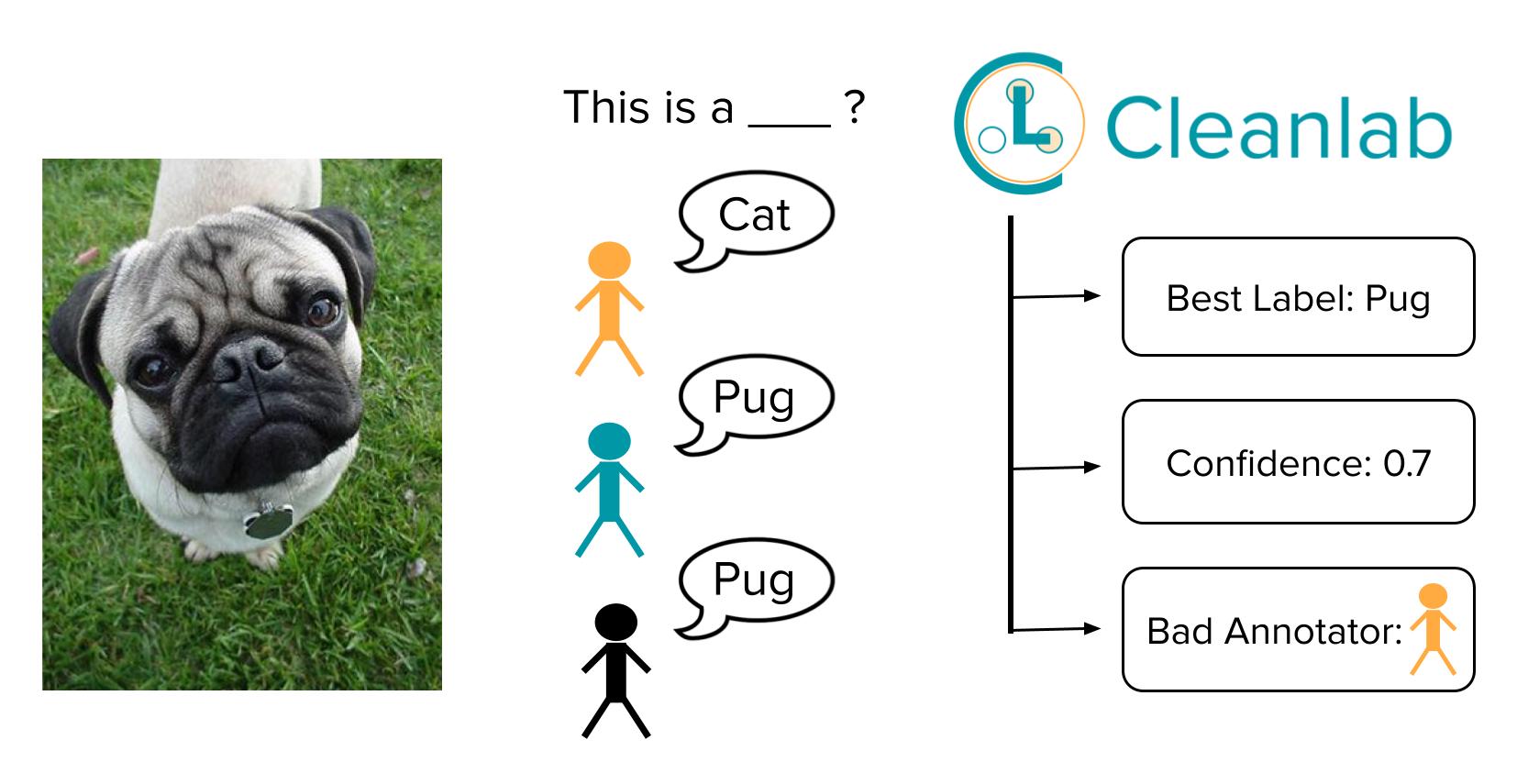
Estimate Consensus and Annotator Quality for Data Labeled by Multiple Annotators

This tutorial shows how to use Cleanlab Studio’s Python API for classification data that has been labeled by multiple annotators (where each data point has been labeled by at least one annotator, but not every annotator has labeled every data point). Asking multiple annotators to label some of the same data is common when any one annotator may not provide perfect labels. For instance, some data points in the dataset may have received 3 labels (from 3 different annotators), while other data points have only received a single label (from one annotator).
