Data Labeling
This tutorial shows how to use Cleanlab Studio for labeling a classification dataset, when only a subset of the data is labeled. Cleanlab Studio expedites this process by predicting labels for your unlabeled data and reporting confidence scores for each prediction, so you know which subset of the data can be reliably auto-labeled by our AI.
Cleanlab’s predictions come from combining Foundation models (that rely on pre-trained world knowledge) with supervised ML models trained on your existing labeled data (that learn domain-specific patterns in your data). The Web Inferface supports a human-in-the-loop data labeling workflow, where you can review and accept proposed labels from Cleanlab’s ML model, and with one click, retrain the ML model to learn from the additional supervision information provided in your latest labels. The retrained ML model becomes more confident and accurate as more data is labeled, so iterating this labeling/retraining process enables a single user to label large datasets.
We recommend starting with at least 5 labeled examples per class. For datasets that are under 50% labeled, a special auto-labeling wizard will automatically guide you through the first cycle of data labeling + model retraining (if you run a Regular mode Project). After this initial round of auto-labeling, Cleanlab Studio will also automatically detect data and labeling issues that you can address while continuing to label more data.
Get the Dataset
This tutorial uses a version of the agnews dataset which you can download here: ag_news.csv. This dataset is composed of news articles from 4 classes: World, Sports, Business and Sci/Tech. 99.5% of the examples in this dataset are not yet labeled. Here are some of the labeled examples from this dataset:
| text | label |
|---|---|
| Bahrain boils in summer power cut Bahrainis swelter in 50-degree temperatures without air conditioning as a fault cuts electricity across the island. | World |
| Peete Completes Rally Rodney Peete found Walter Young for an 18-yard touchdown pass with 1:48 to play, rallying the Panthers past the Patriots, 20-17, Saturday. | Sports |
| Sears, Kmart merge Kmart Holding Corp., the US retailer which emerged from bankruptcy protection only 18 months ago, announced a 11 billion dollar merger with Sears, Roebuck amp; Co, on Nov. 17, 2004. | Business |
| Microsoft Updates Its IBM Connectivity Server Microsoft on Tuesday unveiled the 2004 version of its Host Integration Server (HIS) product, which is designed to integrate IBM mainframes and servers with Windows systems. | Sci/Tech |
We use a text dataset as an example here, but the steps from this tutorial can also be applied to image or structured/tabular datasets. While ag_news is a multi-class text classification dataset, the process is similar for a multi-label dataset. Learn how to format such datasets here. Learn about formatting unlabeled data here. Note the difference between unlabeled data points in a dataset that has associated labels, and an unsupervised project in which there are no labels to speak of (this tutorial covers the former, not the latter).
Load your Dataset
To load your local dataset into Cleanlab Studio, click on Upload Dataset button and go through the steps under Upload from your computer:
- Click
Upload Dataset - Select
Upload from your computer - Select or drag-and-drop the provided
ag_news.csv - Click
Next - Cleanlab Studio automatically infers the dataset’s schema. You can leave this as-is and click
Confirm
For many Cleanlab users, this will be the most common way of loading datasets. Datasets can alternatively be loaded from URLs (for publicly hosted datasets), or via command line or the Python API (for integrating Cleanlab into your data processing and QA pipeline).
Python API instructions (click to expand)
To instead (optionally) load your data into Cleanlab Studio via the Python API, use the upload_dataset method:
from cleanlab_studio import Studio
import pandas as pd
studio = Studio('YOUR_API_KEY')
df = pd.read_csv('ag_news.csv')
studio.upload_dataset(dataset=df, dataset_name = "Data Labeling Tutorial")
Create a Project
Once your dataset is loaded into the application, click Create Project from the dataset page or the home dashboard. The project creation page offers several settings:
- Machine Learning Task: select
Text Classification— we’re working with a text classification task in this tutorial (classifying text snippets into disjoint categories like Sports or Business). - Type of Classification: select
Multi-Class(the default) — the ag_news dataset is for a single-label classification task, where each text example belongs to exactly one class. - Text column: select
text(which is auto-detected) — the name of the column from your dataset that contains the text, on which predictions/labels are based. - Label column: select
label(which is auto-detected) — the name of the column from your dataset that contains the labels.
Keep the default Use Cleanlab Auto-ML setting, and choose Regular mode, which will train better ML models (and is necessary for using Cleanlab’s auto-labeling wizard).
