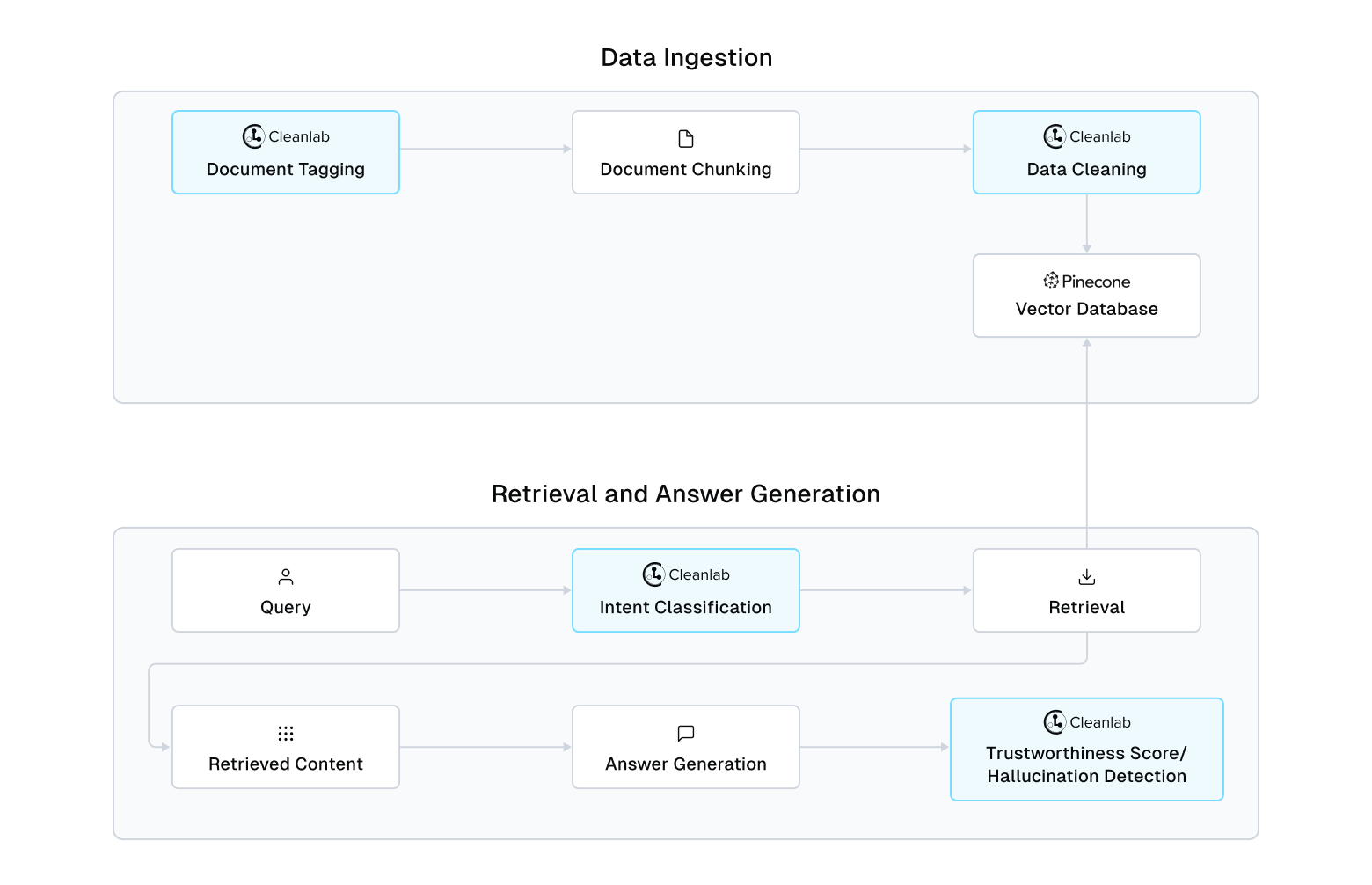
Curating data with TLM for more reliable Retrieval-Augmented Generation

Beyond real-time response evaluation and hallucination detection, Cleanlab’s Trustworthy Language Model (TLM) can additionally improve any RAG system via document/chunk tagging to ensure data quality and efficient retrieval of relevant information. This tutorial showcases this using Pinecone as a Vector Database, but the same concepts apply to any vector DB and RAG system. This tutorial covers:
- Using TLM to tag and clean document data, removing low-quality chunks and personally identifiable information (PII).
- Leveraging Pinecone to create and manage a vector database for storing and retrieving document embeddings.
- Implementing a RAG pipeline that uses both tools to provide accurate and trustworthy responses.
- Utilizing TLM to classify metadata, enhance retrieval, and evaluate the trustworthiness of RAG outputs.
This tutorial requires a TLM API key. Get one here, and first complete the Trustworthy RAG tutorial.