Compared to existing crowdsourcing tools, Cleanlab Studio helps you better analyze such data by leveraging a trained classifier model in addition to the raw annotations. With few lines of code, you can automatically compute:
- A consensus label for each data point (i.e. truth inference) that aggregates the individual annotations (more accurately than algorithms from crowdsourcing like majority-vote, Dawid-Skene, or GLAD).
- A quality score for each consensus label which measures our confidence that this label is correct (via well-calibrated estimates that account for the: number of annotators which have labeled this data point, overall quality of each annotator, and quality of our trained ML models).
- An analogous label quality score for each individual label chosen by one annotator for a particular data point (to measure our confidence in alternate labels when annotators differ from the consensus).
- An overall quality score for each annotator which measures our confidence in the overall correctness of labels obtained from this annotator.
Consensus labels represent the best guess of the true label for each data point and can be used for more reliable modeling/analytics. Cleanlab automatically produces enhanced estimates of consensus through the use of machine learning. Quality scores help us determine how much trust we can place in each: consensus label, individual annotator, and particular label from a particular annotator. These quality scores can help you determine which annotators are best/worst overall, as well as which current consensus labels are least trustworthy and should perhaps be verified via additional annotation.
Install and import required dependencies
You can use pip to install all packages required for this tutorial as follows:
%pip install cleanlab cleanlab-studio
import numpy as np
import pandas as pd
from cleanlab_studio import Studio
from cleanlab.multiannotator import get_label_quality_multiannotator, get_majority_vote_label
Format Data (can skip these details)
This tutorial uses a toy tabular dataset but these same steps can easily be applied to image or text data labeled by multiple annotators. We generate a toy dataset that has 50 annotators and 300 data points from three possible classes: 0, 1 and 2.
Each annotator annotates approximately 10% of the data points. We purposefully made the last 5 annotators in our toy dataset provide much noisier labels than the rest of the annotators.
Solely for evaluating Cleanlab Studio’s consensus labels against other consensus methods, we here also generate the true labels for this example dataset. However, true labels are not required for any of Cleanlab Studio’s multi-annotator functions (and they usually are not available in real applications).
We generate our multiannotator data via the make_data() method (can skip these details).
Optional: Initialize helper method to make multiannotator dataset
from cleanlab.benchmarking.noise_generation import generate_noise_matrix_from_trace
from cleanlab.benchmarking.noise_generation import generate_noisy_labels
SEED = 111 # set to None for non-reproducible randomness
np.random.seed(seed=SEED)
def make_data(
means=[[3, 2], [7, 7], [0, 8]],
covs=[[[5, -1.5], [-1.5, 1]], [[1, 0.5], [0.5, 4]], [[5, 1], [1, 5]]],
sizes=[150, 75, 75],
num_annotators=50,
):
m = len(means) # number of classes
n = sum(sizes)
local_data = []
labels = []
for idx in range(m):
local_data.append(
np.random.multivariate_normal(mean=means[idx], cov=covs[idx], size=sizes[idx])
)
labels.append(np.array([idx for i in range(sizes[idx])]))
X_train = np.vstack(local_data)
true_labels_train = np.hstack(labels)
# Compute p(true_label=k)
py = np.bincount(true_labels_train) / float(len(true_labels_train))
noise_matrix_better = generate_noise_matrix_from_trace(
m,
trace=0.8 * m,
py=py,
valid_noise_matrix=True,
seed=SEED,
)
noise_matrix_worse = generate_noise_matrix_from_trace(
m,
trace=0.35 * m,
py=py,
valid_noise_matrix=True,
seed=SEED,
)
