Produce Better-Quality Data 10x Faster in any Data Annotation Platform You’re Using (e.g. Label Studio)

This tutorial shows how you can integrate Cleanlab Studio with any data annotation tool. Reduce how much data annotation work your team has to do (thanks to Cleanlab’s auto-labeling) and simultaneously produce better results (thanks to Cleanlab’s label error detection). The basic workflow looks as follows: first label some data with your tool, then use Cleanlab to catch any incorrectly selected labels and auto-label a large subset of the data that AI (Foundation models) can confidently label. You can then iterate these 2 steps multiple times. Each time you label (or re-label) a bit more data with your annotation tool, Cleanlab’s AI will learn from your new labels and become more effective for auto-labeling and label error detection. Since Cleanlab Studio is so easy to use, you can mostly focus on working with your annotation tool as you normally would – except now you’ll get datasets labeled more quickly and accurately.
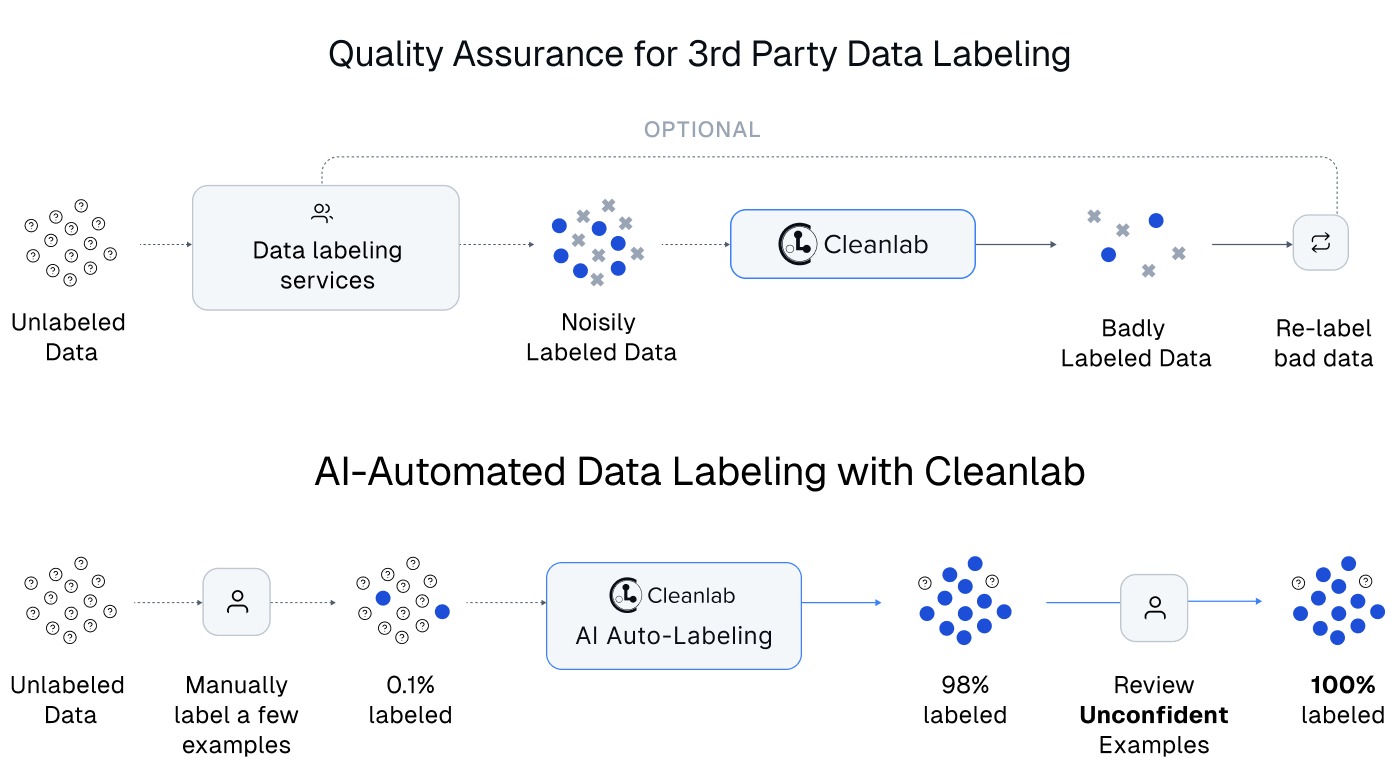
Here we’ll demonstrate this workflow with the Label Studio data annotation platform (one of the most popular tools that is freely open-source), but you can similarly integrate any data annotation tool of your choosing with Cleanlab Studio. For example, you could do the same workflows with annotation tools like LabelBox, LabelMe, or Coco among others. Some annotation platforms have built-in AI features, but none with the same powerful capabilities and ease-of-use as Cleanlab Studio.
This particular tutorial will focus on labeling image data for multi-class classification, but the same steps can be applied to text or tabular data being labeled for other types of tasks (e.g. tagging instead of multi-class classification). Here are the steps we’ll follow in this tutorial, starting with an entirely unlabeled dataset:
- Use your data annotation tool to label some of the data.
- Then load the currently labeled and unlabeled sets of this data into Cleanlab Studio.
- Use Cleanlab Studio to automatically find label errors (and other issues in the data) and send data flagged as likely incorrectly labeled back to your annotation tool for relabeling. Also use Cleanlab Studio to auto-label as much of the unlabeled data as can be confidently handled by Cleanlab’s AI.
- Iterate steps 1-3 until all of our data is labeled. Over time, there will be less unlabeled data remaining to label in later repetitions of step 1.
