Data Annotation/Labeling with TLM

This tutorial demonstrates how to auto-label data using Cleanlab’s Trustworthy Language Model (TLM) and save human data annotation costs. The TLM trustworthiness scores reveal which subset of data the LLM can confidently handle. Let the LLM auto-label 99% of cases where it is trustworthy, and manually label the remaining 1%.
Also TLM can automatically produce higher-accuracy annotations than your base LLM model, if you run it with a higher number of num_candidate_responses (specified in TLMOptions).
This tutorial demonstrates the following types of annotation tasks: text classification, document tagging, and entity recognition (useful for PII detection or information extraction). You can similarly use TLM for any data annotation task that you think LLMs might be able to automate, including tasks with complex structured labels.
Setup
This tutorial requires a TLM API key. Get one here.
Cleanlab’s Python client can be installed using pip. The last part of this tutorial additionally relies on the OpenAI client library.
%pip install --upgrade cleanlab-tlm openai matplotlib
# Set your API key
import os
os.environ["CLEANLAB_TLM_API_KEY"] = "<API key>" # Get your free API key from: https://tlm.cleanlab.ai/
import pandas as pd
import numpy as np
from openai import OpenAI
import matplotlib.pyplot as plt
pd.set_option('display.max_colwidth', None)
from cleanlab_tlm import TLM
tlm = TLM(quality_preset="low", options={"log": ["explanation"]})
Fetch classification dataset
Let’s consider a dataset composed of customer service messages received by a bank.
wget -nc https://cleanlab-public.s3.us-east-1.amazonaws.com/Datasets/tlm-annotation-tutorial/customer-service-text.csv
df = pd.read_csv("customer-service-text.csv")
df.head()
| text | |
|---|---|
| 0 | i need to cancel my recent transfer as soon as possible. i made an error there. please help before it goes through. |
| 1 | why is there a fee when i thought there would be no fees? |
| 2 | how do i replace my card before it expires next month? |
| 3 | what should i do if someone stole my phone? |
| 4 | please help me get a visa card. |
Our goal: annotate each of the customer messages as one of the following categories:
- cancel transaction
- fee charged
- card expire
- missing phone
- cards and currency
- spare card
- beneficiary not allowed
- change pin
- apple google mobile pay
- transfer
- other
This is a classification annotation task, where each example belongs to exactly one of the possible categories.
Apply TLM for classification
Let’s start with a basic way to have TLM automatically label each customer message. This basic approach is called zero-shot classification with LLMs.
customer_message = "I need to change my card's PIN"
prompt = f'''Given the following customer message, classify the message into one of the following categories: change pin, fee charged, or spare card. Please respond with the category only with no leading or trailing text.
Here is the customer message: {customer_message}'''
# Here we constrain the output to a set of possible categories.
response = tlm.prompt(prompt, constrain_outputs=["change pin", "fee charged", "spare card"])
print("Category:", response["response"])
print("Trustworthiness Score:", response["trustworthiness_score"])
print("Explanation:", response["log"]["explanation"])
You can also use TLM’s get_trustworthiness_score() method to evaluate existing annotations from your team / other models.
customer_message = "I need to change my card's PIN"
existing_label = "spare card"
prompt = f'''Given the following customer message, classify the message into one of the following categories: change pin, fee charged, or spare card. Please respond with the category only with no leading or trailing text.
Here is the customer message: {customer_message}'''
response = tlm.get_trustworthiness_score(prompt, existing_label)
print("Trustworthiness Score:", response["trustworthiness_score"])
print("Explanation:", response["log"]["explanation"])
Prompt Engineering
Let’s construct a descriptive prompt template for higher accuracy data annotation. In this prompt, we define each of the possible categories and provide a brief description of each category. You should ideally supply TLM with the same level of detail as you would include in annotation instruction for human labelers (describing how to handle certain edge cases, etc).
prompt_template = """
You are a professional customer service agent. You are given a customer's message and you are asked to classify the customer's message into one of the following categories:
- cancel transaction: The customer is requesting to cancel a transaction they recently made or is implicitly asking to cancel a transaction, i.e. they made a payment to a wrong account.
- fee charged: The customer is inquiring about a fee charged or disputing an unexpected fee or is missing money from a recent transaction.
- card expire: The customer needs assistance with a card that is expiring or expired soon.
- missing phone: The customer has lost their phone or is reporting a stolen phone.