Finally, click Clean my data! to start the data analysis!
The video below shows us loading the dataset and creating a project.
When you launch a project, Cleanlab Studio trains cutting-edge ML models to analyze your data, which can take some time (about 15min for this tutorial dataset). You’ll get an email once the analysis is complete. By clicking on the e-mail link or Ready for review on the home dashboard, you can view the Project results.
Initial data labeling via the Auto-Labeling Wizard
When the majority of your data is unlabeled (less than 50%), Cleanlab’s auto-labeling wizard gets activated to help you bulk-label a large subset of your data that our AI can confidently handle. If the majority of your data is originally labeled, the auto-labeling wizard will not appear and you can skip to the subsequent Labeling More Data section of this tutorial.
The auto-labeling wizard walks you through two simple steps.
Step 1: Auto-label data points with confidently predicted labels
The first step involves bulk labeling the subset of data points that our AI can accurately predict labels for. Each data point receives a confidence score indicating how much the AI-suggested label can be trusted.
The wizard will automatically estimate a reasonable confidence score threshold, above which all data points can be labeled with their predicted label via just one click. In the below video, the blue line indicates this automatically estimated threshold.
The estimated threshold may be imperfect, so consider adjusting it prior to auto-labeling. Inspect some rows above and below the threshold. Decrease the threshold value if the suggested labels for rows below the threshold look correct; increase it if suggested labels for rows above the threshold don’t look correct. Adjust the threshold by changing the row number in Threshold Row box above the data table or using the Set as threshold button.
For our tutorial dataset, we confidently auto-label 1326 examples in the dataset, as shown in the video below.
Step 2: Label additional data points that will be most informative
After using Cleanlab’s ML model to auto-label data receiving high-confidence predictions, optionally label some additional data yourself. Here we recommend labeling some of the lowest-confidence examples in the dataset. These data points will be most informative for re-training Cleanlab’s ML model, which can be then be used to auto-label more data with greater accuracy/confidence. The more data you label, the better Cleanlab’s ML system will get after re-training. You can use the Skip button if you don’t want to label any data yourself.
The below video demonstrates this second step, where we label a few low confidence data points ourselves.
Once you’ve gone through the auto-labeling wizard, Cleanlab will re-train its ML model on the resulting labeled dataset (which may take a while, you’ll receive an email when results are ready). This model is then used to detect data/label issues and suggest labels for remaining unlabeled examples. This subsequent part of the workflow is equivalent to a regular Cleanlab Studio Project for datasets that are over 50% labeled.
The following sections walk through this regular Cleanlab Studio Project workflow, showing how you can iteratively auto-label more of your data and auto-detect label errors, until your entire dataset is accurately labeled and issue-free. In this regular Cleanlab Studio Project workflow: any labels that were added in the auto-labeling wizard (in Steps 1 and 2 above) will appear as Given labels in the subsequent Project view. You can also also skip the following sections and directly Export your labeled dataset produced via the auto-labeling wizard.
Labeling more data and resolving data issues
Here we cover data labeling in the regular Cleanlab Studio Project workflow. Start from this section if the majority of your dataset was originally labeled (in which case the auto-labeling wizard will not appear). This section also covers the workflow to iteratively label more data after you’ve gone through the auto-labeling wizard. Once there are sufficiently many labeled examples from each class, Cleanlab’s ML model will be able to predict that class much better, such that you can accurately auto-label more data. In addition, Cleanlab’s data-centric AI system can also uncover various issues in your dataset (like previously mislabeled data points) that you can fix in the Web Interface.
While Cleanlab Studio can be used to quickly re-label data detected as being originally mislabeled (see other tutorials), here let’s focus on labeling originally unlabeled data. You can solely view the unlabeled data within a dataset by selecting Unlabeled in the Filter bar. Unlabeled data takes value - in the Given label column (to indicate no label has been given yet). For each unlabeled data point, Cleanlab Studio automatically predicts an appropriate label in the Suggested label column, along with a confidence score for this prediction.
