Deploying Reliable ML Models in Production

In this tutorial, we’ll use Cleanlab Studio to train a reliable ML model on raw data and deploy it in production with a single click. Using the deployed model, we can obtain predictions on new data using Cleanlab Studio’s Python API.

We’ll work with a dataset from Web Data Commons where the ML task is to classify products based on their text descriptions. Model deployment works similarly for tabular and image datasets. The text classification dataset for this tutorial contains titles, descriptions, and category labels for 23,000 products on Amazon. It looks like this:
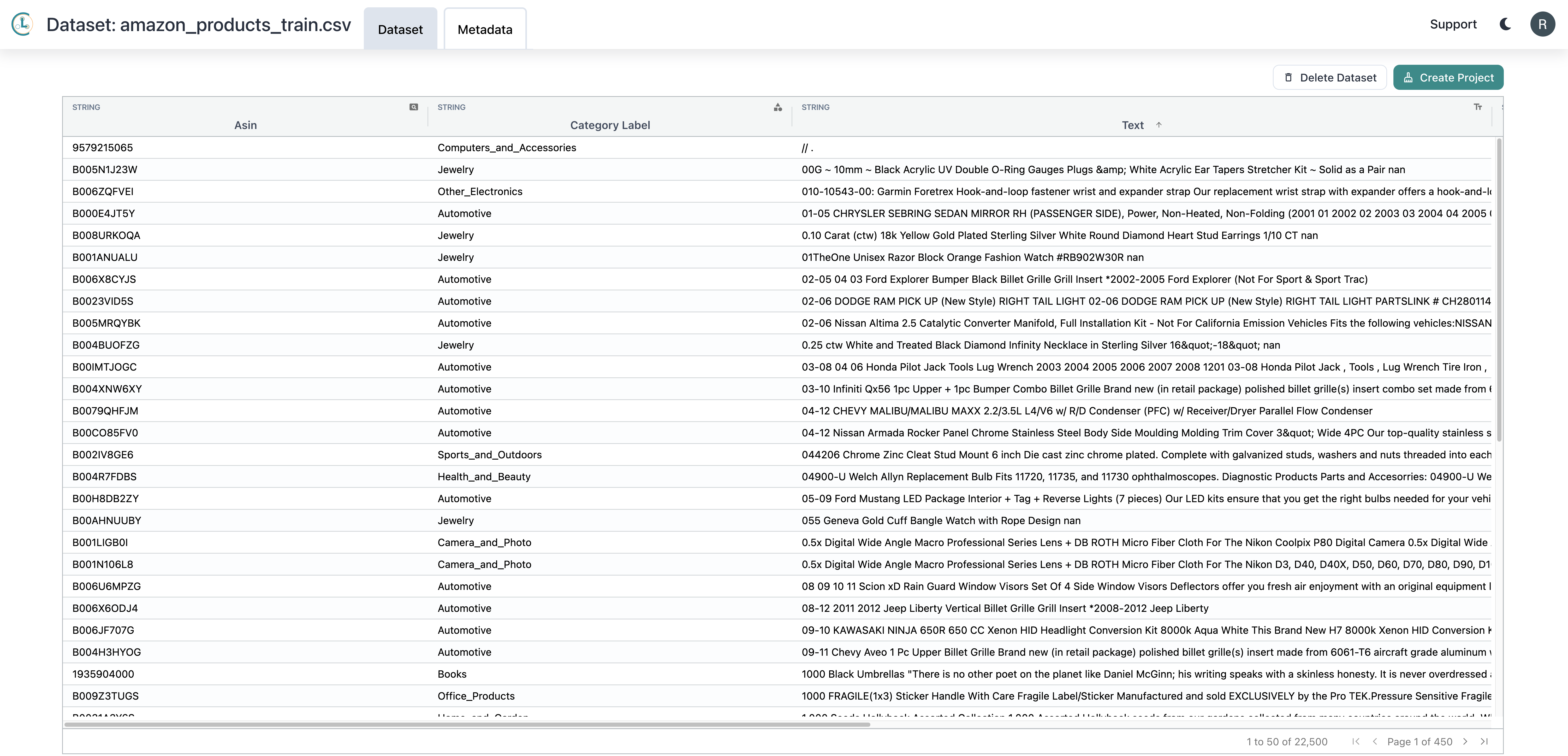
For the above dataset, we’ll train and deploy a reliable model that can be used to automatically classify the category of new products:
>>> model.predict(['$100 Dollar Bill Design (Benjamin) Eraser'])
['Office_Products']
Here we are running model deployment with a multi-class text dataset. Cleanlab Studio can similarly auto-train and deploy ML models for many other data modalities, as well as for multi-label datasets.