- cards and currency: The customer is asking questions about card types, when where or how they can use their card, or currency related issues involving their card.
- spare card: The customer is requesting information about obtaining an additional or spare card.
- beneficiary not allowed: The customer is asking questions about beneficiary access issues.
- change pin: The customer needs help changing their card's PIN.
- apple google mobile pay: The customer is seeking assistance with Apple, Google or Mobile Pay functionality.
- transfer: The customer is asking about a transfer or a transfer related issue.
- other: The customer's message does not fit into any of the above categories.
Please respond with the category only with no leading or trailing text.
Here is the customer's message: {}
"""
# Construct prompt for each message to label.
all_prompts = [prompt_template.format(text) for text in df.text]
print(all_prompts[0])
Categorize all text examples with TLM
Let’s now apply TLM to auto-label the full dataset.
# Here we enumerate the set of possible categories.
valid_categories = [
"cancel transaction",
"fee charged",
"card expire",
"missing phone",
"cards and currency",
"spare card",
"beneficiary not allowed",
"change pin",
"apple google mobile pay",
"transfer",
"other"
]
# In a single prompt() call, we can annotate the entire dataset.
responses = tlm.prompt(all_prompts, constrain_outputs=valid_categories)
# Extract the categories, scores, and explanations from each response
categories = [response["response"] for response in responses]
scores = [response["trustworthiness_score"] for response in responses]
explanations = [response['log']["explanation"] for response in responses]
df["predicted_label"] = categories
df["trustworthiness"] = scores
df["explanation"] = explanations
df.head(3)
| text | predicted_label | trustworthiness | explanation | |
|---|---|---|---|---|
| 0 | i need to cancel my recent transfer as soon as possible. i made an error there. please help before it goes through. | cancel transaction | 1.000000 | Did not find a reason to doubt trustworthiness. |
| 1 | why is there a fee when i thought there would be no fees? | fee charged | 1.000000 | Did not find a reason to doubt trustworthiness. |
| 2 | how do i replace my card before it expires next month? | card expire | 0.995549 | Did not find a reason to doubt trustworthiness. |
Assess Performance (Optional)
In this section, we introduce ground-truth labels solely in order to evaluate the performance of TLM. These ground-truth labels are never provided to TLM, and this section can be skipped if you don’t have ground-truth labels).
wget -nc https://cleanlab-public.s3.us-east-1.amazonaws.com/Datasets/tlm-annotation-tutorial/customer-service-categories.csv
# Read in ground truth labels
ground_truth_labels = pd.read_csv("customer-service-categories.csv")
df['ground_truth_label'] = ground_truth_labels['label']
df.head(3)
| text | predicted_label | trustworthiness | explanation | ground_truth_label | |
|---|---|---|---|---|---|
| 0 | i need to cancel my recent transfer as soon as possible. i made an error there. please help before it goes through. | cancel transaction | 1.000000 | Did not find a reason to doubt trustworthiness. | cancel transaction |
| 1 | why is there a fee when i thought there would be no fees? | fee charged | 1.000000 | Did not find a reason to doubt trustworthiness. | fee charged |
| 2 | how do i replace my card before it expires next month? | card expire | 0.995549 | Did not find a reason to doubt trustworthiness. | card expire |
Next we plot the accuracy of the TLM-predicted labels (computed with respect to ground-truth labels). Here we assume annotations from TLM are only considered for the subset of data where the trustworthiness score is sufficiently high, so accuracy is only computed over this data subset (the remaining data could be manually reviewed/annotated by humans). Our plot depicts the resulting accuracy across different choices of the trustworthiness score threshold, which determine how much of the data gets auto-labeled by the LLM (see X-axis below).
Optional: Plotting code
# Calculate the number of examples, percentage of data, and accuracy of TLM's predictions for each threshold value
threshold_analysis = pd.DataFrame([{
"threshold": t,
"num_examples": len(filtered := df[df["trustworthiness"] > t]),
"percent_data": len(filtered) / len(df) * 100,
"accuracy": np.mean(filtered["predicted_label"] == filtered["ground_truth_label"]) * 100
} for t in np.arange(0, 1.0, 0.01)]).round(2)
# Plot the accuracy of TLM's predictions and percentage of data for each trustworthiness score threshold value
def create_enhanced_line_plot(threshold_analysis):
plt.figure(figsize=(8.25, 6.6))
points = plt.scatter(threshold_analysis['percent_data'], threshold_analysis['accuracy'],
c=threshold_analysis['threshold'], cmap='viridis', s=40) # Increased marker size
plt.plot(threshold_analysis['percent_data'], threshold_analysis['accuracy'],
alpha=0.3, color='gray', zorder=1, linewidth=2) # Increased line width
plt.colorbar(points).set_label('trustworthiness Threshold', fontsize=14) # Increased font size
plt.grid(True, alpha=0.3)
plt.xlabel('Percentage of Data Included', fontsize=14) # Increased font size
plt.ylabel('Classification Accuracy', fontsize=14) # Increased font size
plt.title('Accuracy vs Auto Labeling Threshold', fontsize=16) # Increased font size
plt.xticks(fontsize=14) # Increased tick label size
plt.yticks(fontsize=14) # Increased tick label size
plt.xlim(40)
plt.tight_layout()
return plt.gcf()
# Apply the function to your data
fig = create_enhanced_line_plot(threshold_analysis)
plt.show()
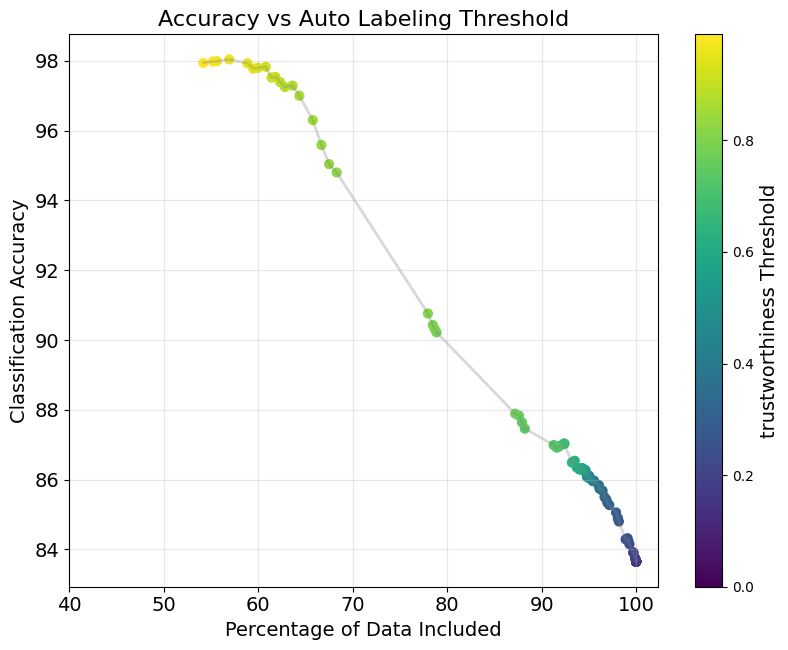
The above plot shows the accuracy of TLM predicted labels, if we only have the LLM handle the subset of the data where TLM’s trustworthiness score exceeds a certain threshold. This shows how TLM can ensure a target labeling accuracy for examples above a certain trustworthiness score. Your team can manually label the remainder of the data whose TLM trustworthiness score falls below a chosen threshold value.
For example, if we want to ensure that greater than 90% of the examples are labeled correctly (i.e. 90% accuracy on the Y axis), the plot above shows that we can let TLM auto-label all examples whose trustworthiness score exceeds 0.8 (the X-axis shows this happens to be nearly 80% of the data). In this case, your team only has to manually 20% of the data in order to get it all labeled with greater than 90% accuracy. TLM helps you effectively trade off between annotation cost savings vs. accuracy of the resulting anotations.
Least trustworthy examples
Let’s sort by the trustworthiness score and look at a few examples.
df.sort_values(by="trustworthiness", ascending=True).head(3)
| text | predicted_label | trustworthiness | explanation | ground_truth_label | |
|---|---|---|---|---|---|
| 243 | i want to apply for a visa card. | other | 0.151055 | . \nThis response is untrustworthy due to lack of consistency in possible responses from the model. Here's one inconsistent alternate response that the model considered (which may not be accurate either): \ncards and currency. | cards and currency |
| 121 | is it possible to access my phone from the hotel/ | other | 0.181805 | . \nThis response is untrustworthy due to lack of consistency in possible responses from the model. Here's one inconsistent alternate response that the model considered (which may not be accurate either): \nmissing phone. | missing phone |
| 61 | your atm pin can be changed at any visa or mastercard atm with pin services. certain countries don't support atm pin changes. | other | 0.188929 | . \nThis response is untrustworthy due to lack of consistency in possible responses from the model. Here's one inconsistent alternate response that the model considered (which may not be accurate either): \nchange pin. | change pin |
You can give these low confidence examples to a human annotator to review or label them. Alternatively, you can try to get the LLM to accurately label these examples via other methods we’ll consider next. Reviewing these low confidence examples helps you discover how to improve your LLM prompt / annotator instructions (e.g. how to handle edge-cases, which few-shot examples to provide, etc).
Few-shot Prompting
One method we can use to increase the accuracy and confidence of TLM predictions is: few-shot prompting. Here’s an example adapting our prompt template to include a few examples and their desired labels (generally try to include one example of each category).
fewshot_prompt_template = """
You are a professional customer service agent. You are given a customer's message and you are asked to classify the customer's message into one of the following categories:
- cancel transaction: The customer is requesting to cancel a transaction they recently made or is implicitly asking to cancel a transaction, i.e. they made a payment to a wrong account.
- fee charged: The customer is inquiring about a fee charged or disputing an unexpected fee or is missing money from a recent transaction.
- card expire: The customer needs assistance with a card that is expiring or expired soon.
- missing phone: The customer has lost their phone or is reporting a stolen phone.
- cards and currency: The customer is asking questions about card types, when where or how they can use their card, or currency related issues involving their card.
- spare card: The customer is requesting information about obtaining an additional or spare card.
- beneficiary not allowed: The customer is asking questions about beneficiary access issues.
- change pin: The customer needs help changing their card's PIN.
- apple google mobile pay: The customer is seeking assistance with Apple, Google or Mobile Pay functionality.
- transfer: The customer is asking about a transfer or a transfer related issue.
- other: The customer's message does not fit into any of the above categories.
## Some Examples
Customer message: I need to cancel a transaction I made to a wrong account.
Category: cancel transaction
Customer message: I was charged a fee for a transaction I didn't make.
Category: fee charged
Customer message: My card is about to expire I need a new one soon.
Category: card expire
Customer message: My phone was taken from me I need help.
Category: missing phone
Customer message: Am I able to use my Mastercard and AMEX for this transaction?
Category: cards and currency
Customer message: I need a replacement card right now I am traveling.
Category: spare card
Customer message: I tried the transfer as a beneficiary but I couldn't.
Category: beneficiary not allowed
Customer message: I need help changing my card's PIN.
Category: change pin
Customer message: My Apple Pay is not working on my phone.
Category: apple google mobile pay
Customer message: I transfered money to my friend's account but it's not showing up.
Category: transfer
Customer message: Should I open a checking or savings account?
Category: other
## New Example to Categorize
Now categorize the following Customer message. Respond with the category only, no leading or trailing text.
Customer message: {customer_message}
Category:
"""
Automatically Boost Accuracy
TLM can automatically boost the accuracy of predicted LLM labels if you specify a higher number of num_candidate_responses in TLMOptions. Additionally consider specifying TLM’s model configuration to a more powerful LLM that works well in your domain.
base_accuracy = np.mean(df["predicted_label"] == df["ground_truth_label"])
print(f"Base accuracy: {base_accuracy:.1%}")
# Here we set a higher number of candidate responses to auto-improve LLM response accuracy
tlm_best = TLM(options={"num_candidate_responses": 6, "log": ["explanation"]})
best_responses = tlm_best.prompt(all_prompts, constrain_outputs=valid_categories)
best_categories = [response["response"] for response in best_responses]
boosted_accuracy = np.mean(best_categories == df["ground_truth_label"])
print(f"Boosted accuracy: {boosted_accuracy:.1%}")
Find Errors in Existing Annotations
You can also use TLM to catch errors in existing annotations, either from a human annotator or another model.
Let’s look at examples where the human annotator and TLM disagree, but TLM’s trustworthiness score is high. We see in these cases that the human annotator actually made an error in their annotations!
wget -nc https://cleanlab-public.s3.us-east-1.amazonaws.com/Datasets/tlm-annotation-tutorial/human-categories.csv
human_categories = pd.read_csv("human-categories.csv")
df["human_category"] = human_categories["human_category"]
annotation_errors = df[df['human_category'] != df['predicted_label']].sort_values('trustworthiness', ascending=False).head(3)
annotation_errors[['text', 'predicted_label', 'trustworthiness', 'human_category']]
| text | predicted_label | trustworthiness | human_category | |
|---|---|---|---|---|
| 293 | unbeknownst to me, there was an additional charge on my prior transaction. a notification of sorts should be required and explained before future payments are made. | fee charged | 0.999382 | cancel transaction |
| 259 | my bag was stolen from me yesterday, so i can't use any apps or anything. i need some help. | missing phone | 0.985553 | spare card |
| 564 | how much is it to send out additional cards? | spare card | 0.959251 | card expire |
Document Tagging (Multi-Label Classification)
TLM can also be used for many other types of data annotation tasks. Suppose now that we wish to assign tags to various documents, loaded below. This is a multi-label classification task, where each document can receive multiple tags (unlike in multi-class classification, where each document would belong to exactly one category only). We provide the code needed to use TLM for this new labeling task below.
wget -nc https://cleanlab-public.s3.us-east-1.amazonaws.com/Datasets/tlm-annotation-tutorial/document_tagging_dataset.csv
df_tagging = pd.read_csv("document_tagging_dataset.csv")
tags = set(", ".join(df_tagging.labels.values).split(", "))
tagging_prompt = '''Given the following document, classify the document by applying one or more of the following tags: {tags}
Please output only the relevant tags separated by ", ", with no leading or trailing text or punctuation. Example output: tag1, tag2, tag3
Here is the document: {text}'''
# Generate prompts for all examples.
tagging_prompts = [tagging_prompt.format(text=text, tags=tags) for text in df_tagging.text]
# Query TLM to tag the documents
tagging_responses = tlm.prompt(tagging_prompts) # Note: we only specify constrain_outputs for multi-class classification, not other tasks
# Extract the tags and trustworthiness scores from the responses
df_tagging["tlm_tags"] = [tagging_response["response"] for tagging_response in tagging_responses]
df_tagging["trustworthiness"] = [tagging_response["trustworthiness_score"] for tagging_response in tagging_responses]
df_tagging.head()
# Helper method to compare predicted tags vs ground truth, for reporting LLM labeling accuracy
df_tagging['tags_equal'] = df_tagging.apply(
lambda row: set(t.strip() for t in row['labels'].split(',')) ==
set(t.strip() for t in row['tlm_tags'].split(',')),
axis=1
)
df_tagging.head()
| text | labels | tlm_tags | trustworthiness | tags_equal | |
|---|---|---|---|---|---|
| 0 | bring me the title of current music. tell me about mary s. | music_query, email_querycontact | music_query, social_query | 0.848176 | False |
| 1 | show me my alarms i have set | alarm_query | alarm_query | 0.999280 | True |
| 2 | turn on vacuum cleaner. could you please give me up to date news headlines from my newest provider | iot_cleaning, news_query | iot_cleaning, news_query | 0.997675 | True |
| 3 | veganism | general_quirky | general_quirky | 0.781522 | True |
| 4 | clean the floor. what is on my to do list today | iot_cleaning, lists_query | iot_cleaning, lists_query | 0.916779 | True |
Let’s again plot the accuracy of the TLM-predicted labels (computed with respect to ground-truth labels). Again, we assume annotations from TLM are only considered for the subset of data where the trustworthiness score is sufficiently high, so accuracy is only computed over this data subset (the remaining data could be manually reviewed/annotated by humans). Our plot again depicts the resulting accuracy across different choices of the trustworthiness score threshold, which determine how much of the data gets auto-labeled by the LLM (see X-axis below).
Optional: Plotting code
# Calculate the number of examples, percentage of data, and accuracy of TLM's predictions for each threshold value
threshold_analysis = pd.DataFrame([{
"threshold": t,
"num_examples": len(filtered := df_tagging[df_tagging["trustworthiness"] > t]),
"percent_data": len(filtered) / len(df_tagging) * 100,
"accuracy": np.mean(filtered["tags_equal"]) * 100
} for t in np.arange(0, 1.0, 0.01)]).round(2)
# Apply the function to your data
fig = create_enhanced_line_plot(threshold_analysis)
plt.show()
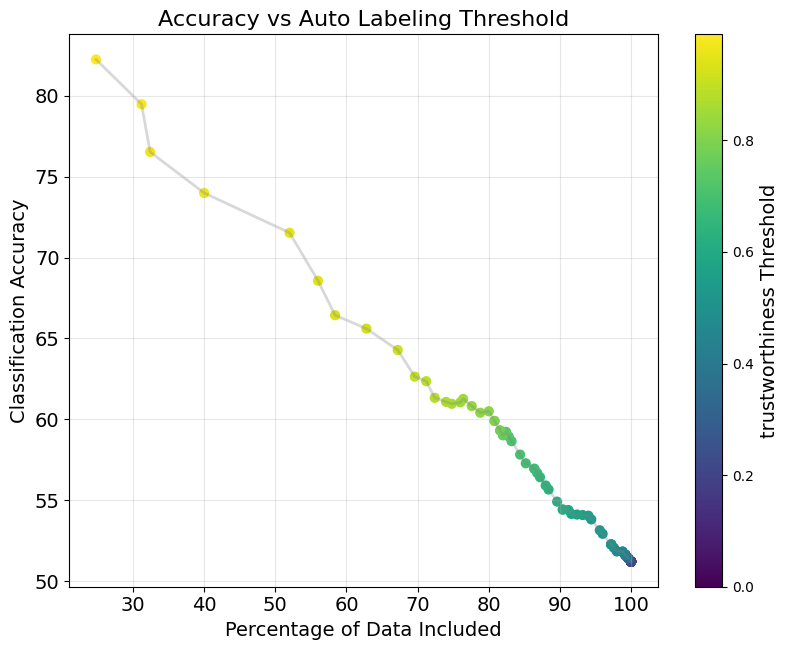
This plot again shows that, for document tagging, TLM can ensure a target labeling accuracy for examples above a certain trustworthiness score. Again the low-trustworthiness examples could be manually reviewed/labeled by human annotators.
Entity Recognition
Finally, let’s consider one more type of data annotation task. Here we consider PII (Personally Identifiable Information) Detection, loading a new dataset for our demonstration. The same technique applies to Data Extraction or more generally any Entity Recognition task.
wget -nc https://cleanlab-public.s3.us-east-1.amazonaws.com/Datasets/tlm-annotation-tutorial/pii_text_dataset.csv
pii_df = pd.read_csv("pii_text_dataset.csv")
pii_df.head()
| text | |
|---|---|
| 0 | Customer: Hello, I'm Emily Carter. Can you please verify my account details with my email emily.carter@fakemail.com and phone number 555-654-3210? |
| 1 | Customer: I need help updating my payment method. My old card is 4000123412341234, and the new one is 4000987654321234. |
| 2 | Customer: Hi, I forgot my password. My username is robert_king1980, and my phone number is 555-321-9876. Could you reset it? |
| 3 | Agent: To further assist, I need your SSN. Customer: Sure, it's 123-45-6789. |
| 4 | Customer: I noticed a suspicious transaction on my checking account 123456789, routing number 987654321. Please help me dispute it. |
Here we run TLM to produce Structured Outputs. This can be done by using TLM through the OpenAI client library rather than the Cleanlab TLM client library.
from pydantic import BaseModel, Field
from typing import List
# Define the PII response structure, you can easily add or remove fields as needed
class PiiResponse(BaseModel):
person: List[str] = Field(title="Person", description="Represents any full or partial name referring to a person (e.g., John Doe, Emily Carter).")
email: List[str] = Field(title="Email", description="Identifies email addresses in text (e.g., john.doe@example.com).")
phone: List[str] = Field(title="Phone", description="Captures telephone numbers (e.g., 555-123-4567).")
address: List[str] = Field(title="Address", description="Includes physical or mailing addresses (e.g., 1234 Elm Street, Faketown, FS 99999).")
ssn: List[str] = Field(title="SSN", description="Represents U.S. Social Security Numbers (e.g., 987-65-4321).")
credit_card: List[str] = Field(title="Credit Card", description="Identifies credit or debit card numbers and related details (e.g., 4111 1111 1111 1111).")
bank_account: List[str] = Field(title="Bank Account", description="Covers bank account numbers and routing numbers (e.g., Checking account 123456789).")
api_key: List[str] = Field(title="API Key", description="Includes API keys or tokens used for authentication (e.g., sk_test_51HfVxEC...).")
username: List[str] = Field(title="Username", description="Represents usernames for account login (e.g., robert_king1980).")
dob: List[str] = Field(title="DOB", description="Captures the date of birth (DOB) (e.g., 09/14/1985).")
employee_id: List[str] = Field(title="Employee ID", description="Represents company or corporate ID numbers (e.g., EID-4567).")
driver_license: List[str] = Field(title="Driver License", description="Driver's license identifiers (e.g., T123-4567).")