Labeling individual examples
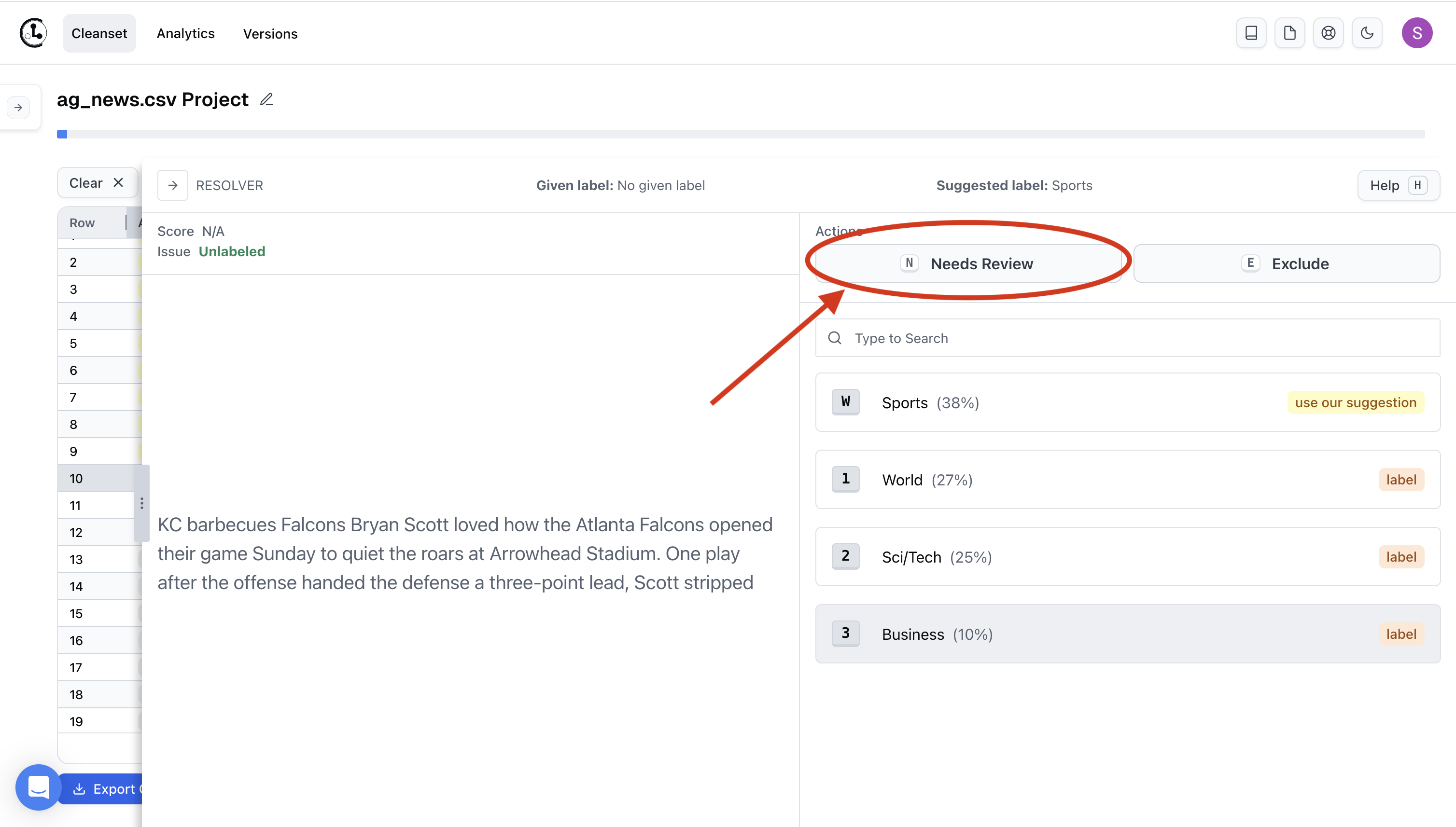
If you’d prefer to review data points one-at-a-time, click on a row of data to open the Resolver panel where you can select a class label for this data point. Even though you’re going through the data points one-by-one, you’ll benefit from Cleanlab’s suggested label(s) in the Resolver window.
Basic row-by-row labeling workflow
The video below demonstrates using the Resolver panel to manually label individual data points that Cleanlab is less confident about. To label, select a data point by clicking on it and use keyboard shortcuts to take actions like: label, exclude, tag, etc. Or use the mouse and click on the label buttons!