# Generate our noisy labels using the noise_matrix for specified number of annotators.
s = pd.DataFrame(
np.vstack(
[
generate_noisy_labels(true_labels_train, noise_matrix_better)
if i < num_annotators - 5
else generate_noisy_labels(true_labels_train, noise_matrix_worse)
for i in range(num_annotators)
]
).transpose()
)
# Each annotator only labels approximately 10% of the dataset
# (unlabeled points represented with NaN)
s = s.apply(lambda x: x.mask(np.random.random(n) < 0.9)).astype("Int64")
s.dropna(axis=1, how="all", inplace=True)
s.columns = ["A" + str(i).zfill(4) for i in range(1, num_annotators+1)]
row_NA_check = pd.notna(s).any(axis=1)
return {
"X_train": X_train[row_NA_check],
"true_labels_train": true_labels_train[row_NA_check],
"multiannotator_labels": s[row_NA_check].reset_index(drop=True),
}
data_dict = make_data()
X = data_dict["X_train"]
multiannotator_labels = data_dict["multiannotator_labels"]
true_labels = data_dict["true_labels_train"] # used for comparing the accuracy of consensus labels
Let’s view the first few rows of the data used for this tutorial. Here are the labels selected by each annotator for the first few examples (rows) in the dataset:
multiannotator_labels.head()
| A0001 | A0002 | A0003 | A0004 | A0005 | A0006 | A0007 | A0008 | A0009 | A0010 | ... | A0041 | A0042 | A0043 | A0044 | A0045 | A0046 | A0047 | A0048 | A0049 | A0050 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | ... | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> |
| 1 | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | 0 | <NA> | <NA> | <NA> | ... | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> |
| 2 | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | ... | <NA> | 0 | <NA> | <NA> | <NA> | <NA> | <NA> | 2 | <NA> | <NA> |
| 3 | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | 2 | <NA> | <NA> | <NA> | ... | 0 | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> |
| 4 | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | ... | <NA> | <NA> | <NA> | 2 | <NA> | <NA> | 0 | <NA> | <NA> | <NA> |
5 rows × 50 columns
Here are the corresponding features for these data points:
X[:5]
multiannotator_labels contains the class label that each annotator chose for each data point, with data points that a particular annotator did not label represented using np.nan.
X contains the features for each data point, which happen to be numeric in this tutorial but any feature modality can be used. Check out Bringing Your Own Data to learn how to run Cleanlab Studio with multi-annotator data of other modalities.
Get Initial Consensus Labels via Majority Vote
We first obtain initial consensus labels from the data annotations representing a crude guess of the best label for each data point. The most straight forward way to obtain an initial set of consensus labels is via simple majority vote.
majority_vote_label = get_majority_vote_label(multiannotator_labels)
Train model and Compute Out-of-Sample Predicted Probabilities
Majority vote consensus labels may not be very reliable, particularly for data points that were only labeled by one or a few annotators. To more reliably estimate consensus, we can account for the features associated with each data point (based on which the annotations were derived in the first place). Fitting a classifier model serves as a natural way to account for these feature values, here we show how to train and utilize such a classifier to get significantly more accurate estimates of consensus labels and associated quality scores.
We use the Cleanlab Studio Python API to train a model with our initial consensus labels, and then get (out-of-sample) predicted class probabilities for each data point from the trained model. These predicted probabilities help us estimate the best consensus labels and associated confidence values in a statistically optimal manner that accounts for all the available information.
# you can find your API key by going to studio.cleanlab.ai/upload,
# clicking "Upload via Python API", and copying the API key there
API_KEY = "<YOUR_API_KEY>"
# initialize studio object
studio = Studio(API_KEY)
# upload dataset
formatted_dataframe = pd.DataFrame(X)
formatted_dataframe["label"] = majority_vote_label
# set schema for all feature columns to float
schema_overrides = [{"name": str(col), "column_type": "float"} for col in formatted_dataframe.columns if col != "label"]
dataset_id = studio.upload_dataset(formatted_dataframe, dataset_name='multiannotator_tutorial', schema_overrides=schema_overrides)
print(f'Uploaded dataset_id: {dataset_id}')
# launch project
project_id = studio.create_project(dataset_id,
project_name='multiannotator_tutorial_itter',
modality='tabular',
model_type='fast',
label_column='label',
)
print(f'Project successfully created and training has begun! project_id: {project_id}')
Once the Project has been launched successfully and you see your project_id you can feel free to close this notebook. It will take some time for Cleanlab’s AI to train on your data and analyze it. Come back after training is complete (you’ll receive an email). You can also poll for a Project’s status to programmatically wait until the results are ready for review as done below. You can optionally provide a timeout parameter after which the function will stop waiting even if the project is not ready.