Let’s install the required Python packages for this tutorial:
%pip install pinecone-client==5.0.1 sentence-transformers==3.0.1 cleanlab-tlm
# Set your API key
import os
os.environ["CLEANLAB_TLM_API_KEY"] = "<API key>" # Get your free API key from: https://tlm.cleanlab.ai/
import pandas as pd
import time
import warnings
import pinecone
import uuid
from pinecone import ServerlessSpec
from sentence_transformers import SentenceTransformer
from typing import List, Tuple, Dict, Optional
from difflib import SequenceMatcher
import re
warnings.simplefilter(action="ignore", category=FutureWarning)
if "PINECONE_API_KEY" not in os.environ:
os.environ["PINECONE_API_KEY"] = input("Please enter your Pinecone API key: ")
Below is an example of how to set a Python index serverless specification, this allows us to define the cloud provider and region where we want to deploy our index. You can find a list of all available providers and regions here.
cloud = os.environ.get("PINECONE_CLOUD") or "aws"
region = os.environ.get("PINECONE_REGION") or "us-east-1"
spec = ServerlessSpec(cloud=cloud, region=region)
Fetch and Load Documents Data
First let’s fetch the dataset.
wget -nc https://cleanlab-public.s3.amazonaws.com/Datasets/documents-RAG-demo.csv
Let’s read in our documents data that we will use in this workflow. The data columns include the filename of the document and the document text.
# Read in dataset
df = pd.read_csv("documents-RAG-demo.csv")
As you can see below, some of our documents may have missing text while others do not.
df.head()
| index | filename | text | |
|---|---|---|---|
| 0 | 0 | documents/Blackstone-Third-Quarter-2023-Invest... | Blackstone Third Quarter 2023 Investor Call Oc... |
| 1 | 1 | documents/8k-nike.pdf | SECURITIES AND EXCHANGE COMMISSIONFORM 8-K Cur... |
| 2 | 2 | documents/FY24-Q1-NIKE-Press-Release.pdf | NaN |
| 3 | 3 | documents/10-K 2022-Apple2.pdf | The future principal payments for the Company’... |
| 4 | 4 | documents/q3-fy22-earnings-presentation.pdf | Financial\tpresentation\tto\t accompany\tmanag... |
Use TLM to tag your documents with a topic
For our RAG system, it would be ideal to tag each of our documents with a particular topic that is most relevant (based on the text content), which can be used as metadata we can filter with during retrieval in our RAG system.
We can now use the Trustworthy Language Model (TLM) to tag our document chunks with the correct document topic that we can later use to enhance our retrieval process of fetching the correct context from our vector DB.
TLM is a more reliable LLM that gives high-quality outputs and indicates when it is unsure of the answer to a question, making it suitable for applications where unchecked hallucinations are a show-stopper.
Using TLM
Here we initialize TLM using a more powerful configuration.
from cleanlab_tlm import TLM
# Use more powerful OpenAI model with TLM
tlm = TLM(quality_preset="high", options={"model": "gpt-4o"})
output = tlm.prompt("<your prompt>")
Let’s now use TLM to classify the text (tag) into different topics, using code from the TLM Zero-Shot Classification Tutorial. This includes helper functions parse_category() and classify() defined below.
Optional: Define helper functions to extract categories from the LLM output and classify texts into categories
def parse_category(
response: str,
categories: List[str],
disable_warnings: bool = False
) -> str:
"""
Extracts one of the provided categories from the response using regex patterns.
If no category out of the possible categories is directly mentioned in the response,
the category with greatest string similarity to the response is returned (along with a warning).
Args:
response (str): Response from the LLM
categories (List[str]): List of expected categories
disable_warnings (bool): If True, print warnings are disabled
Returns:
str: The extracted or best-matching category
"""
response_str = str(response)
escaped_categories = [re.escape(output) for output in categories]
categories_pattern = "(" + "|".join(escaped_categories) + ")"
exact_matches = re.findall(categories_pattern, response_str, re.IGNORECASE)
if len(exact_matches) > 0:
return str(exact_matches[-1])
best_match = max(
categories, key=lambda x: SequenceMatcher(None, response_str, x).ratio()
)
similarity_score = SequenceMatcher(None, response_str, best_match).ratio()
if similarity_score < 0.5:
warning_message = f"None of the categories remotely match raw LLM output: {response_str}.\nReturning the last entry in the constrain outputs list."
best_match = categories[-1]
else:
warning_message = f"None of the categories match raw LLM output: {response_str}"
if not disable_warnings:
warnings.warn(warning_message)
return best_match
def classify(texts: List[str], categories: List[str], prompt_template: str) -> Tuple[List[str], List[float]]:
"""
Classifies a list of texts into predefined categories using a language model.
Args:
texts (List[str]): List of texts to classify
categories (List[str]): List of possible categories
prompt_template (str): Template string for formatting the prompt
Returns:
Tuple[List[str], List[float]]: A tuple containing two lists:
- List of predicted categories for each text
- List of trustworthiness scores for each prediction
"""
prompts = [prompt_template.format(text=text) for text in texts]
outputs = tlm.prompt(prompts)
responses = [output['response'] for output in outputs]
trustworthiness_scores = [output['trustworthiness_score'] for output in outputs]
predictions = [parse_category(response, categories) for response in responses]
return predictions, trustworthiness_scores
Now we can define the prompt and categories we will use to tag our documents with the correct topic.
