provides explanations for its trustworthiness score. You can disable explanations by setting TrustworthinessScoreCallback(tlm, explanation=False).
Feel free to modify this callback to meet your application’s needs. Mitgating unchecked hallucinations is a key step toward reliable AI applications!
Note: You can easily configure TLM to produce faster/better results (reduce latency/cost) for your use-case, see our Advanced Tutorial.