Trustworthy Agents with LangGraph and Cleanlab

LangGraph helps you build fully-customizable Agentic AI systems tailored for your use-case. However due to LLM hallucinations, Agents occasionally produce incorrect responses, which erodes user trust and production readiness. This tutorial demonstrates how to score the trustworthiness of responses from any LangGraph Agent in real-time, and prevent incorrect responses from being served to your users.
Setup
# Install required packages
%pip install cleanlab-tlm langgraph langchain langchain_openai
# Set API keys
import os
os.environ["CLEANLAB_TLM_API_KEY"] = "<YOUR_CLEANLAB_TLM_API_KEY>" # Get your free API key from: https://tlm.cleanlab.ai/
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>" # Get API key from: https://platform.openai.com/signup
# Import required libraries
import langgraph
from cleanlab_tlm import TLM
Build a LangGraph Agent
Here we build on LangGraph’s Customer Support Bot tutorial, which you should refer to learn more about building Agents with LangGraph.
Our customer support Agent will be able to use various read-only Tools (functions without side-effects) in order to gather necessary information before answering the user. This tutorial shows how to automatically detect when the Agent’s answer is untrustworthy (likely incorrect). Other agentic AI applications where you can apply the same code demonstrated here include: Research Agents (DeepResearch), AI Analysts, Advisor Agents, Sales/Marketing Agents, Data Processing Agents, i.e. applications where the Agent’s response must be accurate.
These applications are different than task-oriented Agents whose sole job is to execute some Tool(s) (often an operation with a side effect like writing in a calendar) rather than giving the user an accurate and informative answer. For task-oriented Agents, we instead recommend scoring the trustworthiness of every internal Agent output (LLM call) to prevent mistakes before a Tool that causes side effects is called.
Optional: Define Tools and helper methods to support Tool invocation
import re
import numpy as np
import openai
import requests
from langchain_core.tools import tool
response = requests.get(
"https://storage.googleapis.com/benchmarks-artifacts/travel-db/swiss_faq.md"
)
response.raise_for_status()
faq_text = response.text
docs = [{"page_content": txt} for txt in re.split(r"(?=\n##)", faq_text)]
class VectorStoreRetriever:
def __init__(self, docs: list, vectors: list, oai_client):
self._arr = np.array(vectors)
self._docs = docs
self._client = oai_client
@classmethod
def from_docs(cls, docs, oai_client):
embeddings = oai_client.embeddings.create(
model="text-embedding-3-small", input=[doc["page_content"] for doc in docs]
)
vectors = [emb.embedding for emb in embeddings.data]
return cls(docs, vectors, oai_client)
def query(self, query: str, k: int = 5) -> list[dict]:
embed = self._client.embeddings.create(
model="text-embedding-3-small", input=[query]
)
# "@" is just a matrix multiplication in python
scores = np.array(embed.data[0].embedding) @ self._arr.T
top_k_idx = np.argpartition(scores, -k)[-k:]
top_k_idx_sorted = top_k_idx[np.argsort(-scores[top_k_idx])]
return [
{**self._docs[idx], "similarity": scores[idx]} for idx in top_k_idx_sorted
]
retriever = VectorStoreRetriever.from_docs(docs, openai.Client())
@tool
def lookup_policy(query: str) -> str:
"""Consult the company policies to check whether certain options are permitted.
Use this before making any flight changes performing other 'write' events."""