# Use TLM to tag your documents with a topic
tagging_prompt = """
You are an assistant for tagging text as one of several topics. The available topics are:
1. 'finance': Related to financial matters, budgeting, accounting, investments, lending, or monetary policies.
2. 'hr': Pertaining to Human Resources, including hiring, employee documents (such as a W4 form), employee management, benefits, or workplace policies.
3. 'it': Covering Information Technology topics such as software development, network infrastructure, cybersecurity, or tech support.
4. 'product': Dealing with a specific company product, product development, management, features, or lifecycle.
5. 'sales': Involving selling a product, customer acquisition, revenue generation, or sales performance.
If you are not sure which topic to tag the text with, then answer 'unknown'. Only use the lower case text version of the topic name.
Task: Analyze the following text and determine the topic it belongs to. Return the topic as a string.
Now here is the Text to verify:
Text: {text}
Topic:
"""
categories = ['finance', 'hr', 'it', 'product', 'sales', 'unknown']
Next we will use our helper functions to tag our documents with the correct topic.
predictions, trustworthiness_scores = classify(df["text"].tolist(), categories, tagging_prompt)
topics_df = df.copy()
topics_df['topic'] = predictions
topics_df['topic_trustworthiness'] = trustworthiness_scores
# Display results
topics_df.head()
| index | filename | text | topic | topic_trustworthiness | |
|---|---|---|---|---|---|
| 0 | 0 | documents/Blackstone-Third-Quarter-2023-Invest... | Blackstone Third Quarter 2023 Investor Call Oc... | finance | 0.985678 |
| 1 | 1 | documents/8k-nike.pdf | SECURITIES AND EXCHANGE COMMISSIONFORM 8-K Cur... | finance | 0.947063 |
| 2 | 2 | documents/FY24-Q1-NIKE-Press-Release.pdf | NaN | unknown | 0.963138 |
| 3 | 3 | documents/10-K 2022-Apple2.pdf | The future principal payments for the Company’... | finance | 0.952134 |
| 4 | 4 | documents/q3-fy22-earnings-presentation.pdf | Financial\tpresentation\tto\t accompany\tmanag... | finance | 0.985763 |
As seen above, after running classify(), you will notice two new columns in the dataset:
topic, a column with the response that we prompted fortopic_trustworthiness, a corresponding trustworthiness score, quantifying how confident you can be that the response is correct
Now we can use TLM’s trustworthiness score (obtained in our results as topic_trustworthiness) to see which of our automatically-produced topic tags are the most trustworthy and least trustworthy.
For cases where the topic_trustworthiness is low, we’ll replace the topic value with unknown since we can’t be sure to trust the predicted topic.
You can determine a good threshold by sorting the results by trustworthiness score and inspecting where topic values begin to appear consistently inaccurate.
Your team can alternatively review low-trustworthiness LLM responses and manually provide a better response instead.
sorted_topic_df = topics_df.sort_values(
by="topic_trustworthiness", ascending=False
).copy()
sorted_topic_df.head(10)
| index | filename | text | topic | topic_trustworthiness | |
|---|---|---|---|---|---|
| 31 | 31 | documents/hiring-process-infographic.pdf | County of Santa ClaraHiring Options For Manage... | hr | 0.998459 |
| 97 | 97 | documents/sales-process.pptx | The Sales Process and Techniques Marketing Pri... | sales | 0.998156 |
| 102 | 102 | documents/the-selling-process-1.pdf | ObjectiveThe nature of the customer.\tGenerall... | sales | 0.996991 |
| 95 | 95 | documents/the-selling-process-2.pdf | ObjectivePreparing to sell No\tmatter\twhat\tp... | sales | 0.994916 |
| 101 | 101 | documents/best- buy-sales-doc.docx | Essential Sales Strategies - Closing the DealT... | sales | 0.994565 |
| 96 | 96 | documents/selling-on-amazon-welcome.pdf | The beginner’s guide toSelling on AmazonWelcom... | sales | 0.990125 |
| 63 | 63 | documents/TecNewEquipmentRequest.pdf | Grade Level/Dept StaffYes Cost: ______________... | it | 0.988642 |
| 75 | 75 | documents/plug-test-caps.pdf | Plug-On Test Caps Product SpecificationsFEATUR... | product | 0.988273 |
| 4 | 4 | documents/q3-fy22-earnings-presentation.pdf | Financial\tpresentation\tto\t accompany\tmanag... | finance | 0.985763 |
| 0 | 0 | documents/Blackstone-Third-Quarter-2023-Invest... | Blackstone Third Quarter 2023 Investor Call Oc... | finance | 0.985678 |
sorted_topic_df.tail(10)
| index | filename | text | topic | topic_trustworthiness | |
|---|---|---|---|---|---|
| 80 | 80 | documents/product-instructions-oven.docx | Talking Combination Oven ES7253Product Instruc... | product | 0.931520 |
| 64 | 64 | documents/internet_safety.pptx | INTERNET SAFETYIntervention and PreventionTrai... | it | 0.924140 |
| 14 | 14 | documents/RetailMailings.doc | Fidelity Investments FundsNetworkProcedures f... | finance | 0.899811 |
| 20 | 20 | documents/UnreleasedGames.doc | EVERY GAME THAT WAS NEVER RELEASED FOR THE SPE... | unknown | 0.847405 |
| 56 | 56 | documents/K-5-internet_safety.ppt | INTERNET SAFETYWhat is the Internet &Why is it... | it | 0.838359 |
| 84 | 84 | documents/smp-application-table.docx | Streaming Media Player ApplicationPlease revie... | product | 0.814944 |
| 58 | 58 | documents/ElectricalRequestForm.pdf | Use this form to request parts and equipment f... | unknown | 0.768220 |
| 59 | 59 | documents/internetsafety.ppt | Santa Rosa District SchoolsINTERNET SAFETYNove... | unknown | 0.729705 |
| 8 | 8 | documents/LD_Trucost_Company_Presentation_0504... | Quantitative Environmental Performance Measure... | finance | 0.726891 |
| 35 | 35 | documents/Research-Assistant.pdf | Job Description and Responsibilities forResear... | product | 0.544833 |
After sorting the results in descending order by the topic_trustworthiness score, the results seem to be less trustworthy for scores less than 0.8.