Warning! This next cell may take a long time to execute for big datasets. If your Jupyter notebook has timed out during this process, then you can resume work by re-running the cell (which should return instantly if the Project has completed; do not create a new Project).
cleanset_id = studio.get_latest_cleanset_id(project_id)
studio.wait_until_cleanset_ready(cleanset_id)
# Fetch predicted class probabilities for each data point:
pred_probs = studio.download_pred_probs(cleanset_id)
pred_probs = pred_probs.to_numpy()
Get Better Consensus Labels and Other Statistics
Using the annotators’ labels and the (out-of-sample) predicted class probabilities from the model, Cleanlab can estimate improved consensus labels for our data that are more accurate than our initial consensus labels were.
Having accurate labels provides insight on each annotator’s label quality and is key for boosting model accuracy and achieving dependable real-world results.
In the case of notebook timeout or closing of notebook, rerun the cells up to Get Initial Consensus Labels via Majority Vote section. You can manually get your pred_probs by using the project_id printed above and running the code below.
studio = Studio(api_key)
cleanset_id = studio.get_latest_cleanset_id(project_id)
studio.wait_until_cleanset_ready(cleanset_id)
pred_probs = studio.download_pred_probs(cleanset_id)
pred_probs = pred_probs.to_numpy()
If you do not know the project_id (and it is not printed above) then you can get it from the Cleanlab Studio Web Client from the Name column in the Projects section. The ID is the alpha-numeric key that follows the name and can be copied directly.
results = get_label_quality_multiannotator(multiannotator_labels, pred_probs, verbose=False)
This multiannotator.get_label_quality_multiannotator() function returns a dictionary containing three items:
label_qualitywhich gives us the improved consensus labels using information from each of the annotators and the model. The DataFrame also contains information about the number of annotations, annotator agreement and consensus quality score for each data point. Higher values indicate greater confidence the consensus label is correct (unlike for many of Cleanlab’s issue scores).
results["label_quality"].head()
| consensus_label | consensus_quality_score | annotator_agreement | num_annotations | |
|---|---|---|---|---|
| 0 | 0 | 0.658649 | 0.5 | 2 |
| 1 | 0 | 0.677441 | 1.0 | 3 |
| 2 | 0 | 0.653613 | 0.6 | 5 |
| 3 | 0 | 0.676104 | 0.6 | 5 |
| 4 | 0 | 0.719407 | 0.8 | 5 |
detailed_label_qualitywhich returns the label quality score for each label given by every annotator. Higher values indicate greater confidence the label is correct (unlike for many of Cleanlab’s issue scores).
results["detailed_label_quality"].head()
| quality_annotator_A0001 | quality_annotator_A0002 | quality_annotator_A0003 | quality_annotator_A0004 | quality_annotator_A0005 | quality_annotator_A0006 | quality_annotator_A0007 | quality_annotator_A0008 | quality_annotator_A0009 | quality_annotator_A0010 | ... | quality_annotator_A0041 | quality_annotator_A0042 | quality_annotator_A0043 | quality_annotator_A0044 | quality_annotator_A0045 | quality_annotator_A0046 | quality_annotator_A0047 | quality_annotator_A0048 | quality_annotator_A0049 | quality_annotator_A0050 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | NaN | NaN | NaN | NaN | NaN | NaN | 0.677441 | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | 0.653613 | NaN | NaN | NaN | NaN | NaN | 0.211487 | NaN | NaN |
| 3 | NaN | NaN | NaN | NaN | NaN | NaN | 0.209905 | NaN | NaN | NaN | ... | 0.676104 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | 0.204992 | NaN | NaN | 0.719407 | NaN | NaN | NaN |
5 rows × 50 columns
annotator_statswhich gives us the annotator quality score for each annotator, alongisde other information such as the number of examples that each annotator labeled, their agreement with the consensus labels, and the class they perform the worst at. Once again, higher values indicate an annotator that provides better-quality labels.