Install and import required dependencies
Note: this tutorial requires that you’ve created a Cleanlab Studio account.
You can use pip to install all packages required for this tutorial as follows:
pip install cleanlab-studio label-studio
When creating this tutorial, we used version 1.11.0 of the label-studio Python package.
from cleanlab_studio import Studio
from datasets import load_dataset
import pandas as pd
import requests
pd.set_option('display.max_colwidth', None)
Prepare the dataset
The dataset we’ll label is a sample of images of potato chips from PepsiCo - the original data can be found on Kaggle here.
Our task is to label each image from the dataset into one of 2 categories: Defective or Non-Defective.
Below are some images from the dataset. 2 Non-Defective potato chips are depicted in the top row and 2 Defective potato chips in the bottom row:

We have already stored the tutorial dataset with each image at an accessible URL. You could also produce such URLs for files in your cloud storage. Both Cleanlab Studio and Label Studio can operate directly on such linked external media files, or you run these tools on local files from your machine. Let’s fetch the files with the URLs pointing to the images that comprise our dataset:
wget -nc "https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/potato_chip_image_urls.csv"
Optionally, you can also download the full image dataset from here.
image_df = pd.read_csv("potato_chip_image_urls.csv")
image_urls = list(image_df["image"])
Next let’s define a DataFrame that will store our final labels for each image. This object will be updated throughout the tutorial.
This final labels DataFrame has an image column pointing to the URL of each image in our dataset. We initialize this DataFrame with a label column that is our goal to fill in for each image. We also include a column that will contain historical labels (represented as a list) for each image. Anytime a chosen label changes due to a label correction (when relabeling an image in the data annotation tool), the newly selected label will be appended to the list of historical labels that were selected by annotators of this image. Storing this set of previously selected labels is particularly useful when the data annotators are noisy.
final_labels_df = image_df.copy()
final_labels_df["label"] = [None] * len(image_urls)
final_labels_df["historical_labels"] = [[] for _ in range(len(image_urls))]
final_labels_df.head()
| image | label | historical_labels | |
|---|---|---|---|
| 0 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_014120.jpg | None | [] |
| 1 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_020053.jpg | None | [] |
| 2 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_005833.jpg | None | [] |
| 3 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_013704.jpg | None | [] |
| 4 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_015012.jpg | None | [] |
Label some of the images with your annotation tool
Note: You can skip this section if you already know how to use Label Studio or are using another data annotation tool.
Now let’s label a batch of the images using Label Studio, our example 3rd party annotation tool in this tutorial. Here we’ll use the Label Studio Python SDK to connect to the API.
Before executing the Python code below, first run label-studio in a command line interface of your choice. Don’t proceed until you have Label Studio running locally at: http://localhost:8080
from label_studio_sdk import Client
# Define the URL where Label Studio is accessible and the API key for your Label Studio user account, which you can find in your account settings
LABEL_STUDIO_URL = 'http://localhost:8080'
label_studio_api_key = "<insert API key here>"
# Connect to the Label Studio API and check the connection
ls = Client(url=LABEL_STUDIO_URL, api_key=label_studio_api_key)
ls.check_connection()
The status should be UP if everything’s working properly. Let’s create a project via our Label Studio Client Object for labeling our Potato Chip images.
project = ls.start_project(
title='Label Studio PepsiCo Image Tutorial Project',
label_config='''
<View>
<Image name="image" value="$image" valueType="url"/>
<Choices name="choice" toName="image">
<Choice value="Defective"/>
<Choice value="Non-Defective" />
</Choices>
</View>
'''
)
Format the data for Label Studio
Note: You can skip this section if you already know how to use Label Studio or are using another data annotation tool.
To programmatically import our images into Label Studio, we must format them like this:
[{'image': image_url1},
{'image': image_url2},
{'image': image_url3}
]
This is a list of dicts, where each dict has an image key and corresponding value image_url pointing to where the image is accessible.
Now let’s use a previously defined helper function to format our image URLs to the list of dicts that Label Studio will accept in its project.import_tasks function.
Optional: Define helper function to format the image URLs for Label Studio
from typing import List, Dict
def format_label_studio_image_urls(image_urls: List[str]) -> List[Dict[str, str]]:
"""
Converts a list of image URLs into the format that Label Studio accepts.
Parameters:
- image_urls (List[str]): A list of full URLs to the images that need to be labeled.
Returns:
- List[Dict[str, str]]: A list of dictionaries, where each dictionary contains a key 'image'
with its value being the full URL to an image file, ready for use in Label Studio.
"""
# Convert the list of URLs into the expected dictionary format for Label Studio
label_studio_urls = [{'image': url} for url in image_urls]
return label_studio_urls
image_urls_for_label_studio = format_label_studio_image_urls(image_urls)
print(len(image_urls_for_label_studio))
Let’s look at 3 example images we are importing into Label Studio:
# Check what some of the potato chip images look like
from IPython.display import HTML
images_html = "".join(
f'''<div style="text-align: center;"><img src="{url['image']}" width="400" alt="" /></div>'''
for url in image_urls_for_label_studio[:3]
)
# Display the images in the notebook
display(HTML(images_html))



Now we can import the images into Label Studio for labeling!
# Task IDs used in Label Studio to represent each image are the output we see printed below
imported_ids = project.import_tasks(image_urls_for_label_studio)
print(imported_ids[:5])
Learn how to import your data into Label Studio via this guide.
Label 50 images in Label Studio
Note: You can skip this section if you already know how to use Label Studio or are using another data annotation tool.