Let’s replace each of these less trustworthytopic responses with unknown now.
topics_df.loc[topics_df["topic_trustworthiness"] < 0.8, "topic"] = (
"unknown"
)
To get a sense of the distribution of topics we’ve tagged in our documents data, let’s look at the distribution now:
topic_counts = topics_df["topic"].value_counts(dropna=False)
print(f"\nTopic Column Distribution:\n{topic_counts}")
# Percentage distribution of topics
topic_percentages = topics_df["topic"].value_counts(normalize=True) * 100
print(f"\nTopic Percentage Distribution:\n{topic_percentages}")
Initialize RAG Pipeline using our documents data
Optional: Define PineconeRAGPipeline class to index and search documents using Pinecone
class PineconeRAGPipeline:
def __init__(
self,
model_name: str = "paraphrase-MiniLM-L6-v2",
index_name: str = "document-index",
cloud: str = "aws",
region: str = "us-east-1",
):
"""
Initialize the PineconeRAGPipeline with a specified model and index name.
Args:
model_name (str): Name of the SentenceTransformer model to use.
index_name (str): Name of the Pinecone index to create or connect to.
cloud (str): Cloud provider for Pinecone.
region (str): Region for the Pinecone service.
"""
self.model = SentenceTransformer(model_name)
if not os.environ.get("PINECONE_API_KEY"):
os.environ["PINECONE_API_KEY"] = "YOUR PINECONE API KEY HERE"
self.pc = pinecone.Pinecone(api_key=os.environ.get("PINECONE_API_KEY"))
self.index_name = index_name
existing_indexes = self.pc.list_indexes()
if self.index_name not in existing_indexes:
try:
print(f"Creating new index: {self.index_name}")
self.pc.create_index(
name=self.index_name,
dimension=self.model.get_sentence_embedding_dimension(),
metric="cosine",
spec=pinecone.ServerlessSpec(cloud=cloud, region=region),
)
except Exception as e:
if "ALREADY_EXISTS" in str(e):
print(
f"Index {self.index_name} already exists. Connecting to existing index."
)
else:
raise e
else:
print(
f"Index {self.index_name} already exists. Connecting to existing index."
)
self.index = self.pc.Index(self.index_name)
def chunk_text(self, text: str, max_tokens: int = 256) -> List[str]:
"""
Split text into chunks based on a maximum token size.
Args:
text (str): The document text to be chunked.
max_tokens (int): The maximum number of tokens per chunk.
Returns:
List[str]: List of text chunks.
"""
words = text.split()
chunks = []
current_chunk = []
current_chunk_tokens = 0
for word in words:
word_tokens = len(self.model.tokenize([word])["input_ids"][0])
if current_chunk_tokens + word_tokens > max_tokens and current_chunk:
chunks.append(" ".join(current_chunk))
current_chunk = []
current_chunk_tokens = 0
current_chunk.append(word)
current_chunk_tokens += word_tokens
if current_chunk:
chunks.append(" ".join(current_chunk))
for i, chunk in enumerate(chunks):
print(
f"Chunk {i+1} length: {len(chunk)} characters, "
f"{len(self.model.tokenize([chunk])['input_ids'][0])} tokens"
)
return chunks
def index_documents(self, df: pd.DataFrame) -> int:
"""
Index documents from a DataFrame with specific metadata structure.
Args:
df (pd.DataFrame): DataFrame containing document information and metadata.
Expected columns: 'text', 'filename', 'topic'
Returns:
int: The number of chunks successfully indexed.