Wto auto-fix (apply Cleanlab Studio’s recommended action, such as a suggested label for unlabeled data)Nto add the “Needs Review” tag (so your team revisits this data point later)Qto keep the given labelEto exclude the data point from the dataset1…9to label as a particular class, amongst top 9 most likely class labels for this data point
Batch Labeling
Cleanlab Studio supports both labeling each row in the dataset one by one, as well as batch labeling a set of rows. Batch labeling allows you to label thousands of data points at once, while simultaneously correcting label errors. To batch label, first use filter/sort the data to pull up the data points you’d like to label simultaneously.
Once you have retrieved the desired data, open the Clean Top K dialog to take a batch action on the top K data points in your current table view. Available actions are Auto-fix (apply our suggested label), Exclude (remove from dataset), Label (apply one label to the selected points), and Needs Review (add a tag to revisit this data later)
Batch labeling can be very powerful when combined with Cleanlab Studio’s filter/sort operations. For instance, consider sorting your data by the Confidence Score column prior to Clean Top K to auto-label the data with most confident predictions. Alternatively, consider sorting your data by the Label Issue Score column prior to Clean Top K to automatically correct data that was likely mislabeled.
Batch labeling / auto-labeling provides a good starting point that can be rapidly iterated on. Individual labeling is good option for those last few examples Cleanlab indicates low-confidence in.
In the video below, we batch label the top 25 unlabeled examples that received a suggested label for the Business class.
Other useful actions
Multi-select. Beyond individual/batch-labeling, you can alternatively click-and-drag / multi-select to highlight multiple data points and simultaneously label or otherwise act upon them. This is helpful in filtered/sorted data views where you want to apply the same action to a few adjacent data points. In the below video, we filter for data points exhibiting the Non-English issue, select them all, and Exclude these selected rows from our dataset.