Go to your project in Label Studio and start labeling your imported images. Let’s just label 50 of those images to start. This guide shows how to label/annotate your data with Label Studio, but you could use any other data annotation platform.
Try to select a diverse set of initial examples to label that well represents all of the classes of interest (since Cleanlab’s AI will later learn from this initially labeled set).
Once you have labeled your images, one way to export the labels from Label Studio is via the Export button, as you can see in the video below or within your Label Studio session running locally. In this tutorial, we choose to export programmatically. This minimizes the amount of data you need to manually move between different tools in this tutorial. This also shows you how to interact with Label Studio using the Python API.
Here’s a video demonstrating how to label a some images in Label Studio after you have launched the app locally:
By default, Label Studio only exports tasks (i.e. data points in Label Studio) with annotations. For more details on exporting tasks, you can go here.
To be able to export all tasks programmatically, we use the following helper function.
Optional: Define helper function to export data from your Label Studio project
def export_data_from_label_studio_project(project_id: str, label_studio_api_key: str, output_file_path: str, export_type: str="CSV", server_url: str="http://localhost:8080"):
"""
Exports data from a specific project in Label Studio.
This function requests an export of data from a specified project in Label Studio, supporting
various export formats. The function handles the request and saves the exported data to a file
at the specified path.
Parameters:
- project_id (str): The ID of the project in Label Studio to export data from.
- label_studio_api_key (str): The API token for authenticating with the Label Studio server.
- output_file_path (str, optional): The path where the exported file should be saved.
- export_type (str, optional): The type of export format (e.g., CSV, JSON). Defaults to "CSV".
- server_url (str, optional): The URL of the Label Studio server. Defaults to "http://localhost:8080".
Returns:
- None: The function saves the exported data to a file and prints the outcome.
"""
url = f"{server_url}/api/projects/{project_id}/export?exportType={export_type}"
# Your authorization token
headers = {
"Authorization": f"Token {label_studio_api_key}"
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
# Save the exported data to a file
with open(output_file_path, "wb") as f:
f.write(response.content)
print("Data exported successfully.")
else:
print(f"Failed to export data. Status code: {response.status_code}, Message: {response.text}")
We also need to pass our Label Studio project ID and our API key into our helper function to be able to export our tasks.
This project ID can be found in the URL of your project after you have selected your project within Label Studio.
We also create a csv file to export our tasks into.
ls_project_id = 55 # REPLACE YOUR PROJECT ID HERE
export_filename = "label_studio_potato_chips_annotations.csv" # REPLACE YOUR FILENAME HERE
export_data_from_label_studio_project(ls_project_id, label_studio_api_key, export_filename)
Let’s see what our labeled data looks like so far.
label_studio_annotations = pd.read_csv(export_filename)
label_studio_annotations.head(10)
| annotation_id | annotator | choice | created_at | id | image | lead_time | updated_at | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1599 | 1 | Defective | 2024-03-21T21:40:46.231429Z | 161861 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_014120.jpg | 3.178 | 2024-03-21T21:40:46.231451Z |
| 1 | 1600 | 1 | Defective | 2024-03-21T21:40:48.406866Z | 161862 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_020053.jpg | 2.073 | 2024-03-21T21:40:48.406890Z |
| 2 | 1601 | 1 | Defective | 2024-03-21T21:40:50.714271Z | 161863 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_005833.jpg | 2.199 | 2024-03-21T21:40:50.714307Z |
| 3 | 1602 | 1 | Defective | 2024-03-21T21:40:52.918417Z | 161864 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_013704.jpg | 2.073 | 2024-03-21T21:40:52.918444Z |
| 4 | 1603 | 1 | Defective | 2024-03-21T21:40:55.034898Z | 161865 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_015012.jpg | 2.017 | 2024-03-21T21:40:55.034925Z |
| 5 | 1604 | 1 | Defective | 2024-03-21T21:40:57.286808Z | 161866 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_011506.jpg | 2.131 | 2024-03-21T21:40:57.286836Z |
| 6 | 1605 | 1 | Non-Defective | 2024-03-21T21:40:59.702141Z | 161867 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_002817.jpg | 2.298 | 2024-03-21T21:40:59.702167Z |
| 7 | 1606 | 1 | Non-Defective | 2024-03-21T21:41:02.890256Z | 161868 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_002553.jpg | 3.059 | 2024-03-21T21:41:02.890279Z |
| 8 | 1611 | 1 | Defective | 2024-03-21T22:13:55.609870Z | 161869 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_020243.jpg | 1972.597 | 2024-03-21T22:13:55.609890Z |
| 9 | 1612 | 1 | Defective | 2024-03-21T22:13:58.086707Z | 161870 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_014858.jpg | 2.342 | 2024-03-21T22:13:58.086738Z |
Update final labels DataFrame with labels obtained in our annotation tool
Note: You can skip this section if you already know how to use Label Studio or are using another data annotation tool.
Now we can fill in the official labels for 50 images that we just annotated in Label Studio so far.
# Here we define a helper function to update the values of our final labels based on annotations from Label Studio
def update_final_labels_via_labelstudio(final_labels_df, labels_df):
"""
Updates the 'label' column and appends labels to 'historical_labels' in final_labels_df
based on the 'image' column matching between final_labels_df and labels_df.
Parameters:
- final_labels_df (pd.DataFrame): The DataFrame to update, containing columns 'label',
'image', and 'historical_labels'.
- labels_df (pd.DataFrame): The DataFrame containing new labels from our annotation tool, with columns
including 'choice' and 'image'.
Returns:
- pd.DataFrame: The updated final_labels_df.