"""
valid_docs = []
valid_metadata = []
generated_ids = []
print("Starting document processing...")
for idx, row in df.iterrows():
if pd.isna(row["text"]) or pd.isna(row["filename"]) or pd.isna(row["topic"]):
print(f"Skipping invalid document at index {idx}: {row['filename']}")
continue
doc = str(row["text"])
print(f"Processing document {row['filename']} at index {idx}...")
chunks = self.chunk_text(doc)
for i, chunk in enumerate(chunks):
chunk_id = str(uuid.uuid4())
chunk_metadata = {
"filename": row["filename"],
"topic": row["topic"],
"chunk_index": i,
"total_chunks": len(chunks),
"chunk_id": chunk_id,
}
valid_docs.append(chunk)
valid_metadata.append(chunk_metadata)
generated_ids.append(chunk_id)
print(f"Total chunks to encode: {len(valid_docs)}")
if not valid_docs:
print("No valid documents to index.")
return 0
doc_embeddings = self.model.encode(valid_docs)
batch_size = 100
for i in range(0, len(valid_docs), batch_size):
batch_docs = valid_docs[i : i + batch_size]
batch_metadata = valid_metadata[i : i + batch_size]
batch_embeddings = doc_embeddings[i : i + batch_size]
vectors = [
(
generated_ids[i + j],
embedding.tolist(),
{**metadata, "text": doc[:1000]},
)
for j, (doc, embedding, metadata) in enumerate(
zip(batch_docs, batch_embeddings, batch_metadata)
)
]
try:
self.index.upsert(vectors=vectors)
print(f"Successfully indexed batch of {len(vectors)} chunks.")
except Exception as e:
print(f"Error during upsert: {e}")
print("Document indexing completed.")
return len(valid_docs)
def search(
self, query: str, top_k: int = 5, filter_query: Optional[Dict] = None
) -> List[Tuple[str, Dict]]:
"""
Search for the top_k most relevant documents based on the input query and optional filter.
Args:
query (str): The search query text.
top_k (int): The number of top relevant documents to return.
filter_query (Optional[Dict]): Optional filter query to apply during search.
Returns:
List[Tuple[str, Dict]]: List of top_k relevant document texts and their metadata.
Each tuple contains (document_text, metadata_dict).
"""
query_embedding = self.model.encode(query)
try:
results = self.index.query(
vector=query_embedding.tolist(),
top_k=top_k,
filter=filter_query,
include_metadata=True,
)
return [
(
match.metadata["text"],
{k: v for k, v in match.metadata.items() if k != "text"},
)
for match in results.matches
]
except Exception as e:
print(f"Error during search: {e}")
return []
def delete_index(self) -> None:
"""
Delete the Pinecone index.
Raises:
Exception: If there's an error during the deletion process.
"""
try:
self.pc.delete_index(self.index_name)
print(f"Index '{self.index_name}' has been deleted.")
except Exception as e:
print(f"Error deleting index: {e}")
def extract_all_chunks_from_index(self, max_chunks: int = 10000) -> pd.DataFrame:
"""
Extract all document chunks and metadata from the Pinecone index into a DataFrame.
Args:
max_chunks (int): Maximum number of chunks to retrieve.
Returns:
pd.DataFrame: DataFrame containing chunk data and metadata.
Columns include all metadata fields stored in the index.
Raises:
Exception: If there's an error retrieving chunks from the index.
"""
stats = self.index.describe_index_stats()
total_vectors = stats.total_vector_count
dimension = stats.dimension
print(f"Index name: {self.index_name}")
print(f"Total vectors according to stats: {total_vectors}")
print(f"Vector dimension: {dimension}")
try:
results = self.index.query(
vector=[0.0] * dimension,
top_k=max_chunks,
include_values=False,
include_metadata=True,
)
chunk_data = [match.metadata for match in results.matches]
chunk_df = pd.DataFrame(chunk_data)
print(f"Total chunks retrieved: {len(chunk_df)}")
return chunk_df
except Exception as e:
print(f"Error retrieving chunks from index: {e}")
return pd.DataFrame()
def delete_chunks(self, chunk_ids: List[str]) -> None:
"""
Delete specific chunks from the Pinecone index.
Args:
chunk_ids (List[str]): List of chunk IDs to delete.
Raises:
Exception: If there's an error during the deletion process.
"""
try:
self.index.delete(ids=chunk_ids)
print(f"Successfully deleted {len(chunk_ids)} chunks from the index.")
except Exception as e:
print(f"Error deleting chunks: {e}")
print(f"Problematic chunk IDs: {chunk_ids}")
print(f"Finished deletion process for {len(chunk_ids)} chunks.")
Let’s use the RAG pipeline we have defined above to create a Pinecone index - then we upsert our document chunks into our vector DB in batches.