results["annotator_stats"].head(10)
| annotator_quality | agreement_with_consensus | worst_class | num_examples_labeled | |
|---|---|---|---|---|
| A0050 | 0.255696 | 0.208333 | 2 | 24 |
| A0047 | 0.305218 | 0.294118 | 2 | 34 |
| A0046 | 0.329592 | 0.346154 | 1 | 26 |
| A0049 | 0.332533 | 0.310345 | 1 | 29 |
| A0048 | 0.427690 | 0.480000 | 2 | 25 |
| A0031 | 0.528278 | 0.580645 | 2 | 31 |
| A0034 | 0.535969 | 0.607143 | 2 | 28 |
| A0021 | 0.591416 | 0.718750 | 1 | 32 |
| A0011 | 0.608669 | 0.692308 | 1 | 26 |
| A0015 | 0.630962 | 0.678571 | 2 | 28 |
The annotator_stats DataFrame is sorted by increasing annotator_quality, showing us the worst annotators first.
Notice that in the above table annotators with ids A0046 to A0050 have the worst annotator quality score, which is expected because we made the last 5 annotators systematically worse than the rest.
Comparing improved consensus labels
We can get the improved consensus labels from the label_quality DataFrame shown above.
improved_consensus_label = results["label_quality"]["consensus_label"].values
Since our toy dataset is synthetically generated by adding noise to each annotator’s labels, we know the ground truth labels for each data point. Hence we can compare the accuracy of the consensus labels obtained using majority vote, and the improved consensus labels obtained using Cleanlab.
majority_vote_accuracy = np.mean(true_labels == majority_vote_label)
cleanlab_label_accuracy = np.mean(true_labels == improved_consensus_label)
print(f"Accuracy of majority vote labels = {majority_vote_accuracy}")
print(f"Accuracy of Cleanlab consensus labels = {cleanlab_label_accuracy}")
We can see that the accuracy of the consensus labels improved as a result of using Cleanlab, which not only takes the annotators’ labels into account, but also a model to compute better consensus labels.
Inspecting consensus quality scores to find potential consensus label errors
We can get the consensus quality score from the label_quality DataFrame shown above.
consensus_quality_score = results["label_quality"]["consensus_quality_score"]
Besides obtaining improved consensus labels, Cleanlab also computes consensus quality scores for each data point. Lower scores represent consensus labels that are less likely correct (consider collecting another annotation for low-scoring data points).
Here, we will extract 15 data points that have the lowest consensus quality score, and we can compare their average accuracy when compared to the true labels. We will also compute the average accuracy for the rest of the examples (rows) in the dataset for comparison.
sorted_consensus_quality_score = consensus_quality_score.sort_values()
worst_quality = sorted_consensus_quality_score.index[:15]
better_quality = sorted_consensus_quality_score.index[15:]
worst_quality_accuracy = np.mean(true_labels[worst_quality] == improved_consensus_label[worst_quality])
better_quality_accuracy = np.mean(true_labels[better_quality] == improved_consensus_label[better_quality])
print(f"Accuracy of 15 worst quality examples = {worst_quality_accuracy}")
print(f"Accuracy of better quality examples = {better_quality_accuracy}")
We observe that the 15 worst-consensus-quality-score data points have a lower average accuracy compared to the rest of the examples in the dataset. Cleanlab automatically determines which consensus labels are least trustworthy (perhaps want to have another annotator look at that data). Here we see these trustworthiness estimates really do correspond to the true quality of the consensus labels (which we know in this toy dataset because we have the true labels, unlike in your applications)
Retrain model using improved consensus labels
After obtaining accurately-estimated consensus labels, you could again use Studio to retrain a better machine learning model using these better consensus labels. To retrain a model, follow the steps in Train Model and Compute Out-of-Sample Predicted Probabilities now setting the consensus labels to their improved counterparts like so: formatted_dataframe['label'] = improved_consensus_label.
To quickly deploy this improved model for making predictions on new data, check out the Deploying Reliable Models in Production tutorial.
Further model improvements
You can also repeat this process of getting better consensus labels using the model’s out-of-sample predicted probabilities and then retraining the model with the improved labels to get even better predicted class probabilities in a virtuous cycle!
Bringing Your Own Data?
If your data are tabular (with each row corresponding to a different data point), you can replace the formatted_dataframe object in the Train Model and Compute Out-of-Sample Predicted Probabilities step above with your own multi-annotator labels and features. Then continue directly with the rest of the tutorial.