"""
for _, label_row in labels_df.iterrows():
image_url = label_row['image']
label_choice = label_row['choice']
# Find the index in final_labels_df where the image URL matches
index = final_labels_df.index[final_labels_df['image'] == image_url]
if not index.empty:
# Update the label column
final_labels_df.at[index[0], 'label'] = label_choice
# Check if the cell contains NaN or cannot be appended to directly
if len(final_labels_df.at[index[0], 'historical_labels']) == 0:
# Initialize with a list containing the label if NaN
final_labels_df.at[index[0], 'historical_labels'] = [label_choice]
else:
current_value = final_labels_df.at[index[0], 'historical_labels']
# Check if current_value is a list, implying we can append to it
if isinstance(current_value, list):
current_value.append(label_choice)
final_labels_df.at[index[0], 'historical_labels'] = current_value
else:
# Handle non-list, non-NaN values (e.g., initializing or converting to a list)
final_labels_df.at[index[0], 'historical_labels'] = [current_value, label_choice]
return final_labels_df
final_labels_df = update_final_labels_via_labelstudio(final_labels_df, label_studio_annotations)
final_labels_df[~final_labels_df["label"].isnull()]
| image | label | historical_labels | |
|---|---|---|---|
| 0 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_014120.jpg | Defective | [Defective] |
| 1 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_020053.jpg | Defective | [Defective] |
| 2 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_005833.jpg | Defective | [Defective] |
| 3 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_013704.jpg | Defective | [Defective] |
| 4 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_015012.jpg | Defective | [Defective] |
| 5 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_011506.jpg | Defective | [Defective] |
| 6 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_002817.jpg | Non-Defective | [Non-Defective] |
| 7 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_002553.jpg | Non-Defective | [Non-Defective] |
| 8 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_020243.jpg | Defective | [Defective] |
| 9 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_014858.jpg | Defective | [Defective] |
| 10 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210318_235659.jpg | Non-Defective | [Non-Defective] |
| 11 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_014520.jpg | Defective | [Defective] |
| 12 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_010752.jpg | Defective | [Defective] |
| 13 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_015937.jpg | Defective | [Defective] |
| 14 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_002905.jpg | Non-Defective | [Non-Defective] |
| 15 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_013808.jpg | Defective | [Defective] |
| 16 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210318_232231.jpg | Non-Defective | [Non-Defective] |
| 17 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_010521.jpg | Defective | [Defective] |
| 18 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_014223.jpg | Defective | [Defective] |
| 19 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_010858.jpg | Defective | [Defective] |
| 20 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_014353.jpg | Defective | [Defective] |
| 21 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_015648.jpg | Defective | [Defective] |
| 22 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_011017.jpg | Defective | [Defective] |
| 23 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_013341.jpg | Defective | [Defective] |
| 24 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_003754.jpg | Non-Defective | [Non-Defective] |
| 25 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_003026.jpg | Non-Defective | [Non-Defective] |
| 26 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_014639.jpg | Defective | [Defective] |
| 27 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_015451.jpg | Defective | [Defective] |
| 28 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_020004.jpg | Defective | [Defective] |
| 29 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_005727.jpg | Defective | [Defective] |
| 30 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_003342.jpg | Non-Defective | [Non-Defective] |
| 31 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_013435.jpg | Defective | [Defective] |
| 32 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_001756.jpg | Non-Defective | [Non-Defective] |
| 33 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_014824.jpg | Defective | [Defective] |
| 34 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_010315.jpg | Defective | [Defective] |
| 35 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_000106.jpg | Non-Defective | [Non-Defective] |
| 36 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_015545.jpg | Defective | [Defective] |
| 37 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_004702.jpg | Defective | [Defective] |
| 38 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_001519.jpg | Non-Defective | [Non-Defective] |
| 39 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_011522.jpg | Defective | [Defective] |
| 40 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210318_233144.jpg | Defective | [Defective] |
| 41 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_014117.jpg | Non-Defective | [Non-Defective] |
| 42 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_014842.jpg | Non-Defective | [Non-Defective] |
| 43 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_013912.jpg | Non-Defective | [Non-Defective] |
| 44 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_003322.jpg | Defective | [Defective] |
| 45 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_011524.jpg | Non-Defective | [Non-Defective] |
| 46 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_014306.jpg | Non-Defective | [Non-Defective] |
| 47 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_003531.jpg | Non-Defective | [Non-Defective] |
| 48 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_014529.jpg | Defective | [Defective] |
| 49 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210318_235645.jpg | Non-Defective | [Non-Defective] |
We’ve now recorded labels (and updated the historical labels) for 50 of our images, which were manually annotated. Cleanlab Studio can help us avoid having to manually annotate the rest of the dataset.
Use Cleanlab Studio to catch label errors and auto-label the data that AI can confidently handle
To run Cleanlab Studio, we first properly format our dataset (including both labeled and the rest of the unlabeled images). Here we use the Cleanlab External Image format, so there is no need to move your images (Cleanlab will read them directly from their public URLs). You can run Cleanlab Studio on data stored in a variety of alternate cloud/local storage formats.
We drop the historical_labels column from the final labels DataFrame prior to loading it into Cleanlab Studio, since it is not needed for us to use Cleanlab Studio to catch label errors and auto-label the images.
cleanlab_df = final_labels_df.drop("historical_labels", axis=1)
A quickstart tutorial for programmatically analyzing image datasets via Cleanlab Studio’s Python API is available here. If you prefer to use the web interface and interactively browse/correct your data, see our other tutorial: Finding Issues in Large-Scale Image Datasets. Here we run through the simple steps without much explanation.