# Create RAG pipeline on unfiltered documents
rag_pipeline = PineconeRAGPipeline(index_name="cleanlab-pinecone-index")
rag_pipeline.index_documents(topics_df)
After upserting our document chunks, let’s now confirm that the upsertion worked properly (after waiting 30 seconds to give the vector DB time to update) by reading the document chunks into a new DataFrame chunk_df.
time.sleep(30)
# Extract chunks from the Pinecone index into a DataFrame
chunk_df = rag_pipeline.extract_all_chunks_from_index()
# Display the resulting DataFrame
chunk_df.head()
| chunk_id | chunk_index | filename | text | topic | total_chunks | |
|---|---|---|---|---|---|---|
| 0 | 93b8208c-ed08-4dca-bc3a-f0a3a851e647 | 4.0 | documents/Walmart_2022_Investor_Information.pdf | follows:2023HighLow1st Quarter(1)$146.94$132.0... | finance | 9.0 |
| 1 | c77a729a-2099-4563-b9f6-95bbe91b57a1 | 5.0 | documents/2012_14.doc | Pay transactions on HUE01 using the following ... | hr | 17.0 |
| 2 | 5509e93a-bfe6-4692-a793-b68999e62bd2 | 5.0 | documents/internet_safety.pptx | 751-5980 (800) 487-1626 (8 a.m. to 5 p.m. CST,... | it | 6.0 |
| 3 | 6352bd45-9d99-4f86-98e9-26edd34ce6ce | 139.0 | documents/Investor_Transcript_2023-10-26.pdf | PROVIDE AN ACCURATE TRANSCRIPTION, THERE MAY B... | finance | 141.0 |
| 4 | a21c6510-2a56-4a1f-89ee-17da5d2f3994 | 12.0 | documents/2012_14.doc | When entering deduction override amounts for a... | hr | 17.0 |
# Confirm number of chunks matches the number of rows in the DataFrame
chunk_df.shape
document_data_columns = list(chunk_df.columns)
print(f"The columns in our documents data are: {document_data_columns}")
We can see below that the number of chunks per document varies:
chunks_per_doc = chunk_df.groupby("filename")["chunk_index"].max() + 1
print(chunks_per_doc)
Use TLM to detect and filter out bad document chunks
Now that we have extracted our document chunks from our Pinecone index, let’s use TLM (via the helper functions we defined earlier to tag documents) to detect low quality document chunks (i.e. HTML, not interpretable/cut off phrases, or non English text) and personally identifiable information (PII) to filter out these chunks from our vector DB.
Below we define the prompts we will use to find the document chunks that are badly chunked or contain PII and run our classify() helper function to obtain the response and trustworthiness scores from TLM.
# Bad chunks detection (you can replace this with your own definitions)
bad_chunks_prompt = """
I am chunking documents into smaller pieces to create a knowledge base for question-answering systems.
Task: Help me check if the following Text is badly chunked. A badly chunked text is any text that is: full of HTML/XML and other non-language strings or non-english words, has hardly any informative content or missing key information, or text that contains Personally-Identifiable Information (PII) and other sensitive confidential information.
Return 'bad_chunk' if the provided Text is badly chunked, and 'good_chunk' otherwise. Please be as accurate as possible, the world depends on it.
Text: {text}
"""
bad_chunk_categories = ["bad_chunk", "good_chunk"]
bad_chunk_predictions, bad_chunk_scores = classify(chunk_df["text"].tolist(), bad_chunk_categories, bad_chunks_prompt)
chunk_df['chunk_quality'] = bad_chunk_predictions
chunk_df['chunk_quality_trustworthiness'] = bad_chunk_scores
# PII detection
pii_prompt = """
I am chunking documents into smaller pieces to create a knowledge base for question-answering systems.
Task: Analyze the following text and determine if it has personally identifiable information (PII). PII is information that could be used to identify an individual or is otherwise sensitive. Names, addresses, phone numbers are examples of common PII.
Return 'is_PII' if the text contains PII and 'no_PII' if it does not. Please be as accurate as possible, the world depends on it.
Text: {text}
"""
pii_categories = ["is_PII", "no_PII"]
pii_predictions, pii_scores = classify(chunk_df["text"].tolist(), pii_categories, pii_prompt)
chunk_df['pii_check'] = pii_predictions
chunk_df['pii_check_trustworthiness'] = pii_scores
sorted_chunk_quality_df = chunk_df.sort_values(
by="chunk_quality_trustworthiness", ascending=False
).copy()
sorted_is_pii_df = chunk_df.sort_values(
by="pii_check_trustworthiness", ascending=False
).copy()
Now let’s check how many document chunks are bad chunks or contain PII but also in which the response trustworthiness score is >= 0.95, which represent the most trustworthy responses using TLM.
worst_chunks = sorted_chunk_quality_df.query(
"chunk_quality == 'bad_chunk' and chunk_quality_trustworthiness >= 0.95"
)
worst_pii = sorted_is_pii_df.query(
"pii_check == 'is_PII' and pii_check_trustworthiness >= 0.95"
)
print(
f"Number of document chunks that have the worst chunk quality based on trustworthiness: {worst_chunks.shape[0]}"
)
print(
f"Number of document chunks have the worst PII based on trustworthiness: {worst_pii.shape[0]}"
)
We have observed the capabilities that TLM can provide in detecting these low quality document chunks, so let’s now:
- Update our Pinecone DB by removing the chunks with any of the issues detected by TLM
- Verify that the update to our Pinecone DB worked
Let’s observe some of the worst chunks that we are going to delete:
print(worst_chunks["text"][1311])
print("\n")
print(worst_chunks["text"][2065])
These chunks are clearly not easy to understand nor do they represent full English phrases.