passport: List[str] = Field(title="Passport", description="Passport identifiers (e.g., X1234567).")
client = OpenAI(
api_key="<TLM_API_KEY>",
base_url="https://api.cleanlab.ai/api/v1/openai_trustworthy_llm/"
)
# Helper to extract PII from text using TLM through OpenAI's API
def extract_pii(client, text):
completion = client.beta.chat.completions.parse(
model="gpt-4o",
messages=[
{"role": "system", "content": "You are a data extraction expert."},
{"role": "user", "content": "Extract relevant personal identifying information from the following text: {}".format(text)}
],
response_format=PiiResponse,
)
return completion
# Run TLM via the OpenAI API
pii_responses = [extract_pii(client, text) for text in pii_df.text]
parsed_responses = [r.choices[0].message.parsed for r in pii_responses]
trust_scores = [r.tlm_metadata["trustworthiness_score"] for r in pii_responses]
pii_df["tlm_parsed_response"] = parsed_responses
pii_df["trustworthiness"] = trust_scores
Least Trustworthy Examples
We can again sort the LLM predicted labels by their trustworthiness score to see the lowest confidence results. Here we find problems in each example that warrant human review:
- The first example (row) contains a zip code that is not returned in the address field.
- The second example (row) contains “MasterCard” in the credit card field when it should only be the credit card number itself.
- The third example (row) contains “routing number” in the bank account field when it should only be the number itself.
pii_df.sort_values("trustworthiness", ascending=True).head(3)
| text | tlm_parsed_response | trustworthiness | |
|---|---|---|---|
| 26 | Agent: Please provide your billing ZIP code. Customer: It's 44444. | person=[] email=[] phone=[] address=['ZIP code: 44444'] ssn=[] credit_card=[] bank_account=[] api_key=[] username=[] dob=[] employee_id=[] driver_license=[] passport=[] | 0.447888 |
| 4 | Customer: I noticed a suspicious transaction on my checking account 123456789, routing number 987654321. Please help me dispute it. | person=[] email=[] phone=[] address=[] ssn=[] credit_card=[] bank_account=['123456789', '987654321'] api_key=[] username=[] dob=[] employee_id=[] driver_license=[] passport=[] | 0.591146 |
| 23 | Agent: What is the card you used for your last payment? Customer: It's 6011 6011 6011 6011, expiration 10/27. | person=[] email=[] phone=[] address=[] ssn=[] credit_card=['6011 6011 6011 6011'] bank_account=[] api_key=[] username=[] dob=[] employee_id=[] driver_license=[] passport=[] | 0.733902 |
Highest Confidence Examples
We can also sort our respones by the trustworthiness score and see the highest confidence responses.
pii_df.sort_values("trustworthiness", ascending=False).head(3)
| text | tlm_parsed_response | trustworthiness | |
|---|---|---|---|
| 33 | Customer: My phone is 555-101-2020, but I'm not receiving OTP codes. Could you check your system? | person=[] email=[] phone=['555-101-2020'] address=[] ssn=[] credit_card=[] bank_account=[] api_key=[] username=[] dob=[] employee_id=[] driver_license=[] passport=[] | 0.990000 |
| 31 | Customer: Could you verify if you have my passport number on file? It's X1234567. | person=[] email=[] phone=[] address=[] ssn=[] credit_card=[] bank_account=[] api_key=[] username=[] dob=[] employee_id=[] driver_license=[] passport=['X1234567'] | 0.990000 |
| 0 | Customer: Hello, I'm Emily Carter. Can you please verify my account details with my email emily.carter@fakemail.com and phone number 555-654-3210? | person=['Emily Carter'] email=['emily.carter@fakemail.com'] phone=['555-654-3210'] address=[] ssn=[] credit_card=[] bank_account=[] api_key=[] username=[] dob=[] employee_id=[] driver_license=[] passport=[] | 0.989999 |
Recommendations
Read the Advanced Tutorial to learn how to: improve accuracy/latency/costs (via TLM’s quality_preset and model configurations) and run TLM over large datasets.
In practice: you can manually label some data, and then use some of these examples in few-shot prompting TLM. After that, you can manually review/label a few examples with the lowest TLM trustworthiness scores. You can repeat this process iteratively, in each round adjusting your few-shot prompt for TLM (including more/better examples) so that the LLM predicts labels more accurately/confidently.
If you have any questions, please reach out to us at: support@cleanlab.ai.