# You can find your Cleanlab Studio API key by going to studio.cleanlab.ai/upload,
# clicking "Upload via Python API", and copying the API key there
API_KEY = "<insert API key here>"
# initialize studio object
studio = Studio(API_KEY)
Let’s load our set of currently labeled/unlabeled images into Cleanlab Studio. It’s important to provide your full dataset to get the best results from Cleanlab’s AI.
dataset_id = studio.upload_dataset(cleanlab_df, dataset_name="Pepsico_RnD_Potato_Chip_Image_Data_Tutorial", schema_overrides=[{"name": "image", "column_type": "image_external"}])
print(f"Dataset ID: {dataset_id}")
Once the data are loaded, we create a Project based on this Dataset in Cleanlab Studio.
project_id = studio.create_project(
dataset_id=dataset_id,
project_name="Pepsico_RnD_Potato_Chip_Image_Data_Tutorial_Project",
modality="image",
task_type="multi-class",
model_type="regular",
label_column="label",
)
print(
f"Project successfully created and ML training has begun! project_id: {project_id}"
)
The Project will take a while for Cleanlab’s AI models to train on your dataset and analyze it. You’ll receive an email when the results are ready. Each Project creates a cleanset (cleaned dataset). Run the cell below to fetch the cleanset_id from Cleanlab Studio, this code will block until your project results are ready. For big datasets, if your notebook times out, do not recreate the project. Instead just re-run the cell below to fetch the cleanset_id based on the project_id (which you can also find in the Cleanlab Studio Web App).
cleanset_id = studio.get_latest_cleanset_id(project_id)
print(f"cleanset_id: {cleanset_id}")
studio.wait_until_cleanset_ready(cleanset_id)
Cleanlab Studio automatically generates smart metadata for any image, text, or tabular dataset. This metadata (returned as Cleanlab Columns) helps you find and fix various problems in your dataset, or impute missing values and auto-label unlabeled data.
cleanlab_columns_df = studio.download_cleanlab_columns(cleanset_id)
cleanlab_columns_df.head(10)
| cleanlab_row_ID | corrected_label | is_label_issue | label_issue_score | suggested_label | suggested_label_confidence_score | is_ambiguous | ambiguous_score | is_well_labeled | is_near_duplicate | ... | is_odd_size | odd_size_score | is_low_information | low_information_score | is_grayscale | is_odd_aspect_ratio | odd_aspect_ratio_score | aesthetic_score | is_NSFW | NSFW_score | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | <NA> | False | 0.373451 | <NA> | 0.626549 | False | 0.993814 | False | False | ... | False | 0.0 | False | 0.305794 | False | False | 0.0 | 0.532279 | False | 0.041162 |
| 1 | 2 | <NA> | False | 0.425856 | <NA> | 0.574144 | False | 0.999999 | False | False | ... | False | 0.0 | False | 0.314794 | False | False | 0.0 | 0.511932 | False | 0.051039 |
| 2 | 3 | <NA> | False | 0.407524 | <NA> | 0.592476 | False | 0.999208 | False | False | ... | False | 0.0 | False | 0.278744 | False | False | 0.0 | 0.519195 | False | 0.113037 |
| 3 | 4 | <NA> | False | 0.391541 | <NA> | 0.608459 | False | 0.997314 | False | False | ... | False | 0.0 | False | 0.300383 | False | False | 0.0 | 0.479944 | False | 0.054440 |
| 4 | 5 | <NA> | False | 0.390192 | <NA> | 0.609808 | False | 0.997103 | False | False | ... | False | 0.0 | False | 0.330797 | False | False | 0.0 | 0.482801 | False | 0.052081 |
| 5 | 6 | <NA> | False | 0.392143 | <NA> | 0.607857 | False | 0.997406 | False | False | ... | False | 0.0 | False | 0.291288 | False | False | 0.0 | 0.464114 | False | 0.000000 |
| 6 | 7 | <NA> | False | 0.425907 | <NA> | 0.574093 | False | 0.951693 | False | False | ... | False | 0.0 | False | 0.348319 | False | False | 0.0 | 0.552842 | False | 0.137950 |
| 7 | 8 | <NA> | False | 0.420150 | <NA> | 0.579850 | False | 0.947803 | False | False | ... | False | 0.0 | False | 0.328956 | False | False | 0.0 | 0.584307 | False | 0.092091 |
| 8 | 9 | <NA> | False | 0.437139 | <NA> | 0.562861 | False | 0.999753 | False | False | ... | False | 0.0 | False | 0.310666 | False | False | 0.0 | 0.489662 | False | 0.108625 |
| 9 | 10 | <NA> | False | 0.375067 | <NA> | 0.624933 | False | 0.994185 | False | False | ... | False | 0.0 | False | 0.327839 | False | False | 0.0 | 0.525412 | False | 0.110453 |
10 rows × 33 columns
We’ll join our Cleanlab Studio metadata columns with some of our original data columns in order to view detected label issues, suggested labels, confidence in these suggestions, and other important columns that Cleanlab automatically generated. Learn more about these metadata columns here.
Label issues in image datasets often involve challenges such as incorrectly chosen class labels due to human mistakes, inconsistencies across different data annotators, ambiguous examples where multiple classes might seem applicable, and instances where relevant features are overlooked by annotators. Cleanlab can automatically detect annotation problems stemming from a variety of sources, including: subjective interpretation of images, the complexity of scenes, variability in object appearances, and unclear portions of annotation guidelines (or changing guidelines). Identifying and resolving these annotation issues is crucial for creating a high-quality dataset.
cleanlab_df = cleanlab_df.reset_index().rename(columns={'index': 'cleanlab_row_ID'})
cleanlab_columns_df = pd.merge(cleanlab_columns_df, cleanlab_df[['cleanlab_row_ID', 'label', 'image']], on='cleanlab_row_ID', how='left')
Review some of the mislabeled images that Cleanlab Studio detected
We have retrieved our Cleanlab Studio results, so how should we actually look at the results and use them effectively?