Analytics. Amongst other things, the Analytics page shows which types of label errors are most common in your dataset, as well as which data sources are the most error prone. In the below video, we see there are overall label errors in Sci/Tech class of the dataset, and click on this bar to see which data points these are specifically. One powerful workflow is: using the Analytics page to jump into a particularly informative filtered view of the data and applying batch actions in this view.
Needs Review. If you spot data points that you’re unsure how to handle, use the Needs Review tag to mark them. Your team can later revisit them by filtering for the tag.
Improve the Quality of Suggested Labels and Detected Data Issues
After making some changes to the dataset, you can (optionally) improve the quality of suggested labels and detected data issues by clicking the Improve Issues Found button (shown below).
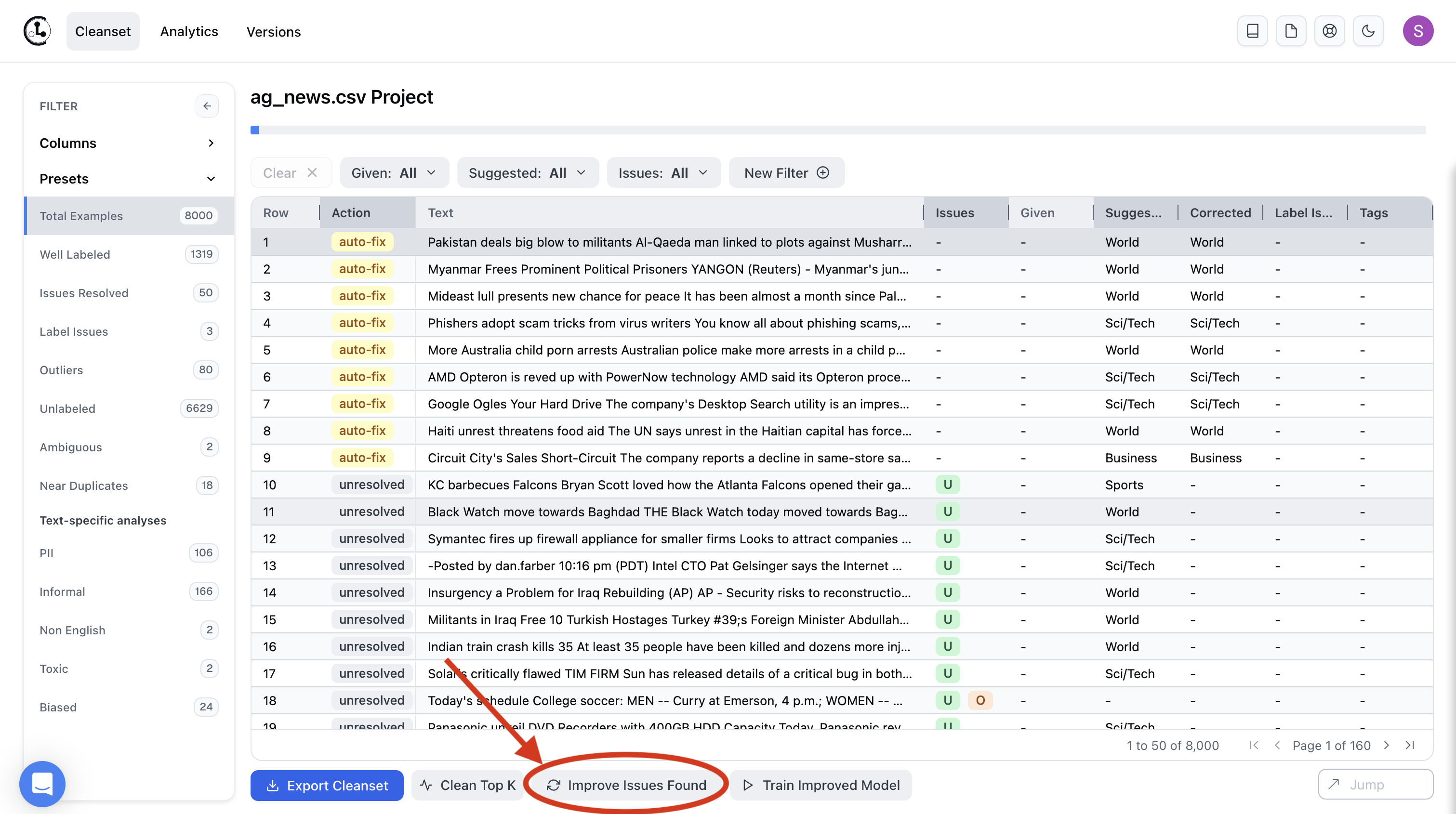
This will retrain Cleanlab Studio’s ML model on the updated dataset (with new labels you just added/corrected as well as excluding bad data you marked). Trained with better data, the resulting model can more accurately/confidently suggest labels for any data that still remains unlabeled as well as better detect remaining data issues. Once the Project is again Ready for Review, the labels corrected and assigned in previous runs will now appear in the Given column. A new version of the dataset is snapshotted, and any further labels you add will appear in the Corrected column. View previous versions of the dataset under the Versions tab, and see the Cleanset guide for more details.
For the best end-result, you can iteratively repeat this human-in-the-loop AI workflow in multiple rounds – each time labeling a bit more data and curating the dataset before retraining the ML model to learn from your latest supervision. For instance, an end-to-end labeling effort might look like this:
- First manually label 0.1% of your data
- Launch a Cleanlab Studio Project and auto-label 5% of the data in the auto-labeling wizard
- Manually label another 0.1% in the auto-labeling wizard
- Auto-label 10% in the subsequent regular Cleanlab Studio Project workflow
- Manually label and correct another 0.1% of the data via the Resolver panel
- Hit
Improve Issues Foundto retrain the AI system and then auto-label the remaining 85% of the data, now that the AI has become accurate enough.