Now let’s observe some of the worst examples of PII that we are going to delete:
print(worst_pii["text"][531])
print("\n")
print(worst_pii["text"][1081])
These examples contain sensitive information such as phone numbers, email addresses and personal names that are flagged by Cleanlab - so these definitely contain PII that can be removed!
We can now construct the list of chunks to delete based on the chunk_id we previously created for each chunk that we can tie to each chunk in our vector DB.
# Get the chunk IDs for the chunks that have issues to update our Pinecone index
worst_chunks_to_delete_ids = worst_chunks["chunk_id"].tolist()
worst_pii_to_delete_ids = worst_pii["chunk_id"].tolist()
chunks_to_delete_ids = list(set(worst_chunks_to_delete_ids + worst_pii_to_delete_ids))
# Number of chunks to delete
len(chunks_to_delete_ids)
# Delete the identified chunks from the index
rag_pipeline.delete_chunks(chunks_to_delete_ids)
After deleting our document chunks, let’s now confirm that the deletion worked properly (after waiting 30 seconds to give the vector DB time to update) by reading the document chunks into a new DataFrame updated_chunk_df.
We will also then confirm the number of chunks deleted is equal to the total number of original chunks minus the number of chunks after filtering out bad chunks.
# Sleep timer to allow the deletion process to complete
time.sleep(30)
# Verify the update went through and we have the correct number of chunks
updated_chunk_df = rag_pipeline.extract_all_chunks_from_index()
updated_chunk_df.head()
| chunk_id | chunk_index | filename | text | topic | total_chunks | |
|---|---|---|---|---|---|---|
| 0 | 5d6cff8b-a53f-4f60-a2a6-60b46417560d | 2.0 | documents/Blackstone-Third-Quarter-2023-Invest... | release and slide presentation, which are avai... | finance | 127.0 |
| 1 | c1143934-3f34-4099-b452-6cc1a8036c2c | 3.0 | documents/Blackstone-Third-Quarter-2023-Invest... | 10-K We'll also refer to certain non-GAAP meas... | finance | 127.0 |
| 2 | afe8ca91-78cb-4851-8f92-b8e682dbb3da | 4.0 | documents/Blackstone-Third-Quarter-2023-Invest... | $1.2 billion, or $0.94 per common share, and w... | finance | 127.0 |
| 3 | a6026edc-c32b-4ef2-baea-23bcdb0a2ba9 | 5.0 | documents/Blackstone-Third-Quarter-2023-Invest... | shared human values, and we are deeply saddene... | finance | 127.0 |
| 4 | df61e9a8-7518-44a7-98a6-57a912e1e418 | 6.0 | documents/Blackstone-Third-Quarter-2023-Invest... | year-to-year basis. Higher interest rates, alo... | finance | 127.0 |
# Confirm the number of chunks deleted is equal to the total number of original chunks minus the number of chunks after filtering out bad chunks
assert len(chunk_df) - len(updated_chunk_df) == len(chunks_to_delete_ids)
Note: You can also run this data ingestion (tagging, chunking, and cleaning) into a Pinecone vector DB index in real-time as new documents are being ingested.
How to search for documents with metadata
Below is an example on how you can search for your curated documents based on a query of your choice and use metadata to help filter for the relevant information.
In this case, we specify topic = sales to find the top k (where k is number of results to return and equal to 2 here) documents that best match the search query/metadata filters.
results = rag_pipeline.search(
query="Tell me about sales", # YOUR SEARCH QUERY HERE
top_k=2,
filter_query={"topic": {"$eq": "sales"}},
)
for doc_text, metadata in results:
print(f"Document: {doc_text[:100]}...")
print(f"Metadata: {metadata}")
print("-" * 500)
Use TLM for intent classification of queries
Suppose our user is asked which topic their question is about from a pre-defined list. Alternatively, we could train a classifier to predict the topic from the question (automatically using TLM). This way, the intent classification is done automatically (and reliably) to obtain our topic that pertains to a user question. This topic can then be used for metadata filtering when querying against our vector DB.
# Intent classification
intent_classification_prompt = """
You are an assistant for classifying a question as one of several topics. The available topics are:
1. 'finance': Related to financial matters, budgeting, accounting, investments, lending, or monetary policies.
2. 'hr': Pertaining to Human Resources, including hiring, employee documents (such as a W4 form), employee management, benefits, or workplace policies.
3. 'it': Covering Information Technology topics such as software development, network infrastructure, cybersecurity, or tech support.
4. 'product': Dealing with a specific company product, product development, management, features, or lifecycle.
5. 'sales': Involving selling a product, customer acquisition, revenue generation, or sales performance.
If you are not sure which topic to classify the question as, then answer 'unknown'. Only use the lower case text version of the topic name.