Motivation
For online retailers like Amazon, product classification is a highly important task. Reliable product classification allows customers to find products and retailers to suggest related products — both of which are crucial to making sales and generating revenue!
As with any classification task, the quality of the data going in has a tremendous effect on the quality of the inferences generated by the model. For a retailer like Amazon, the initial labels might be created by a team of annotators who are paid for each example they annotate. The quality of these labels will not always be high.
The underlying data itself can be suspect. Datasets will often contain duplicate, null, or corrupted examples — all of which will impact the performance of the model trained on the dataset.
Using Cleanlab Studio, training a model begins with cleaning your dataset, a process made easy by our algorithms which automatically find data and label issues and recommend actions to fix them. Once you have a clean dataset, with a single click, Cleanlab Studio’s autoML can train and deploy a reliable model suitable for use in a production setting.
Install and Import Required Dependencies
You can use pip to install all packages required for this tutorial as follows:
%pip install cleanlab-studio
from cleanlab_studio import Studio
import pandas as pd
Optional: Initialize helper method to render dataframes
from IPython.core.display import HTML
def display(data) -> None:
return HTML(data.to_html(escape=False))
Prepare and Upload Dataset
In this tutorial, we want to train a text-based ML model that predicts the category label based on a single text field. Let’s first load the original dataset and see what it looks like:
df = pd.read_json('https://cleanlab-public.s3.amazonaws.com/StudioDemoDatasets/amazon_training.json')
display(df.head(3))
| asin | brand | categoryLabel | description | title | |
|---|---|---|---|---|---|
| 0 | B000JGEKLK | Rothco | Automotive | USA Antenna Flag - Size: 4.5" x 6". United States Mini Flag For Antennas. US Antenna Flag. | USA Antenna Flag |
| 1 | B004KEIU1S | None | Automotive | Schrader Part #20395 is a 100/box set of plastic sealing valve caps. | Schrader 20395 TPMS Plastic Sealing Valve Cap - Pack of 100 |
| 2 | B005FL767Y | Power Stop | Automotive | Power Stop brake kits include a complete set of cross-drilled and slotted rotors and high performance evolution ceramic pads. It is made simple by matching the pads and rotors for a big brake feel without the big price. The Power Stop brake kit offers more pad bite than other leading brands without noise and dust. If you need a fast, easy and affordable solution for better braking, then you need the Power Stop brake kit. | Power Stop K2434 Rear Ceramic Brake Pad and Cross Drilled/Slotted Combo Rotor One-Click Brake Kit |
Prepare Data
We’d like to use both the title and the description as part of the text that the model uses for predictions. To enable this, we modify the DataFrame so it contains a new column (we call it text) that concates the title and description, separated by a newline.
df['text'] = df['title'] + '\n' + df['description']
display(df.head(3))
| asin | brand | categoryLabel | description | title | text | |
|---|---|---|---|---|---|---|