Export your labeled dataset
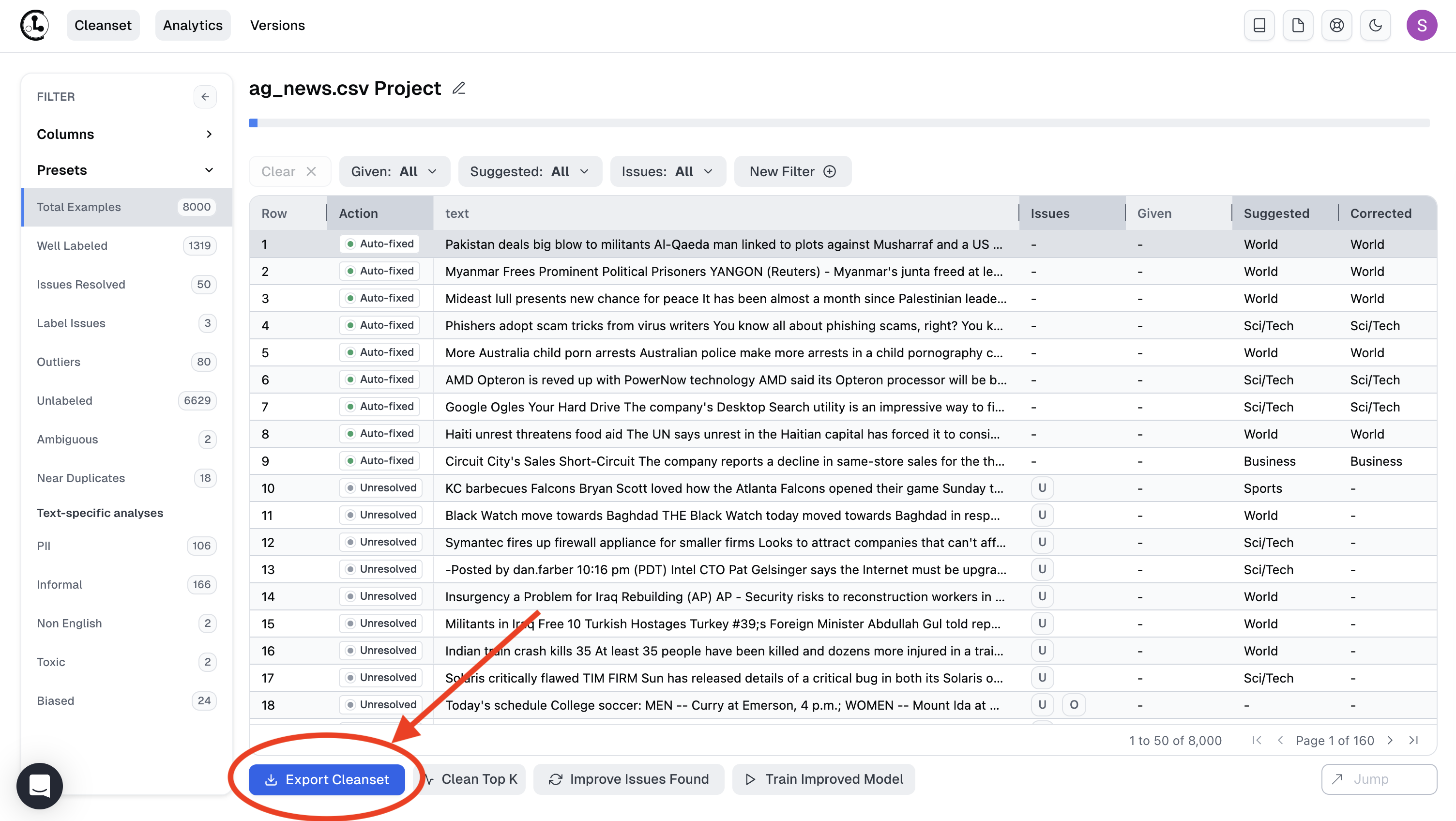
Now that you’ve labeled the dataset and possibly also resolved data issues, export your cleanset (cleaned dataset) via Export Cleanset button.
Python API instructions (optional)
You can alternatively export programmatically via our Python API. Retrieve the Cleanset ID from the Export with API option in the Export Cleanset dialog box, and then use the download_cleanlab_columns method:
from cleanlab_studio import Studio
import pandas as pd
studio = Studio('YOUR_API_KEY')
df = studio.download_cleanlab_columns('YOUR_CLEANSET_ID')
The cleanset is exported as a CSV file. Here, labels assigned via the auto-labeling wizard can be found in the column you designated as the label when creating your Project. New labels assigned (and any label corrections) in the regular Cleanlab Studio Project workflow can be found in the cleanlab_corrected_label column. The screenshot below shows the exported CSV and the relevant columns that can be used to construct your final labeled and cleaned dataset.