docs = retriever.query(query, k=2)
return "\n\n".join([doc["page_content"] for doc in docs])
# Populate Database that Agent can access via Tool Call
import os
import shutil
import sqlite3
import pandas as pd
import requests
from datetime import timedelta
db_url = "https://storage.googleapis.com/benchmarks-artifacts/travel-db/travel2.sqlite"
local_file = "travel2.sqlite"
# The backup lets us restart for each tutorial section
backup_file = "travel2.backup.sqlite"
overwrite = False
if overwrite or not os.path.exists(local_file):
response = requests.get(db_url)
response.raise_for_status() # Ensure the request was successful
with open(local_file, "wb") as f:
f.write(response.content)
# Backup - we will use this to "reset" our DB in each section
shutil.copy(local_file, backup_file)
# Convert the flights to present time for our tutorial
def update_dates(file):
shutil.copy(backup_file, file)
conn = sqlite3.connect(file)
cursor = conn.cursor()
tables = pd.read_sql(
"SELECT name FROM sqlite_master WHERE type='table';", conn
).name.tolist()
tdf = {}
for t in tables:
tdf[t] = pd.read_sql(f"SELECT * from {t}", conn)
example_time = pd.to_datetime(
tdf["flights"]["actual_departure"].replace("\\N", pd.NaT)
).max()
current_time = pd.to_datetime("now").tz_localize(example_time.tz)
time_diff = current_time - example_time
tdf["bookings"]["book_date"] = (
pd.to_datetime(tdf["bookings"]["book_date"].replace("\\N", pd.NaT), utc=True)
+ time_diff
)
datetime_columns = [
"scheduled_departure",
"scheduled_arrival",
"actual_departure",
"actual_arrival",
]
for column in datetime_columns:
tdf["flights"][column] = (
pd.to_datetime(tdf["flights"][column].replace("\\N", pd.NaT)) + time_diff
)
for table_name, df in tdf.items():
df.to_sql(table_name, conn, if_exists="replace", index=False)
del df
del tdf
conn.commit()
conn.close()
return file
db = update_dates(local_file)
import sqlite3
from datetime import date, datetime
from typing import Optional
import pytz
from langchain_core.runnables import RunnableConfig
@tool
def fetch_user_flight_information(config: RunnableConfig) -> list[dict]:
"""Fetch all tickets for the user along with corresponding flight information and seat assignments.
Returns:
A list of dictionaries where each dictionary contains the ticket details,
associated flight details, and the seat assignments for each ticket belonging to the user.
"""
configuration = config.get("configurable", {})
passenger_id = configuration.get("passenger_id", None)
if not passenger_id:
raise ValueError("No passenger ID configured.")
conn = sqlite3.connect(db)
cursor = conn.cursor()
query = """
SELECT
t.ticket_no, t.book_ref,
f.flight_id, f.flight_no, f.departure_airport, f.arrival_airport, f.scheduled_departure, f.scheduled_arrival,
bp.seat_no, tf.fare_conditions
FROM
tickets t
JOIN ticket_flights tf ON t.ticket_no = tf.ticket_no
JOIN flights f ON tf.flight_id = f.flight_id
JOIN boarding_passes bp ON bp.ticket_no = t.ticket_no AND bp.flight_id = f.flight_id
WHERE
t.passenger_id = ?
"""
cursor.execute(query, (passenger_id,))
rows = cursor.fetchall()
column_names = [column[0] for column in cursor.description]
results = [dict(zip(column_names, row)) for row in rows]
cursor.close()
conn.close()
return results
from datetime import date, datetime
from typing import Optional, Union
@tool
def search_flights(
departure_airport: Optional[str] = None,
arrival_airport: Optional[str] = None,
start_time: Optional[date | datetime] = None,
end_time: Optional[date | datetime] = None,
limit: int = 20,
) -> list[dict]:
"""Search for flights based on departure airport, arrival airport, and departure time range."""
conn = sqlite3.connect(db)
cursor = conn.cursor()
query = "SELECT * FROM flights WHERE 1 = 1"
params = []
if departure_airport:
query += " AND departure_airport = ?"
params.append(departure_airport)
if arrival_airport:
query += " AND arrival_airport = ?"
params.append(arrival_airport)
if start_time:
query += " AND scheduled_departure >= ?"
params.append(start_time)
if end_time:
query += " AND scheduled_departure <= ?"
params.append(end_time)
query += " LIMIT ?"
params.append(limit)
cursor.execute(query, params)
rows = cursor.fetchall()
column_names = [column[0] for column in cursor.description]
results = [dict(zip(column_names, row)) for row in rows]
cursor.close()
conn.close()
return results
@tool
def search_car_rentals(
location: Optional[str] = None,
name: Optional[str] = None,
price_tier: Optional[str] = None,
start_date: Optional[Union[datetime, date]] = None,
end_date: Optional[Union[datetime, date]] = None,
) -> list[dict]:
"""
Search for car rentals based on location, name, price tier, start date, and end date.