| 0 | B000JGEKLK | Rothco | Automotive | USA Antenna Flag - Size: 4.5" x 6". United States Mini Flag For Antennas. US Antenna Flag. | USA Antenna Flag | USA Antenna Flag\nUSA Antenna Flag - Size: 4.5" x 6". United States Mini Flag For Antennas. US Antenna Flag. |
| 1 | B004KEIU1S | None | Automotive | Schrader Part #20395 is a 100/box set of plastic sealing valve caps. | Schrader 20395 TPMS Plastic Sealing Valve Cap - Pack of 100 | Schrader 20395 TPMS Plastic Sealing Valve Cap - Pack of 100\nSchrader Part #20395 is a 100/box set of plastic sealing valve caps. |
| 2 | B005FL767Y | Power Stop | Automotive | Power Stop brake kits include a complete set of cross-drilled and slotted rotors and high performance evolution ceramic pads. It is made simple by matching the pads and rotors for a big brake feel without the big price. The Power Stop brake kit offers more pad bite than other leading brands without noise and dust. If you need a fast, easy and affordable solution for better braking, then you need the Power Stop brake kit. | Power Stop K2434 Rear Ceramic Brake Pad and Cross Drilled/Slotted Combo Rotor One-Click Brake Kit | Power Stop K2434 Rear Ceramic Brake Pad and Cross Drilled/Slotted Combo Rotor One-Click Brake Kit\nPower Stop brake kits include a complete set of cross-drilled and slotted rotors and high performance evolution ceramic pads. It is made simple by matching the pads and rotors for a big brake feel without the big price. The Power Stop brake kit offers more pad bite than other leading brands without noise and dust. If you need a fast, easy and affordable solution for better braking, then you need the Power Stop brake kit. |
Upload Dataset
This tutorial focuses on using the Python API, but you can also use our Web UI for a no-code option (click to expand)
If you would like to upload your data without writing code, simply go to https://studio.cleanlab.ai/upload and follow these steps:
- Click “Upload from URL”
- Enter link to dataset (we added the text column here)
- Click “Upload” and wait for the file to upload
- Click “Next”
- Make sure “text” is selected as the dataset modality. Leave everything else on the schema editing page as default
- Click “Confirm”
- Wait for data ingestion to complete
To upload your dataset to Cleanlab Studio using our Python API, use the following code:
# you can find your API key by going to studio.cleanlab.ai/upload,
# clicking "Upload via Python API", and copying the API key there
API_KEY = "<YOUR_API_KEY>"
# authenticate with your API key
studio = Studio(API_KEY)
dataset_id = studio.upload_dataset(df, dataset_name="Product Descriptions")
Clean the Data
Real world data is messy and often contains issues such as label errors, outliers, and duplicate examples. If we use Cleanlab Studio to address these issues and train a model on the improved data, we’ll obtain a model that gives more reliable predictions.
Since cleaning your data using Cleanlab Studio isn’t the main focus of this tutorial, we won’t go into detail on it here. Instead see our Python API or Web UI quickstarts.
Note: make sure you create a text project and use the text column for the predictive column! This will ensure that the model is trained on the column containing the concatenated product titles and descriptions, leading to the highest accuracy.
Label Issue Examples
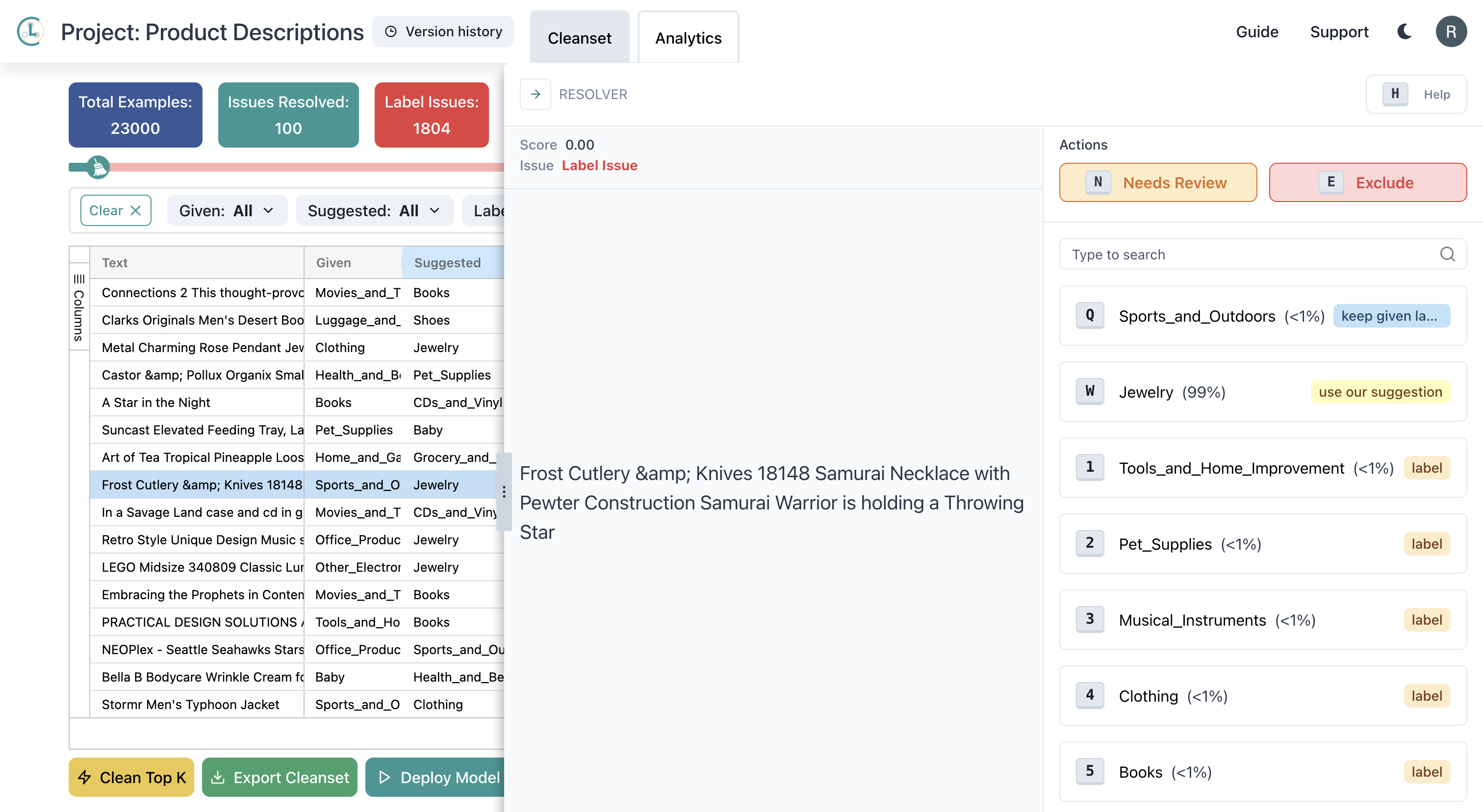
Below, we can see two examples of label issues caught by Cleanlab Studio.
The following data point is labeled Sports_and_Outdoors, but it should be labeled Jewelry:
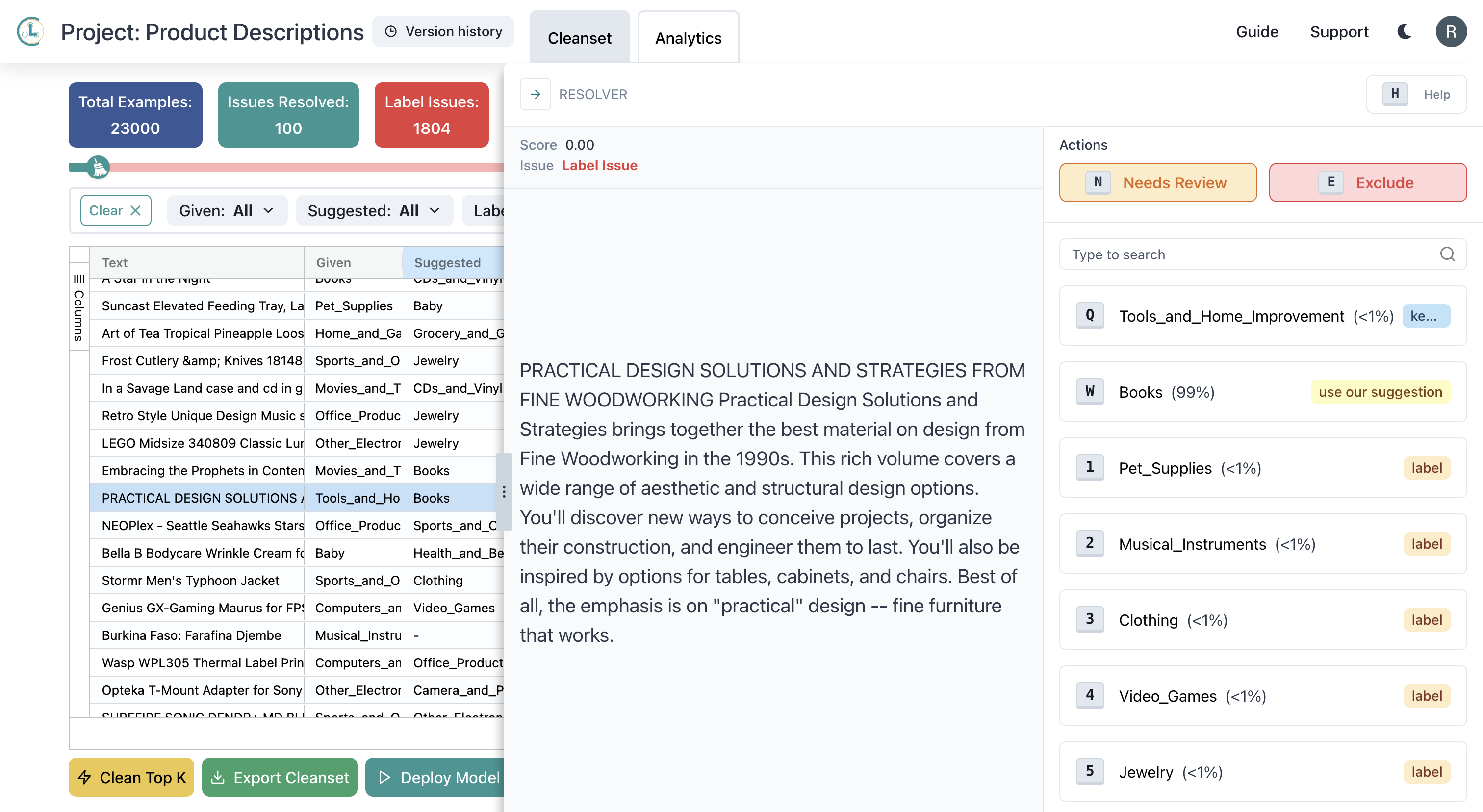
The following data point is labeled Tools_and_Home_Improvement, but it should be labeled Books:
Train a Model
Once you’re happy with your dataset corrections, you can use Cleanlab Studio to automatically train and deploy a model using the cleaned data. To do this, click on the “Deploy Model” button on the project page, name your model, and click deploy. Cleanlab Studio will automatically train many types of ML models, using cutting-edge AutoML to find the best model for your dataset.