Formatting Labels from Multiple Annotators
multiannotator_labels should be a numpy array or pandas DataFrame with each column representing an annotator and each row representing a data point. Your labels should be represented as integer indices 0, 1, …, num_classes - 1, where data points that are not annotated by a particular annotator are represented using np.nan or pd.NA. If you have string labels or other labels that do not fit the required format, like individual lists of labels per annotator then you can convert them to the proper format using cleanlab.internal.multiannotator_utils.format_multiannotator_labels like so:
from cleanlab.internal.multiannotator_utils import format_multiannotator_labels
annotator0_labels = ["question", "statement", "question"] # List of labels from annotator 0
annotator1_labels = ["statement", "statement", "question"] # List of labels from annotator 1
string_multiannotator_labels = pd.DataFrame(zip(annotator0_labels, annotator1_labels)) # Each annotator's labels are represent as a column of the DataFrame object.
display(string_multiannotator_labels)
| 0 | 1 | |
|---|---|---|
| 0 | question | statement |
| 1 | statement | statement |
| 2 | question | question |
You can then use format_multiannotator_labels() function to transform the string labels into numerical values as required by Cleanlab. The function will return multiannotator_labels that are properly formatted to be passed to any cleanlab.multiannotator functions as well a dictionary label_map showing the mapping of new to old labels, such that mapping[k] returns the string name of the k-th class. Afterwards, you can use Cleanlab functionality to either get the Majority Vote Labels or the Improved Consensus Labels depending on if you have predicted probabilites available from a trained classifier yet.
multiannotator_labels, label_map = format_multiannotator_labels(string_multiannotator_labels)
display(multiannotator_labels)
majority_vote_labels = get_majority_vote_label(multiannotator_labels) # Example of getting majority vote labels with the formatted data
| 0 | 1 | |
|---|---|---|
| 0 | 0 | 1 |
| 1 | 1 | 1 |
| 2 | 0 | 0 |
Working with Features of Different Modalities
Your features can be represented however you like as long as they are in a format accepted by Cleanlab Studio! The feature columns can stay in these acceptable formats when creating the dataset to be passed into Studio. For example, if you are working with an Image Dataset the feature column can contain an external url linking to the image file or use individual pixel values as feature columns. If following the Large Scale Image Dataset tutorial, you could replace the class_name csv column with majority_vote_labels.
If you are unsure on the proper data format, use the How to Format Your Dataset wizard on Cleanlab Studio’s Upload page (in the web browser) to see the best way to create feature columns for your specific type of data.
Creating and Uploading a Custom Dataset into Studio
Note that (as demonstrated earlier in this tutorial) prior to data upload (studio.upload_dataset), you should first produce initial consensus labels (eg. via majority-vote) and only upload those initial consensus labels (not the raw multi-annotator labels)!
After using Cleanlab to generate a single set of initial consensus labels (eg. the majority_vote_labels above), you can create a formatted_dataframe to input directly into studio.upload_dataset().
The DataFrame should contain a “label” column (containing the initial consensus label) and one or more feature columns. The “label” column must contain a single class for each data point (row), while the features can be represented in any acceptable format discussed above.
Below is an example of creating a formatted_dataframe object from a basic text dataset (with a single feature column “sentence”). From here, you can continue with the rest of the tutorial above by uploading this dataset to Cleanlab Studio.
sentences = ["We are running", "I like cake.", "Do you like dogs?"]
formatted_dataframe = pd.DataFrame(sentences, columns=["sentence"])
formatted_dataframe["label"] = majority_vote_labels
display(formatted_dataframe.head())
# dataset_id = studio.upload_dataset(formatted_dataframe, dataset_name='multiannotator_tutorial_custom_dataframe_example') # Optional upload custom dataset to Cleanlab Studio on your own
| sentence | label | |
|---|---|---|
| 0 | We are running | 0 |
| 1 | I like cake. | 1 |
| 2 | Do you like dogs? | 0 |
How does our algorithm work?
All estimates above are produced via the CROWDLAB algorithm, described in this paper that contains extensive benchmarks which show CROWDLAB can produce better estimates than popular methods like Dawid-Skene and GLAD: