Curating Heterogenous Document Datasets

This is the recommended quickstart tutorial for analyzing document datasets/collections via Cleanlab Studio’s Python API.
This tutorial demonstrates how to run Cleanlab Studio on diverse document file types like: csv, doc, docx, pdf, ppt, pptx, xls, xlsx.
We first recommend completing our Text Data Quickstart Tutorial to understand how Cleanlab Studio works with text datasets. Here we only demonstrate how to process your document collection into a text dataset within Cleanlab Studio, refer to the Text Data Quickstart Tutorial for next steps after that. You can alternatively extract text from the documents yourself and run Cleanlab Studio on the resulting text dataset.
Install and import required dependencies
Cleanlab’s Python client can be installed using pip:
%pip install --upgrade cleanlab-studio
from cleanlab_studio import Studio
Prepare Dataset
This tutorial considers an example dataset of around 500 business documents of several file types (ppt, pdf, docx). We want to categorize each document into one of these 5 topics: HR, IT, Finance, Sales, Product (this is a multi-class classification task).
Let’s download the dataset in an appropriate format with the following terminal command:
wget -nc 'https://cleanlab-public.s3.amazonaws.com/Datasets/documents_cl_labeled.zip'
Format Your Own Dataset
The same ideas from this tutorial apply to document datasets with other file types and class labels or document tags. You can follow along with your own dataset as long as it is formatted similarly or in other acceptable formats listed in the Document Datasets guide. Below are some more details on how to format a document dataset like the one used in this tutorial.
Dataset Structure
You can directly run Cleanlab Studio on a document dataset, where each document lives in its own file, and the files are organized in a particular directory shown below. In addition to the documents, your top-level directory should contain a file metadata.csv, containing metadata about each document, including any annotated class labels or tags.
Here’s how the directory structure and metadata.csv file should look:
documents_cl
├── metadata.csv
├── file_0.pdf
└── documents
├── optional_subdirectory
│ ├── file_1.ppt
│ └── file_2.pdf
├──file_3.docx ⋮
└──file_4.pdf
⋮
metadata.csv
┌──────────────────────────────────────────────────────┐
│filename │label │
├──────────────────────────────────────────────────────┤
│file_0.ppf │hr │
├──────────────────────────────────────────────────────┤
│documents/optional_subdirectory/file_1.ppt │ │ <── unlabeled example
├────────────────��──────────────────────────────────────┤
│documents/optional_subdirectory/file_2.pdf │sales │
├──────────────────────────────────────────────────────┤
│documents/file_3.docx │it │
├──────────────────────────────────────────────────────┤
│documents/file_4.pdf │ │ <── unlabeled example
├──────────────────────────────────────────────────────┤
│... │... │
└─ ── ── ── ── ── ── ── ── ── ── ── ── ── ── ── ── ── ─┘
-
Parent Directory: In our tutorial,
documents_cl/serves as the top-level directory. It holds all document files and themetadata.csvfile. -
metadata.csv: This manifest must be named
metadata.csvand placed at the top-level directory. It contains mappings between relative filepaths to the documents and metadata about each document in the dataset (such as labels). While the document files in the directory can be of mixed media formats with an arbitrary layout, the metadata must be formatted as a standard CSV file (e.g. use,as the delimiter and"as the quote character). -
Data Directories (Optional): Optional divisions between document files, such as the
optional_subdirectory/anddocuments/sub-directories shown above, may be included for organizational purposes. As long as the metadata file correctly points to the location of the documents (relative paths within these subdirectories), it does not matter how these sub-directories are organized within the top-level directory. -
Unlabeled Data: If there are unlabeled documents you would like labeled: add these files into the folder, and specify their filenames in
metadata.csvwith their correspondinglabelcolumn taking a value Cleanlab will interpret as unlabeled. For multi-class classification datasets, such values include: empty string ("") or None (None,np.nan)). For tagging rather than classifying documents, follow the [multi-label classification guide]((/studio/concepts/datasets/#multi-label) on how to represent unlabeled data. We recommend at least 5 documents labeled for each possible class, in order for Cleanlab’s AutoML system to effectively learn about your data.
Create ZIP file
After it is properly structured, simply zip the your top-level directory. For example, we produced the ZIP file used in this tutorial using the following terminal command:
zip -r documents_cl.zip documents_cl/
Load Dataset into Cleanlab Studio
Now that the data is in an appropriately formatted zip file, let’s load it into Cleanlab Studio. First use your API key to instantiate a studio object.
# Get API key from here: https://studio.cleanlab.ai/account after creating an account
API_KEY = "<API_KEY>"
studio = Studio(API_KEY)
Next let’s load the dataset into Cleanlab Studio, which will require that it has been properly formatted.
dataset_id = studio.upload_dataset(dataset='documents_cl_labeled.zip', dataset_name='document_quickstart_dataset')
print(f"Dataset ID: {dataset_id}")
Begin Document Curation
After your dataset is successfully loaded, it will appear under the Datasets tab in the Cleanlab Studio Web Inferface. The document dataset appears as a text dataset with the text extracted from each document, such that it can be handled like any other text dataset in Cleanlab Studio. Each document is represented as a row in this text dataset, with the document file name listed in a Document column, the Topic column containing the annotations specified in metadata.csv, and a Text column containing the extracted text from this document.
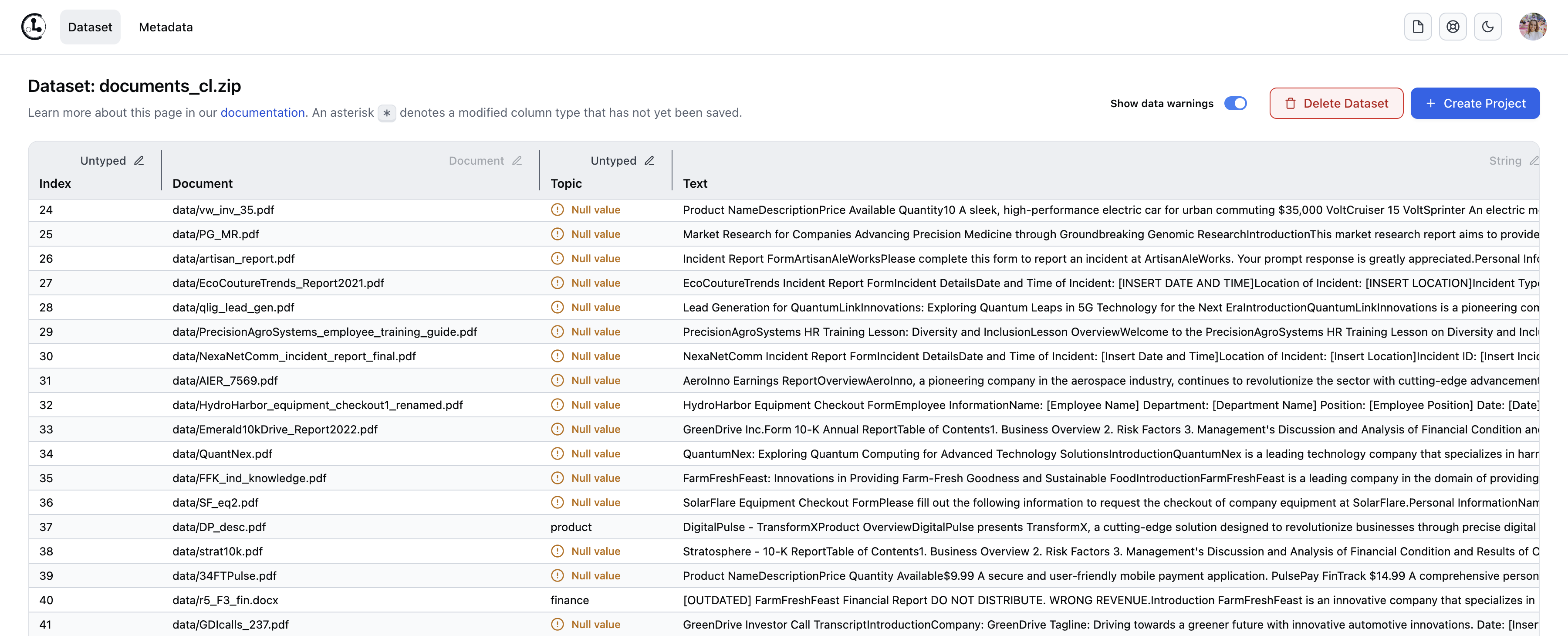
At this point, you can treat your document collection as a text dataset within Cleanlab Studio and run Projects like you would for text datasets. Refer to the Text Data Quickstart Tutorial to understand next steps regarding how Cleanlab Studio works with text datasets and how to obtain/understand the results. You can map each Cleanlab result back to the corresponding document via the Document column.
Applications
One common application of Cleanlab Studio to documents is: curating a document collection to prepare for Retrieval-Augmented Generation – learn about this via our instructional video.
Other applications include:
- automated labeling/categorization/tagging of documents
- catching mis-categorized / mis-tagged documents / other bad document annotations
- catching near duplicate documents, outliers, as well as documents containing low-quality (poorly-written) text, foreign languages, or unsafe content (toxicity, PII, etc).
To learn how to accomplish these tasks, follow the analogous text data tutorials.
Other Document Types
Have documents of a file type not covered in the above list of supported file types?
You can either: convert your documents to a supported file type, extract the text from them yourself, or contact us if you want to run Cleanlab Studio directly on other types of documents.
If you are interested in building AI Assistants connected to your company’s data sources and other Retrieval-Augmented Generation applications, reach out to learn how Cleanlab can help.