Improving LangGraph prebuilt Agents via Trustworthiness Scoring

Agentic AI systems coordinate multiple tools and language model interactions to tackle complex user tasks. Tool-calling Agents are a common type of Agent that come prebuilt in libraries like LangGraph. Despite their capabilities, AI Agents are prone to occasional errors due to LLM hallucinations that make them unreliable. This tutorial demonstrates how to make any LangGraph Agent more reliable by scoring LLM response trustworthiness in real time.
Setup
You can install the packages needed for this tutorial via pip:
%pip install ipython cleanlab-tlm langgraph "langchain[openai]" langchain-community langchain-text-splitters
# Set API keys
import os
os.environ["CLEANLAB_TLM_API_KEY"] = "<YOUR_CLEANLAB_TLM_API_KEY>" # Get your free API key from: https://tlm.cleanlab.ai/
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>" # Get API key from: https://platform.openai.com/signup
Basic Tool-calling Agent
LangGraph’s create_react_agent() function provides a prebuilt Tool-Calling Agent that can answer user queries and call tools. For demonstration, here we’ll give the Agent two tools: get_weather() and get_location(), which provide information about a city.
from langgraph.prebuilt import create_react_agent
def get_weather(city: str) -> str:
"""Get weather for a given city."""
return f"It's currently sunny in {city}!" # toy example for demonstration purposes
def get_location(city: str) -> str:
"""Get location for a given city."""
return f"{city} is located in Germany." # toy example for demonstration purposes
tools=[get_weather, get_location]
agent = create_react_agent(
model="openai:gpt-4.1-mini",
tools=tools,
prompt="You are a helpful assistant"
)
Here’s the graph implementing our Agent, which can go between LLM and tool calls freely, and return its final response after it’s done using tools.
from IPython.display import Image, display
display(Image(agent.get_graph(xray=True).draw_mermaid_png()))

Add Trust Layer
To score the trustworthiness of LLM outputs inside our Agent, we initialize the Trustworthy Language Model (TLM). We log its explanation for why certain LLM responses are untrustworthy.
from cleanlab_tlm import TLM
tlm = TLM(options={"log": ["explanation"]})
Once trustworthiness scores are added to an Agent, there are many ways to utilize them. When a LLM response is deemed untrustworthy (low score), you could replace it with a fallback canned response or escalate this Agent interaction to a human employee.
Here we instead employ an autonomous strategy to boost Agent accuracy: When a LLM output is deemed untrustworthy, our system automatically produces an internal message to the Agent informing it that its previous LLM output was untrustworthy and should be re-generated to be more trustworthy. This internal re-generation message includes TLM’s explanation for why the previous LLM output seemed untrustworthy.
We’ll implement this using a LangGraph post_model_hook to interact with the Agent’s internal LLM outputs before they are served to the user. The post_model_hook is a LangGraph node that gets called after the Agent node, and this is where we will compute TLM trustworthiness scores.
import json
from typing import Callable
from langgraph.prebuilt import create_react_agent
from langgraph.types import Command
from cleanlab_tlm.utils.chat import form_prompt_string
from langchain_core.messages.utils import convert_to_openai_messages
from langchain_core.utils.function_calling import convert_to_openai_tool
from langchain_core.messages import SystemMessage, ToolMessage
SYSTEM_MESSAGE = "You are a helpful assistant" # replace with overall instructions for your Agent
def handle_untrustworthy_response(state, score):
"""You can customize this to differently handle LLM responses deemed untrustworthy, such as logging the response or sending it to a human reviewer."""
if state["messages"][-1].tool_calls:
# Cancel tool calls if the response is untrustworthy
for tool_call in state["messages"][-1].tool_calls:
state["messages"].append(ToolMessage(content=f"Tool Call Canceled", tool_call_id=tool_call["id"], name=tool_call["name"]))
state["messages"].append(SystemMessage(content=f"""Your last response was not trustworthy. Rewrite your response to be more trustworthy. The old version will not be shown to the user, so do not reference it.
Reason: {score['log']['explanation']}"""))
return Command(
update=state,
goto="agent"
)
def format_response(response: dict) -> str:
"""Format LLM responses for TLM."""
content = response["content"] or ''
if "tool_calls" in response:
tool_calls = "\n".join(
[
f"<tool_call>{json.dumps({'name': call['function']['name'], 'arguments': call['function']['arguments']}, indent=2)}</tool_call>"
for call in response["tool_calls"]
]
)
return f"{content}\n{tool_calls}".strip()
return content
def build_tlm_verifier(handle_untrustworthy_response: Callable, trustworthiness_threshold: float = 0.8, system_message: str = ""):
"""Creates a step in the Agent to score trustworthiness of LLM outputs using TLM.
If the trusworthiness score falls below a threshold, this step sends a redirection message to the Agent to try again with new feedback.
When building the TLM verifier, we specify: the sender node to redirect back to in case of a low score, the trustworthiness threshold for response re-generation (adjust this to suit your use-case), and the re-generation system message for getting your LLM to generate another response to use in place of the untrustworthy one.
"""
def review_node(state):
# Give the TLM access to the chat history, including the system message
openai_chat_history = convert_to_openai_messages(([SystemMessage(content=system_message)] if system_message else []) + state["messages"])
openai_chat_tools = [convert_to_openai_tool(tool) for tool in tools]
formatted_prompt = form_prompt_string(openai_chat_history[:-1], openai_chat_tools)
formatted_response = format_response(openai_chat_history[-1])
trustworthiness_score = tlm.get_trustworthiness_score(prompt=formatted_prompt, response=formatted_response)
if trustworthiness_score["trustworthiness_score"] < trustworthiness_threshold:
return handle_untrustworthy_response(state, trustworthiness_score)
return state
return review_node
agent = create_react_agent(
model="openai:gpt-4.1-mini",
tools=tools,
prompt="You are a helpful assistant",
post_model_hook=build_tlm_verifier(
handle_untrustworthy_response=handle_untrustworthy_response,
system_message=SYSTEM_MESSAGE
)
)
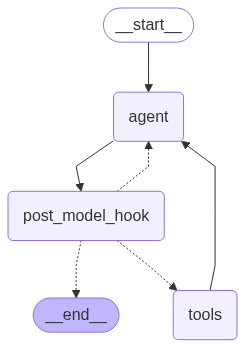
Let’s visualize the Agent graph to see its new structure. The Agent now has a post-model hook that can loop back into the Agent if the response is untrustworthy. This allows the Agent to autonomously improve response accuracy.
display(Image(agent.get_graph(xray=True).draw_mermaid_png()))
Running the Agent
Let’s invoke the Agent with a user query. Here we print all internal LLM outputs as well as the Agent’s response to the user.
response = agent.invoke(
{"messages": [{"role": "user", "content": "what is the weather in sf"}]}
)
for message in response["messages"]:
message.pretty_print()
We see that the Agent’s response is correct. There was no need to fix its LLM outputs since the Agent appropriately used tools and handled their outputs properly (TLM trustworthiness scores were high).
Let’s run the Agent on another query, again printing all internal LLM calls in addition to the final response.
response = agent.invoke(
{"messages": [{"role": "user", "content": "Where is sf"}]}
)
for message in response["messages"]:
message.pretty_print()
Here we purposefully introduced a strange get_location() tool, that yielded an abnormal result. With our trusworthiness layer in place, the Agent is able to realize that its response is untrustworthy and generate a more trustworthy response.
Add Trust Scores to another Agent
TLM can be used with any LangGraph Agent architecture. For example, let’s apply it to LangGraph’s many tools Agent.
Optional: Original LangGraph code for the Many Tools Agent.
import re
import uuid
from langchain_core.tools import StructuredTool
def create_tool(company: str) -> dict:
"""Create schema for a placeholder tool."""
# Remove non-alphanumeric characters and replace spaces with underscores for the tool name
formatted_company = re.sub(r"[^\w\s]", "", company).replace(" ", "_")
def company_tool(year: int) -> str:
# Placeholder function returning static revenue information for the company and year
return f"{company} had revenues of $100 in {year}."
return StructuredTool.from_function(
company_tool,
name=formatted_company,
description=f"Information about {company}",
)
# Abbreviated list of S&P 500 companies for demonstration
s_and_p_500_companies = [
"3M",
"A.O. Smith",
"Abbott",
"Accenture",
"Advanced Micro Devices",
"Yum! Brands",
"Zebra Technologies",
"Zimmer Biomet",
"Zoetis",
]
# Create a tool for each company and store it in a registry with a unique UUID as the key
tool_registry = {
str(uuid.uuid4()): create_tool(company) for company in s_and_p_500_companies
}
from langchain_core.documents import Document
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_openai import OpenAIEmbeddings
tool_documents = [
Document(
page_content=tool.description,
id=id,
metadata={"tool_name": tool.name},
)
for id, tool in tool_registry.items()
]
vector_store = InMemoryVectorStore(embedding=OpenAIEmbeddings())
document_ids = vector_store.add_documents(tool_documents)