Use the Model in Production
Now that you’ve deployed your model, you can use Cleanlab Studio’s Python API to obtain predictions for new data points. For this tutorial, we’ve prepared several batches of samples to run inference on.
Batches for text models (as we’re using in this tutorial) must be provided as lists, NumPy arrays, or Pandas Series of strings. Batches for tabular models must be provided as Pandas DataFrames. For tabular data/models, prediction batches must use contain the same column(s) as the project was trained on.
# load and prepare example test data
batch = pd.read_csv("https://cleanlab-public.s3.amazonaws.com/StudioDemoDatasets/amazon-products/amazon_products_inference_batch_0.csv")
batch_text = batch["text"]
batch_text

# load model from Studio
# you can find your model ID in the models table on the dashboard!
model_id = "<YOUR_MODEL_ID>"
model = studio.get_model(model_id)
predictions = model.predict(batch_text)
display(pd.DataFrame({"text": batch_text, "predictions": predictions}).head(3))
| text | predictions | |
|---|---|---|
| 0 | Tablet Portfolio for iPad Tablets\nTablet Port... | Computers_and_Accessories |
| 1 | Factory-Reconditioned Milwaukee 2471-81 12-Vol... | Tools_and_Home_Improvement |
| 2 | Microsoft Zune Armor Case - The Metal Case (Bl... | Other_Electronics |
We can also obtain the predicted class probabilities for each data point that quantify model confidence.
input_text = batch_text[0]
prediction, pred_probs = model.predict([input_text[0]],return_pred_proba=True)
display(pred_probs)
| Automotive | Baby | Books | CDs_and_Vinyl | Camera_and_Photo | Cellphones_and_Accessories | Clothing | Computers_and_Accessories | Grocery_and_Gourmet_Food | Health_and_Beauty | ... | Movies_and_TV | Musical_Instruments | Office_Products | Other_Electronics | Pet_Supplies | Shoes | Sports_and_Outdoors | Tools_and_Home_Improvement | Toys_and_Games | Video_Games | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.005268 | 0.001317 | 0.000023 | 0.000014 | 0.000998 | 0.000585 | 0.006329 | 0.81058 | 0.000131 | 0.000149 | ... | 0.000041 | 0.000491 | 0.009481 | 0.006538 | 0.000207 | 0.002799 | 0.008199 | 0.001068 | 0.000057 | 0.001213 |
1 rows × 23 columns
(Optional) Since our test data here happen to be labeled, we can evaluate the accuracy of the model predictions against these given labels.
accuracy = sum(predictions==batch['categoryLabel'])/len(predictions)
print(accuracy)
It’s also possible to use our Web UI to get predictions
If you would like to get predictions without writing code, simply go to https://studio.cleanlab.ai/ and follow these steps:
- Click “View model” for the model you created
- Click “Predict new labels”
- Upload a CSV containing the examples you want predictions for
- For text models, your CSV should have a single column
- For tabular models, your CSV should contain all of your predictive columns
- Click “Predict New Labels”
- Wait for inference to complete
- Click “Export” for the query you made
- The exported CSV file will have the probabilitites of each class, along with the predicted label
You now have a model trained on reliable data that is an accurate text classifier! This deployed model is ready to be used in production for real-time queries. You can read about how ML deployed with Cleanlab Studio can be more accurate than even fine-tuned OpenAI LLMs for classifying texts like product reviews or legal judgements.
While we demonstrated text data here, Cleanlab Studio can similarly auto-train and deploy ML models for other data modalities as well.