Args:
location (Optional[str]): The location of the car rental. Defaults to None.
name (Optional[str]): The name of the car rental company. Defaults to None.
price_tier (Optional[str]): The price tier of the car rental. Defaults to None.
start_date (Optional[Union[datetime, date]]): The start date of the car rental. Defaults to None.
end_date (Optional[Union[datetime, date]]): The end date of the car rental. Defaults to None.
Returns:
list[dict]: A list of car rental dictionaries matching the search criteria.
"""
conn = sqlite3.connect(db)
cursor = conn.cursor()
query = "SELECT * FROM car_rentals WHERE 1=1"
params = []
if location:
query += " AND location LIKE ?"
params.append(f"%{location}%")
if name:
query += " AND name LIKE ?"
params.append(f"%{name}%")
if price_tier:
query += " AND price_tier LIKE ?"
params.append(f"%{price_tier}%")
if start_date:
query += " AND start_date >= ?"
params.append(str(start_date))
if end_date:
query += " AND end_date <= ?"
params.append(str(end_date))
# This tool allows matching on price tier and dates even though data is limited
# which tests Agent behavior when relevant data might be missing.
cursor.execute(query, params)
results = cursor.fetchall()
conn.close()
return [
dict(zip([column[0] for column in cursor.description], row)) for row in results
]
@tool
def search_hotels(
location: Optional[str] = None,
name: Optional[str] = None,
price_tier: Optional[str] = None,
checkin_date: Optional[Union[datetime, date]] = None,
checkout_date: Optional[Union[datetime, date]] = None,
) -> list[dict]:
"""
Search for hotels based on location, name, price tier, check-in date, and check-out date.
Args:
location (Optional[str]): The location of the hotel. Defaults to None.
name (Optional[str]): The name of the hotel. Defaults to None.
price_tier (Optional[str]): The price tier of the hotel. Defaults to None. Examples: Midscale, Upper Midscale, Upscale, Luxury
checkin_date (Optional[Union[datetime, date]]): The check-in date of the hotel. Defaults to None.
checkout_date (Optional[Union[datetime, date]]): The check-out date of the hotel. Defaults to None.
Returns:
list[dict]: A list of hotel dictionaries matching the search criteria.
"""
conn = sqlite3.connect(db)
cursor = conn.cursor()
query = "SELECT * FROM hotels WHERE 1=1"
params = []
if location:
query += " AND location LIKE ?"
params.append(f"%{location}%")
if name:
query += " AND name LIKE ?"
params.append(f"%{name}%")
# For the sake of this tutorial, we will let you match on any dates and price tier.
cursor.execute(query, params)
results = cursor.fetchall()
conn.close()
return [
dict(zip([column[0] for column in cursor.description], row)) for row in results
]
@tool
def search_trip_recommendations(
location: Optional[str] = None,
name: Optional[str] = None,
keywords: Optional[str] = None,
) -> list[dict]:
"""
Search for trip recommendations based on location, name, and keywords.
Args:
location (Optional[str]): The location of the trip recommendation. Defaults to None.
name (Optional[str]): The name of the trip recommendation. Defaults to None.
keywords (Optional[str]): The keywords associated with the trip recommendation. Defaults to None.
Returns:
list[dict]: A list of trip recommendation dictionaries matching the search criteria.
"""
conn = sqlite3.connect(db)
cursor = conn.cursor()
query = "SELECT * FROM trip_recommendations WHERE 1=1"
params = []
if location:
query += " AND location LIKE ?"
params.append(f"%{location}%")
if name:
query += " AND name LIKE ?"
params.append(f"%{name}%")
if keywords:
keyword_list = keywords.split(",")
keyword_conditions = " OR ".join(["keywords LIKE ?" for _ in keyword_list])
query += f" AND ({keyword_conditions})"
params.extend([f"%{keyword.strip()}%" for keyword in keyword_list])
cursor.execute(query, params)
results = cursor.fetchall()
conn.close()
return [
dict(zip([column[0] for column in cursor.description], row)) for row in results
]
# Some additional tools beyond those from LangGraph's original tutorial
@tool
def get_travel_advisory(country: str) -> dict:
"""Returns a mock travel advisory for a country."""
return {
"level": "Level 2 – Exercise Increased Caution",
"notes": f"Travelers to {country} should be aware of petty crime and take precautions."
}
@tool
def get_discount_plan(name: str) -> str:
"""Returns details about a discount plan based on its name.
Valid names: "basic", "premium", "five", "student"
"""
return f"Returning details for the '{name}' discount plan:"
class InsuranceTerms:
def __init__(self, provider: str):
self.provider = provider
self.coverage = {
"GloboSure": {
"trip_delay": "Up to 500 credits after 6 hours",
"lost_baggage": "Up to 1200 credits with receipt proof",
"medical": "Emergency care covered up to 50,000 credits"
},
"NimbusCoverage": {
"cancellation": "Refunds up to 70% for non-weather issues",
"extreme_weather": "Full coverage with documentation"
}
}
@tool
def get_insurance_terms(provider: str) -> InsuranceTerms:
"""Returns a policy explanation object for a given (possibly obscure) travel insurance provider."""
return InsuranceTerms(provider)
# Helper functions to pretty print messages and give our tool node error handling
from langchain_core.messages import ToolMessage
from langchain_core.runnables import RunnableLambda
from langgraph.prebuilt import ToolNode
def handle_tool_error(state) -> dict:
error = state.get("error")
tool_calls = state["messages"][-1].tool_calls
return {
"messages": [
ToolMessage(
content=f"Error: {repr(error)}\n please fix your mistakes.",
tool_call_id=tc["id"],
)
for tc in tool_calls
]
}
def create_tool_node_with_fallback(tools: list) -> dict:
return ToolNode(tools).with_fallbacks(
[RunnableLambda(handle_tool_error)], exception_key="error"
)
def _print_event(event: dict, _printed: set, max_length=1500):
current_state = event.get("dialog_state")
if current_state:
print("Currently in: ", current_state[-1])
message = event.get("messages")
if message:
if isinstance(message, list):
message = message[-1]
if message.id not in _printed:
msg_repr = message.pretty_repr(html=True)
if len(msg_repr) > max_length:
msg_repr = msg_repr[:max_length] + " ... (truncated)"
print(msg_repr)
_printed.add(message.id)
## Added to print trust scores
print()
trust_score = event.get("trustworthiness_score")
if trust_score is not None:
print(f"[TLM score for this response]: {trust_score:.2f}")
Optional: Setup LangGraph Agent
from typing import Annotated, Optional
from typing_extensions import TypedDict
from langgraph.graph.message import AnyMessage, add_messages
class State(TypedDict):
# State follows the structure from the original LangGraph tutorial, plus an optional trustworthiness_score field
messages: Annotated[list[AnyMessage], add_messages]
trustworthiness_score: Optional[float] # Later in this tutorial, we will store trust scores here, but they are not required for the original LangGraph Agent
# Define the Assistant in LangGraph:
from datetime import datetime
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import Runnable, RunnableConfig
class Assistant:
def __init__(self, runnable: Runnable):
self.runnable = runnable
def __call__(self, state: State, config: RunnableConfig):
while True:
configuration = config.get("configurable", {})
passenger_id = configuration.get("passenger_id", None)
state = {**state, "user_info": passenger_id}
result = self.runnable.invoke(state)
# If the LLM happens to return an empty response, we will re-prompt it
# for an actual response.
if not result.tool_calls and (
not result.content
or isinstance(result.content, list)
and not result.content[0].get("text")
):
messages = state["messages"] + [("user", "Respond with a real output.")]
state = {**state, "messages": messages}
else:
break
return {"messages": result}
# Specify which LLM model to use, Cleanlab works with all LLMs.
llm = ChatOpenAI(model="gpt-4o-mini")
# Specify system instructions for your Agent to follow, Cleanlab works with all Agents.
primary_assistant_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a helpful customer support assistant for Swiss Airlines. "
" Use the provided tools to search for flights, company policies, and other information to assist the user's queries. "
" When searching, be persistent. Expand your query bounds if the first search returns no results. "
" If a search comes up empty, expand your search before giving up."
"\n\nCurrent user:\n<User>\n{user_info}\n</User>"
"\nCurrent time: {time}.",
),
("placeholder", "{messages}"),
]
).partial(time=datetime.now)
part_1_tools = [
fetch_user_flight_information,
search_flights,
lookup_policy,
search_car_rentals,
search_hotels,
search_trip_recommendations,
# Additional mock tools
get_travel_advisory,
get_discount_plan,
get_insurance_terms,
]
part_1_assistant_runnable = primary_assistant_prompt | llm.bind_tools(part_1_tools)
# Instantiate the graph that orchestrates the LangGraph Agent:
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import END, StateGraph, START
from langgraph.prebuilt import tools_condition
builder = StateGraph(State)
# Define nodes: these do the work
builder.add_node("assistant", Assistant(part_1_assistant_runnable))
builder.add_node("tools", create_tool_node_with_fallback(part_1_tools))
# Define edges: these determine how the control flow moves
builder.add_edge(START, "assistant")
builder.add_conditional_edges(
"assistant",
tools_condition,
)
builder.add_edge("tools", "assistant")
# The checkpointer lets the graph persist its state, a complete memory for the entire graph
# memory = MemorySaver()
# part_1_graph = builder.compile(checkpointer=memory)
# This tutorial focuses on single-turn Question-Answer interactions between user and assistant, you can also use Cleanlab in multi-turn applications.
part_1_graph = builder.compile()
def query_agent(graph, question):
_printed = set()
events = graph.stream(
{"messages": ("user", question)},
RunnableConfig(configurable={"passenger_id": "3442 587242"}),
stream_mode="values"
)
for event in events:
_print_event(event, _printed)
def show_agent_graph(graph):
try: # This visualization requires extra dependencies and is optional
from IPython.display import Image, display
display(Image(graph.get_graph(xray=True).draw_mermaid_png()))
except Exception:
pass
Here’s what the LangGraph graph implementing our Agent looks like:
show_agent_graph(part_1_graph)

If you have any questions about the LangGraph code, refer to their tutorial and documentation.
Run the Agent
Let’s ask our customer support Agent some queries.
user_query = "Can I get a refund if I cancel my flight with Swiss Airlines?"
query_agent(
graph=part_1_graph,
question=user_query
)
This example illustrates the Agent’s ability to call the appropriate tool and craft an accurate, policy-based answer from the returned data. Let’s run some more queries, showcasing some that yield problematic Agent responses.
user_query = "What are the details of the 5 discount plan"
query_agent(
graph=part_1_graph,
question=user_query
)
In this case, incomplete results were returned from the Tool. Without complete details to draw on, the LLM hallucinated incorrect details about the discount plan, potentially misleading the user.
user_query = "What coverage does GloboSure give me for travel delays?"
query_agent(
graph=part_1_graph,
question=user_query
)
In this case, the Tool was implemented to return raw Python objects rather then the object’s body, and the LLM filled the gap by hallucinating incorrect travel-delay coverage details.
user_query = "Is there a health advisory in Basel"
query_agent(
graph=part_1_graph,
question=user_query
)
In this case, the Agent chose the right Tool, but it returned an advisory about crime rather than the requested health advisory for Basel. The Tool didn’t explicitly explain that it did not have the relevant information. The Agent didn’t notice the discrepancy and thus gave an incorrect response.
user_query = "What is my arrival time in their time zone?"
query_agent(
graph=part_1_graph,
question=user_query
)
In this case, the LLM mistakenly assumed that Basel (BSL) uses the UTC-4 time zone. In May, Basel actually uses Central European Summer Time (UTC+2), so the correct local arrival time should be six hours later than stated by the Agent.
user_query = "What are conspiracy theories around Swiss Airlines safety?"
query_agent(
graph=part_1_graph,
question=user_query
)
In this case, no appropriate Tool is available for this query. The Agent responds with a potentially hallucinated answer that could harm the airline’s reputation.
Trustworthy Agent
Now let’s see how Cleanlab’s Trustworthy Language Model (TLM) can catch these issues in real time via state-of-the-art LLM trustworthiness scoring. Easily integrate TLM into your LangGraph application by wrapping your existing assistant (LLM) node with our provided wrapper. This updates the LangGraph state to store a score quantifying the trustworthiness of the latest AI message, such that low scores correspond to messages which are likely incorrect or flawed.