Let’s look at an example of a mislabeled image that Cleanlab was able to detect to build trust that Cleanlab can actually do this. We can filter our cleanlab_columns_df based on the column is_label_issue to find the images that are found to be label issues by Cleanlab.
We then sort (in descending order) these label issues by their label_issue_score, which quantifies how confident Cleanlab is that a data point is mislabeled.
We identify the images most confidently to be mislabeled by thresholding the label issue score.
label_issues = cleanlab_columns_df.query("is_label_issue").sort_values("label_issue_score", ascending=False)
Optional: Helper functions to render id column of DataFrame as images in a separate column
from PIL import Image
from io import BytesIO
from base64 import b64encode
from IPython.display import HTML
def url_to_img_html(url: str) -> str:
"""
Converts a URL to an HTML img tag.
"""
return f'<img src="{url}" width="175" alt="Image" />'
def display_images_in_df(df: pd.DataFrame) -> HTML:
"""
Modifies the DataFrame to include a column with HTML img tags for rendering images.
"""
image_column = "image_shown"
df_copy = df.copy()
# Assuming 'url_to_img_html' converts URLs in 'image' column to HTML img tags
df_copy[image_column] = df_copy['image'].apply(url_to_img_html)
# Determine the position of the 'image' column
image_col_index = df_copy.columns.get_loc('image') + 1
# Reorder columns to ensure 'image_shown' appears immediately after 'image'
columns = list(df_copy.columns)
new_column_order = columns[:image_col_index] + [image_column] + columns[image_col_index:-1]
df_copy = df_copy[new_column_order]
# Generate HTML representation of the DataFrame to display images
html = df_copy.to_html(escape=False)
return HTML(html)
To see that some of these images were actually mislabeled, you can view the first 2 images below in the image_shown column:
display_images_in_df(label_issues.head(2)[["cleanlab_row_ID", "image", "is_label_issue", "label_issue_score", "label", "suggested_label"]])
| cleanlab_row_ID | image | image_shown | is_label_issue | label_issue_score | label | suggested_label | |
|---|---|---|---|---|---|---|---|
| 42 | 43 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_013912.jpg |  |
True | 0.778596 | Non-Defective | Defective |
| 41 | 42 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_014842.jpg |  |
True | 0.708746 | Non-Defective | Defective |
Cleanlab has automatically flagged data that was badly annotated! Let’s use Cleanlab’s label issue detection to determine which data points should be re-labeled in our data annotation tool.
Based on some threshold value we set for our label_issue_score column, we should choose to flag and relabel (in our data annotation tool) any images that are greater than or equal to this threshold value.
Here we set our label_issue_score threshold to 0.7 (to only re-consider the images Cleanlab is most confident are mislabeled):
images_to_relabel_in_label_studio = cleanlab_columns_df.query(
"is_label_issue & label_issue_score > 0.7"
).sort_values("label_issue_score", ascending=False)
images_to_relabel_in_label_studio.head()
| cleanlab_row_ID | corrected_label | is_label_issue | label_issue_score | suggested_label | suggested_label_confidence_score | is_ambiguous | ambiguous_score | is_well_labeled | is_near_duplicate | ... | is_low_information | low_information_score | is_grayscale | is_odd_aspect_ratio | odd_aspect_ratio_score | aesthetic_score | is_NSFW | NSFW_score | label | image | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 42 | 43 | <NA> | True | 0.778596 | Defective | 0.778596 | False | 0.905642 | False | False | ... | False | 0.302884 | False | False | 0.0 | 0.5266 | False | 0.000000 | Non-Defective | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_013912.jpg |
| 41 | 42 | <NA> | True | 0.708746 | Defective | 0.708746 | False | 0.959486 | False | False | ... | False | 0.315274 | False | False | 0.0 | 0.5030 | False | 0.074041 | Non-Defective | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_014842.jpg |
2 rows × 35 columns
Note: The value you choose for score thresholds will affect subsequent results. We suggest you play around with this threshold to achieve optimal results for your data.
For label issues, you should choose a threshold where you see images that were mislabeled around this label_issue_score threshold.
Review some of the unlabeled images that we want to auto-label
Let’s look at a few examples of unlabeled images that we want to try and auto-label using Cleanlab Studio. Auto-labeling uses predictions from Cleanlab’s AI (which was trained on your existing labeled data provided in the Cleanlab Studio Project) to suggest labels for unlabeled data points. To ensure accurate auto-labels, we must account for the confidence in these predictions.
unlabeled_images = final_labels_df[final_labels_df['label'].isnull()]
unlabeled_images.head()
| image | label | historical_labels | |
|---|---|---|---|
| 50 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_Unlabeled/IMG_20210319_014652.jpg | None | [] |
| 51 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_Unlabeled/IMG_20210318_234146.jpg | None | [] |
| 52 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_Unlabeled/IMG_20210319_010408.jpg | None | [] |
| 53 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_Unlabeled/IMG_20210319_001713.jpg | None | [] |
| 54 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_Unlabeled/IMG_20210319_020124.jpg | None | [] |
Let’s look at some of these unlabeled images that we want to auto-label below. The image_shown column is to see what the images actually look like:
display_images_in_df(unlabeled_images.head(3)[["label", "historical_labels", "image"]])
| label | historical_labels | image | image_shown | |
|---|---|---|---|---|
| 50 | None | [] | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_Unlabeled/IMG_20210319_014652.jpg |  |
| 51 | None | [] | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_Unlabeled/IMG_20210318_234146.jpg |  |
| 52 | None | [] | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_Unlabeled/IMG_20210319_010408.jpg |  |
We can then sort (in descending order) these unlabeled images by their suggested_label_confidence_score in order to see which images are considered data points we can more confidently auto-label with Cleanlab.