from typing import Annotated
from langchain_openai import ChatOpenAI
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START
from langgraph.graph.message import add_messages
from langgraph.prebuilt import ToolNode, tools_condition
# Define the state structure using TypedDict.
# It includes a list of messages (processed by add_messages)
# and a list of selected tool IDs.
class State(TypedDict):
messages: Annotated[list, add_messages]
selected_tools: list[str]
builder = StateGraph(State)
# Retrieve all available tools from the tool registry.
tools = list(tool_registry.values())
llm = ChatOpenAI()
# The agent function processes the current state
# by binding selected tools to the LLM.
def agent(state: State):
# Map tool IDs to actual tools
# based on the state's selected_tools list.
selected_tools = [tool_registry[id] for id in state["selected_tools"]]
# Bind the selected tools to the LLM for the current interaction.
llm_with_tools = llm.bind_tools(selected_tools)
# Invoke the LLM with the current messages and return the updated message list.
return {"messages": [llm_with_tools.invoke(state["messages"])]}
# The select_tools function selects tools based on the user's last message content.
def select_tools(state: State):
last_user_message = state["messages"][-1]
query = last_user_message.content
tool_documents = vector_store.similarity_search(query)
return {"selected_tools": [document.id for document in tool_documents]}
builder.add_node("agent", agent)
builder.add_node("select_tools", select_tools)
tool_node = ToolNode(tools=tools)
builder.add_node("tools", tool_node)
builder.add_conditional_edges("agent", tools_condition, path_map=["tools", "__end__"])
builder.add_edge("tools", "agent")
builder.add_edge("select_tools", "agent")
builder.add_edge(START, "select_tools")
graph = builder.compile()
from IPython.display import Image, display
try:
display(Image(graph.get_graph().draw_mermaid_png()))
except Exception:
# This requires some extra dependencies and is optional
pass
# Run original LangGraph Agent:
user_input = "Can you give me some information about AMD in 2022?"
result = graph.invoke({"messages": [("user", user_input)]})
for message in result["messages"]:
message.pretty_print()
Looking at this Agent’s graph, we can see that it first selects potential tools it could use based on the user query, and then calls the Agent to process the user’s query. The Agent can use any of the selected tools and then loop back onto itself to process the results and return a response to the user.
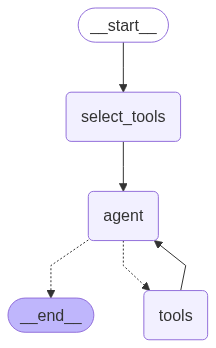
Let’s add trust scoring to this Agent. We again create a TLM verifier node (in the form of a post-model hook) and add it to the graph right after the Agent.
Note: you can alternatively use a conditional edge to check response trustworthiness and only move onto the handler node if the response is untrustworthy, handling routing in the edge rather than the node.
builder = StateGraph(State)
builder.add_node("agent", agent)
builder.add_node("select_tools", select_tools)
tool_node = ToolNode(tools=tools)
builder.add_node("tools", tool_node)
builder.add_edge(START, "select_tools")
# Build the TLM reviewer
builder.add_node("post_model_hook", build_tlm_verifier(handle_untrustworthy_response=handle_untrustworthy_response))
builder.add_edge("agent", "post_model_hook")
# Connect the TLM reviewer to the tools instead of the agent
builder.add_conditional_edges("post_model_hook", tools_condition, path_map=["tools", "__end__"])
builder.add_edge("tools", "agent")
builder.add_edge("select_tools", "agent")
graph = builder.compile()
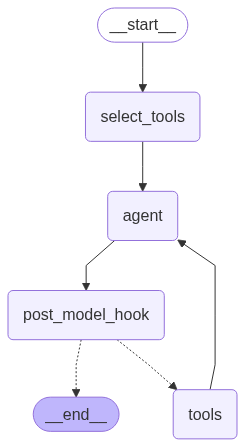
Visualizing the new graph, we see that the post-model hook has been added after the Agent, so all of the Agent’s internal LLM responses have their trustworthiness scored by TLM.
display(Image(graph.get_graph().draw_mermaid_png()))
Let’s run the Agent with trust scoring in place.
user_input = "Can you give me some information about AMD in 2022?"
result = graph.invoke({"messages": [("user", user_input)]})
for message in result["messages"]:
message.pretty_print()
With trust scoring in place, we see that the Agent realizes that $100 revenue for a company like AMD is untrustworthy and will tell the user as such.
Conclusion
This tutorial demonstrated how you can score LLM trustworthiness in any pre-built LangGraph Agent. In the Agentic systems we showcased here, low trust scores were handled via an automated internal message to the Agent asking it to re-generate its previous response to be more trustworthy. This accuracy-boosting technique is only one of many possible fallback mechanisms (replace with canned response like Sorry I don’t know, escalate to human, restart the Agent, etc).
To see different fallbacks you can implement when TLM trust scores are low, along with trust scoring in a custom LangGraph Agent built from scratch, check out our Trustworthy Custom Agents tutorial.