We first initialize a TLM client and define the wrapper.
tlm = TLM() # See Advanced Tutorial for optional TLM configurations to get better/faster results
class TrustworthyAssistant:
def __init__(self, assistant: Assistant, tools, tlm):
self.assistant = assistant
self.tools = tools
self.tlm = tlm
def __call__(self, state: State, config: RunnableConfig):
# Render full prompt including system which uses template variables
# TODO: You should update this based on your own ChatPromptTemplate
configuration = config.get("configurable", {})
passenger_id = configuration.get("passenger_id", None)
state = {**state, "user_info": passenger_id}
prompt_template = self.assistant.runnable.first
full_prompt_messages = prompt_template.invoke(state)
# Run the assistant node
result_dict = self.assistant(state, config)
result = result_dict["messages"]
# Convert chat history and tools to OpenAI format
from langchain_core.messages.utils import convert_to_openai_messages
from langchain_core.utils.function_calling import convert_to_openai_tool
from cleanlab_tlm.utils.chat import form_prompt_string
openai_chat_history = convert_to_openai_messages(full_prompt_messages)
openai_response_msg = convert_to_openai_messages(result)
openai_chat_tools = [convert_to_openai_tool(tool) for tool in self.tools]
# Only score assistant messages with content
if openai_response_msg.get("role") == "assistant" and openai_response_msg.get("content"):
prompt = form_prompt_string(openai_chat_history, openai_chat_tools)
response = openai_response_msg["content"]
score = self.tlm.get_trustworthiness_score(prompt=prompt, response=response)["trustworthiness_score"]
else:
score = None
return {**result_dict, "trustworthiness_score": score}
We add this wrapper node and re-compile LangGraph. Here you only update one line of code in your graph -— everything else stays the same.
Optional: Re-compile LangGraph to use the wrapper
Except where indicated, this graph code is the same as our original Agent
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import END, StateGraph, START
from langgraph.prebuilt import tools_condition
builder = StateGraph(State)
# Define nodes: these do the work
builder.add_node("assistant", TrustworthyAssistant(Assistant(part_1_assistant_runnable), part_1_tools, tlm)) # This is the only change needed from your existing LangGraph code
builder.add_node("tools", create_tool_node_with_fallback(part_1_tools))
# Define edges: these determine how the control flow moves
builder.add_edge(START, "assistant")
builder.add_conditional_edges(
"assistant",
tools_condition,
)
builder.add_edge("tools", "assistant")
tlm_graph = builder.compile()
The graph implementing our Agent remains unchanged.
show_agent_graph(tlm_graph)
Now let’s run our Agent with automated trustworthiness scoring in place. In the traces below, the trustworthiness scores from TLM correspond to the final assistant message in each conversation. This is the response given to your user, whose correctness is vital.
user_query = "Can I get a refund if I cancel my flight with Swiss Airlines?"
query_agent(
graph=tlm_graph,
question=user_query
)
Upon review, we see that the Agent’s response was correct for this simple question. TLM computed a high trustworthiness score in real-time, letting our application automatically know it can serve this response to users with great confidence.
Let’s run the queries where our Agent responded incorrectly before.
user_query = "What are the details of the 5 discount plan"
query_agent(
graph=tlm_graph,
question=user_query
)
user_query = "What coverage does GloboSure give me for travel delays?"
query_agent(
graph=tlm_graph,
question=user_query
)
user_query = "Is there a health advisory in Basel"
query_agent(
graph=tlm_graph,
question=user_query
)
user_query = "What is my arrival time in their time zone?"
query_agent(
graph=tlm_graph,
question=user_query
)
user_query = "What are conspiracy theories around Swiss Airlines safety?"
query_agent(
graph=tlm_graph,
question=user_query
)
Upon review, we find that the Agent’s responses were problematic for the above queries. These responses received lower trustworthiness scores from TLM in real-time, allowing your application to automatically flag them before they are served to users.
You could still choose to show such responses to users appending a caveat like: CAUTION: THIS RESPONSE HAS BEEN FLAGGED AS POTENTIALLY UNTRUSTWORTHY.
Alternatively, you could escalate this interaction to a human customer support representative, or return a canned fallback response in place of the Agent’s response. The next section demonstrates how to implement the fallback strategy in LangGraph.