The suggested_label_confidence_score is our confidence that Cleanlab’s predicted label for a data point is correct (again, higher values correspond to data points you can more confidently auto-fix / auto-label with Cleanlab). To read more about this score, you can go here.
Based on some threshold value we set for our suggested_label_confidence_score column, we should auto-label (using the suggested_label column) any images that are currently unlabeled and that are greater than or equal to this threshold value.
Here is an example of how to do this by setting our suggested_label_confidence_score threshold to 0.7(a high threshold to find images we are most confident about being able to auto-label):
auto_label_criteria = cleanlab_columns_df['suggested_label'].notnull() & \
(cleanlab_columns_df['suggested_label_confidence_score'] > 0.7) & \
cleanlab_columns_df['image'].isin(unlabeled_images['image'])
images_to_auto_label = cleanlab_columns_df[auto_label_criteria].sort_values("suggested_label_confidence_score", ascending=False)
images_to_auto_label.head()
| cleanlab_row_ID | corrected_label | is_label_issue | label_issue_score | suggested_label | suggested_label_confidence_score | is_ambiguous | ambiguous_score | is_well_labeled | is_near_duplicate | ... | is_low_information | low_information_score | is_grayscale | is_odd_aspect_ratio | odd_aspect_ratio_score | aesthetic_score | is_NSFW | NSFW_score | label | image | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 320 | 321 | <NA> | False | 0.0 | Defective | 0.745203 | False | NaN | False | False | ... | False | 0.284669 | False | False | 0.0 | 0.565557 | False | 0.000000 | None | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_Unlabeled/IMG_20210319_020059.jpg |
| 214 | 215 | <NA> | False | 0.0 | Defective | 0.736089 | False | NaN | False | False | ... | False | 0.291471 | False | False | 0.0 | 0.530241 | False | 0.000000 | None | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_Unlabeled/IMG_20210319_013358.jpg |
| 158 | 159 | <NA> | False | 0.0 | Defective | 0.732108 | False | NaN | False | False | ... | False | 0.316843 | False | False | 0.0 | 0.568669 | False | 0.004064 | None | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_Unlabeled/IMG_20210319_003158.jpg |
| 247 | 248 | <NA> | False | 0.0 | Defective | 0.729612 | False | NaN | False | False | ... | False | 0.307088 | False | False | 0.0 | 0.538092 | False | 0.000000 | None | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_Unlabeled/IMG_20210319_002930.jpg |
| 222 | 223 | <NA> | False | 0.0 | Defective | 0.728620 | False | NaN | False | False | ... | False | 0.294260 | False | False | 0.0 | 0.493728 | False | 0.000000 | None | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_Unlabeled/IMG_20210319_010310.jpg |
5 rows × 35 columns
Note: The value you choose for this threshold is sensitive in how it affects results and we highly suggest you tune or play around with this threshold yourself to achieve optimal results for your use case.
For deciding which auto-labels can be trusted, you should choose a threshold where you see the images with greater suggested_label_confidence_score have the correct suggested_label.
Update final labels DataFrame with our Cleanlab Studio results
Let’s now use our Cleanlab Studio results to achieve the following:
-
Based on some threshold value we set for Cleanlab’s
label_issue_scorecolumn, select data points to re-label in our data annotation tool. This efficiently fixes data that was likely previously mislabeled. -
Based on some threshold value we set for Cleanlab’s
suggested_label_confidence_scorecolumn, select currently-unlabeled data points to auto-label with Cleanlab (using thesuggested_labelcolumn). This allows to only auto-label the subset of data that AI can confidently handle. -
Update our final labels to reflect the newly auto-labeled images, determine the indices of data points that need to be relabeled in our data annotation tool, as well as indices of data points that were auto-labeled by Cleanlab.
Optional: Define helper function to update the values of our labels based on what we auto-label in Cleanlab Studio and determine which images to relabel
from typing import Tuple, Optional
def update_final_labels_via_cleanlab(
final_labels_df: pd.DataFrame,
cleanlab_columns_df: pd.DataFrame,
issue_score_threshold: float = 0.6,
suggested_label_confidence_score_threshold: float = 0.55,
run_auto_labeling_only: bool = False
) -> Tuple[pd.DataFrame, Optional[pd.DataFrame], Optional[pd.DataFrame]]:
"""
Updates final labels with suggested labels from cleanlab_columns_df based on specified criteria,
and identifies images to relabel in Label Studio.
Parameters:
- final_labels_df (pd.DataFrame): DataFrame to update, containing 'label', 'image', and 'historical_labels'.
- cleanlab_columns_df (pd.DataFrame): DataFrame containing cleanlab analysis and suggestions.
- issue_score_threshold (float): Threshold for determining if a label issue is significant enough to require relabeling.
- suggested_label_confidence_score_threshold (float): Confidence score threshold for auto-labeling.
- run_auto_labeling_only (bool): If True, only run the auto-labeling logic.
Returns:
- pd.DataFrame: Updated final labels.
- Optional[pd.DataFrame]: images_to_relabel_in_label_studio, containing images identified for relabeling (None if run_auto_labeling_only=True).