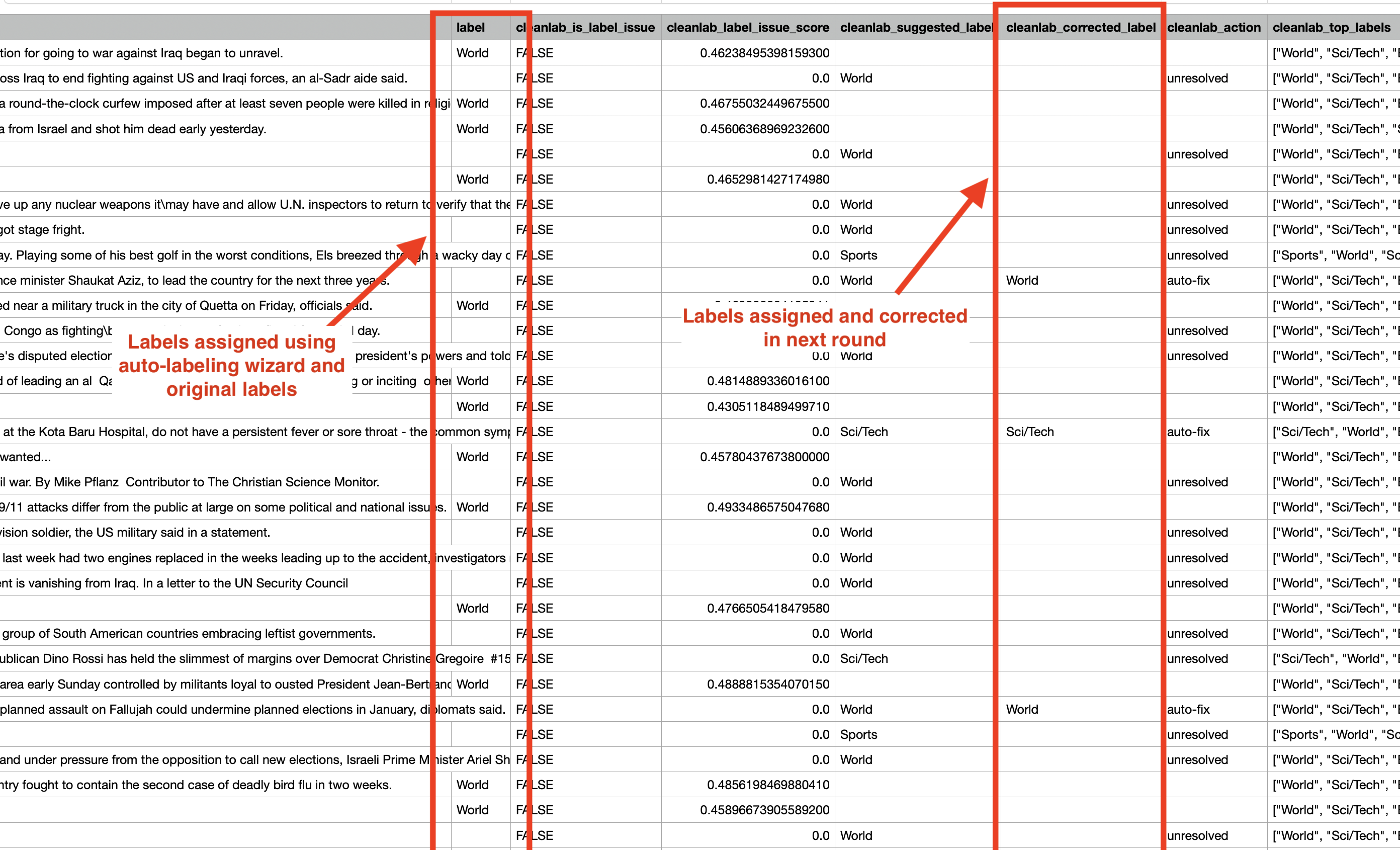
To obtain a final labeled dataset after (re)labeling data in both the auto-labeling wizard and regular Cleanlab Studio Project workflow, update the values in the column you had designated as the label with any corresponding values appearing in the cleanlab_corrected_label column. Data points with Null label value and no corresponding value in the cleanlab_corrected_label column remain unlabeled.