Task: Analyze the following question and determine the topic it belongs to. Return the topic as a string.
Now here is the question to verify:
Text: {text}
Topic:
"""
question = "What were Blackstone's fee-related earnings in the third quarter of 2023?"
Using the question and prompt defined above, let’s now use TLM to classify the question into the correct topic (intent classification) that we will use as the metadata to filter our vector DB query with:
intent_predictions, intent_trustworthiness_scores = classify([question], categories, intent_classification_prompt)
metadata_topic_response = {
"metadata_response": intent_predictions[0],
"metadata_trustworthiness_score": intent_trustworthiness_scores[0]
}
print(metadata_topic_response)
# Extract the topic from the response
metadata_topic = metadata_topic_response["metadata_response"]
Below, you can then specify the classified metadata topic (or other relevant metadata) when filtering to help search for the relevant context in your Pinecone index.
Since we don’t know where to stick the documents with an unknown topic value, we will always include the unknown topic in the filter.
# Define the list of topics to filter on
topic_filter = [metadata_topic, "unknown"]
# Use the classified topic to filter the search results
top_doc_chunk = rag_pipeline.search(
question, top_k=1, filter_query={"topic": {"$in": topic_filter}}
)
print(f"Top document chunk for this query: \n\n{top_doc_chunk[0][0]}")
Use TLM to get Trustworthiness Score for RAG Outputs
Now let’s use the context from our top document chunk we obtained in the previous step to actually answer the original question asked: What were Blackstone's fee-related earnings in the third quarter of 2023?
top_doc_chunks = "".join(
rag_pipeline.search(
question, top_k=1, filter_query={"topic": {"$in": topic_filter}}
)[0][0]
)
prompt = f"""You are an assistant for answering the following question based on the document context.
Question: {question}
Document Context: {top_doc_chunks}
"""
Now let’s query TLM using the prompt we previously created using our user query + document context passed from our RAG Pinecone index.
output = tlm.prompt(prompt)
output
Is this response correct?
text_to_check = updated_chunk_df.query("filename == 'documents/Blackstone-Third-Quarter-2023-Investor-Call.pdf' and text.str.contains('of year-over-year base management fee', case=False, na=False)").iloc[0]["text"]
text_to_check[60:119]
Can we find a hallucination?
Let’s now try to find a hallucination but first classify the intent of this new question into the correct metadata topic value.
question = "Can you tell me if these Good's Homestyle Potato Chips support 9 per row in the case?"
intent_predictions, intent_trustworthiness_scores = classify([question], categories, intent_classification_prompt)
metadata_topic_response = {
"metadata_response": intent_predictions[0],
"metadata_trustworthiness_score": intent_trustworthiness_scores[0]
}
print(metadata_topic_response)
# Extract the topic from the response
metadata_topic = metadata_topic_response["metadata_response"]
Now we can pass the question and context into our prompt to catch this hallucination.
# Define the list of topics to filter on
topic_filter = [metadata_topic, "unknown"]
top_doc_chunks = "".join(
rag_pipeline.search(
question, top_k=1, filter_query={"topic": {"$in": topic_filter}}
)[0][0]
)
prompt = f"""You are an assistant for answering the following question based on the document context.
Question: {question}
Document Context: {top_doc_chunks}
"""
# Run TLM
tlm = TLM()
output = tlm.prompt(prompt)
output
Is this correct?
There are 24 chip bags per case which cannot support 9 per row, so this is a hallucination.
text_to_check = updated_chunk_df.query("filename == 'documents/potato-chips-specs.pdf'").iloc[0]["text"]
text_to_check[113:139]
Apply TLM to Existing RAG Prompt/Response Pairs
If you have a RAG system in which you already have retrieved the context and obtained a response from your LLM, you can still generate a trustworthiness score for these responses via TLM’s get_trustworthiness_score() method.
tlm = TLM(quality_preset="high", options={"model": "gpt-4o"})
prompt = """Based on the following documents, answer the given question.
Documents: We're getting new desks! Specs are here: Staples Model RTG120XLDBL BasePage \
CollectionModel | Dimensions width = 60.0in height = 48.0in depth = 24.0in Base Color Black \
Top Color White | Specs SheetsPowered by TCPDF (www.tcpdf.org)
Question: What is the width of the new desks?
"""
response_A = "60 inches"
response_B = "24 inches"
trust_score_A = tlm.get_trustworthiness_score(prompt, response_A)
trust_score_B = tlm.get_trustworthiness_score(prompt, response_B)
print(f"TLM Score for Response A: {trust_score_A}")
print(f"TLM Score for Response B: {trust_score_B}")
The trustworthiness score for the correct response is much higher than the incorrect response.
To summarize, we used TLM to curate the knowledge base data of a RAG system, tagging documents with metadata that enhances overall reliability. While this tutorial used Pinecone as the vector database, the same approach applies to any other vector database and RAG system.
Learn more about leveraging TLM in RAG applications via our Trustworthy RAG with TLM tutorial and cheatsheet.