Fallback Logic: Replacing Untrustworthy Responses
To enable your Agent to act when trust scores are low, you can create a fallback node in LangGraph. Here we showcase a simple fallback strategy which replaces the original assistant message with a pre-written response that indicates a lack of knowledge.
You can easily swap this out for other fallback behaviors like:
- Escalate to a human
- Re-run the Agent with a modified prompt
- Re-generate the recent untrustworthy LLM output to have the Agent autonomously improve its response
from langchain_core.messages import RemoveMessage
def fallback_node(state):
messages = state["messages"]
if not messages:
return state # Nothing to remove
# Remove the last message
to_remove = RemoveMessage(id=messages[-1].id)
# Assistant message to fallback to (adjust this message to suit your use-case)
new_msg = {
"role": "assistant",
"content": "Sorry I cannot answer based on available information, try re-phrasing your question or providing more details."
}
return {
**state,
"messages": [to_remove, new_msg],
"trustworthiness_score": None
}
This implements conditional logic for routing based on the trustworthiness score. If the most recent asssistant message receives a trustworthiness score below 0.9, the conversation is routed to the fallback node.
This allows you to override the Agent’s behavior whenever the assistant response is deemed untrustworthy.
Important: Since the trustworthiness score in the LangGraph state should reflect the most recent assistant message, set it to None in your fallback node as above to prevent the fallback condition from repeatedly triggering.
from typing import Literal
def trustworthiness_condition(state: State) -> Literal["fallback", "tools", "__end__"]:
score = state.get("trustworthiness_score")
if score is not None and score < 0.9: # adjust threshold to suit your use-case
return "fallback"
# Otherwise, defer to original condition/node
return tools_condition(state)
To update the graph with this fallback logic, you just need to:
- add the fallback node
- replace the original conditional edge from the assistant with one using
trustworthiness_condition.
Optional: Re-compile LangGraph including the fallback logic
Except where indicated, this graph code is the same as our original Agent
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import END, StateGraph, START
from langgraph.prebuilt import tools_condition
builder = StateGraph(State)
# Define nodes: these do the work
builder.add_node("assistant", TrustworthyAssistant(Assistant(part_1_assistant_runnable), part_1_tools, tlm)) # Only change assistant node.
builder.add_node("tools", create_tool_node_with_fallback(part_1_tools))
# Define edges: these determine how the control flow moves
builder.add_edge(START, "assistant")
builder.add_node("fallback", fallback_node) # New code to add to existing graph
builder.add_conditional_edges(
"assistant",
trustworthiness_condition, # New code to add to existing graph
) # New
builder.add_edge("tools", "assistant")
fallback_graph = builder.compile()
show_agent_graph(fallback_graph)
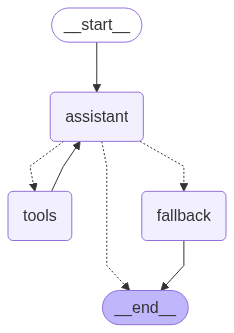
Now let’s run our Agent with the fallback in place. Here we use LangGraph’s invoke() rather than streaming assistant messages, so that the original Agent’s response (which was prevented via our trust-based fallback) is not printed.
user_query = "What are the details of the 5 discount plan"
result = fallback_graph.invoke(
{"messages": ("user", user_query)},
RunnableConfig(configurable={"passenger_id": "3442 587242"})
)
messages = result.get("messages", [])
_printed = set()
for message in messages:
if message.id not in _printed:
msg_repr = message.pretty_repr(html=True)
print(msg_repr)
_printed.add(message.id)
In this case, the trust-based fallback prevented the Agent from hallucinating incorrect details about the “five” discount plan. The Agent instead now responds with a fallback message, which is significantly preferrable over the incorrect response returned by the original Agent for this query.
Conclusion. Adding trust scoring to your Agent is easy and can automatically prevent incorrect/misleading responses from your Agent. When LLM outputs receive low trustworthiness scores, this tutorial showcased a basic fallback strategy to replace the Agent’s response with a pre-written abstention phrase. In these cases of an untrustworthy LLM output, you could alternatively: escalate to a human, re-run the Agent with a modified prompt, or automatically re-generate the recent untrustworthy LLM output to have the Agent autonomously improve its response.