Using Python, you can obtain your final dataset labels as follows:
cleanlab_columns = pd.read_csv("cleanlab_columns.csv")
cleanlab_columns["final_label"] = cleanlab_columns['cleanlab_corrected_label'].fillna(cleanlab_columns['label'])
Bonus: Making the most of your labeled data with the Cleanlab’s ML model deployment
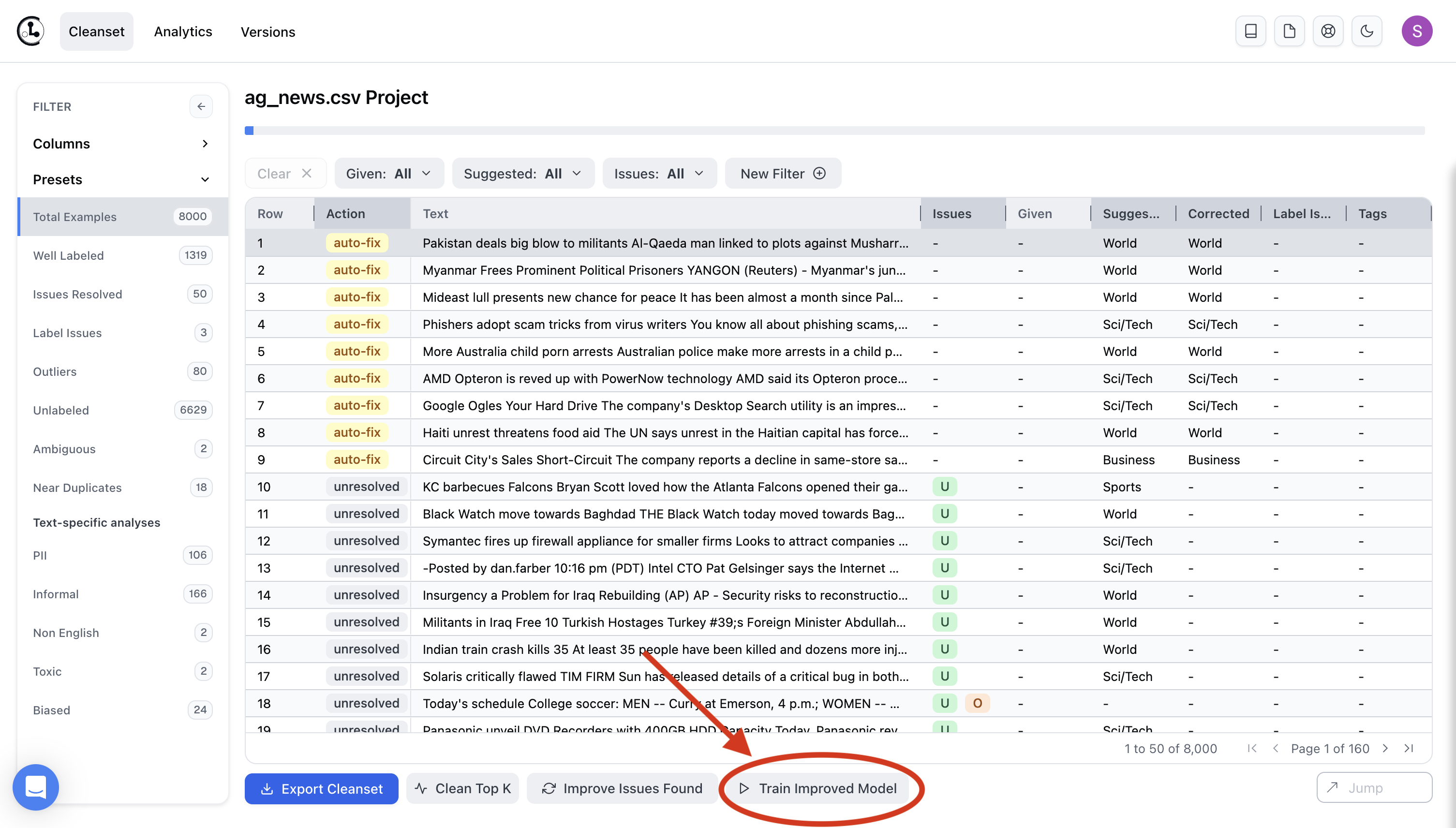
You’ve labeled your dataset — now what? In addition to using your cleaned and labeled data for all the tasks you were previously tackling with the smaller/noisier original dataset, Cleanlab Studio can also immediately use your data for training a state-of-the-art ML model. With one click, you can deploy this model to serve accurate predictions for new data. This is great if you have even more unlabeled data to handle (say, some that came in after you generated your initial dataset). Click Train Improved Model on the bottom of the page, and Cleanlab Studio will automatically train a model on your cleaned data and deploy it for use in production.
Learn more via our inference API tutorial, and note you can also get predictions for new data simply by dragging a file of test data to your deployed model in our Web Interface. Cleanlab Studio offers the fastest path to label data, curate/clean it, and train/deploy accurate ML.