- pd.DataFrame: images_to_auto_label, containing images auto-labeled based on the suggested label confidence score.
"""
images_to_relabel_in_label_studio = None
if not run_auto_labeling_only:
# Part 1: Identify images to relabel in Label Studio
images_to_relabel_in_label_studio = cleanlab_columns_df.query(
"is_label_issue & label_issue_score > @issue_score_threshold"
).sort_values("label_issue_score", ascending=False)
# Filter out already labeled images in final_labels_df for auto-labeling
unlabeled_final_labels_df = final_labels_df[final_labels_df['label'].isnull()]
# Part 2: Auto-label images not in the images_to_relabel_in_label_studio DataFrame
# and meeting the suggested_label confidence score criteria
# Additionally, ensure these images are currently unlabeled in final_labels_df
auto_label_criteria = cleanlab_columns_df['suggested_label'].notnull() & \
(cleanlab_columns_df['suggested_label_confidence_score'] > suggested_label_confidence_score_threshold) & \
cleanlab_columns_df['image'].isin(unlabeled_final_labels_df['image'])
if not run_auto_labeling_only:
auto_label_criteria &= ~cleanlab_columns_df['image'].isin(images_to_relabel_in_label_studio['image'])
images_to_auto_label = cleanlab_columns_df[auto_label_criteria].sort_values("suggested_label_confidence_score", ascending=False)
# Update final_labels_df with auto-label suggestions
for _, row in images_to_auto_label.iterrows():
image_url = row['image']
suggested_label = row['suggested_label']
# Find the index in final_labels_df where the image URL matches
index = final_labels_df.index[final_labels_df['image'] == image_url]
if not index.empty:
# Update the label column
final_labels_df.at[index[0], 'label'] = suggested_label
# Append the suggested label to the historical_labels list
if len(final_labels_df.at[index[0], 'historical_labels']) == 0:
final_labels_df.at[index[0], 'historical_labels'] = [suggested_label]
else:
existing_labels = final_labels_df.at[index[0], 'historical_labels']
if isinstance(existing_labels, list):
existing_labels.append(suggested_label)
else:
final_labels_df.at[index[0], 'historical_labels'] = [existing_labels, suggested_label]
# Adjust the return based on `run_auto_labeling_only`
if run_auto_labeling_only:
return final_labels_df, None, images_to_auto_label
else:
return final_labels_df, images_to_relabel_in_label_studio, images_to_auto_label
Let’s update our final labels, obtain which images to relabel in Label Studio, and auto-label some of our unlabeled images using this helper function we just defined.
We choose lower thresholds for label_issue_score and suggested_label_confidence_score as the default values for these scores (as arguments to the helper function) compared to the examples we showed previously in order to make it easier to find images to relabel and auto-label for this tutorial.
# Obtain updated finals labels object, the images to relabel in Label Studio, and the images we auto-labeled
final_labels_df, images_to_relabel, auto_labeled_images = update_final_labels_via_cleanlab(final_labels_df, cleanlab_columns_df)
Let’s check how many images we auto labeled with Cleanlab Studio using our threshold on suggested_label_confidence_score:
# We auto-labeled these images
print(auto_labeled_images.shape)
Let’s also look at some examples of the images we auto-labeled to see if they were correct. We will see what our suggested_label is for 2 of the images we auto-labeled and the image_shown column to see what the images actually look like:
display_images_in_df(auto_labeled_images.head(2)[["cleanlab_row_ID", "image", "is_label_issue", "label_issue_score", "label", "suggested_label"]])
| cleanlab_row_ID | image | image_shown | is_label_issue | label_issue_score | label | suggested_label | |
|---|---|---|---|---|---|---|---|
| 320 | 321 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_Unlabeled/IMG_20210319_020059.jpg |  |
False | 0.0 | None | Defective |
| 214 | 215 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_Unlabeled/IMG_20210319_013358.jpg |  |
False | 0.0 | None | Defective |
You will find after checking each image that the suggested labels are correct! Let’s see how many unlabeled images remain in our data after the auto-labeling:
# We can see we still have unlabeled images that need to be handled in another round of labeling
print(final_labels_df["label"].isnull().sum())
And now let’s see how many images we identified that need to relabeled in Label Studio, our 3rd party data annotation tool of choice:
# We will relabel these images with Label Studio
print(images_to_relabel.shape)
images_to_relabel[["is_label_issue", "label_issue_score", "label", "suggested_label", "image"]].head(10)
| is_label_issue | label_issue_score | label | suggested_label | image | |
|---|---|---|---|---|---|
| 42 | True | 0.778596 | Non-Defective | Defective | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_013912.jpg |
| 41 | True | 0.708746 | Non-Defective | Defective | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_014842.jpg |
| 43 | True | 0.685009 | Defective | Defective | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_003322.jpg |
| 45 | True | 0.680246 | Non-Defective | Defective | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_014306.jpg |
You can see for each of those images that label does not match suggested_label that found by Cleanlab’s AI. Cleanlab is very useful for catching label errors like these!
Round 2: label more images (and re-label those with label errors) in your data annotation tool
Note: You can skip this section if you already know how to use Label Studio or are using another data annotation tool.
After getting back the initial Cleanlab Studio results, you can use them to inform your next round of data annotation. Here we’ll use the images_to_relabel DataFrame to figure out the exact task_ids (index of our images in Label Studio) to modify when relabeling these images in Label Studio. Here we’ll continue labeling data in the same Label Studio project, which means we need to update this project with the auto-labels obtained from Cleanlab (so annotators don’t label those images that were already auto-labeled). You could alternatively start a new Label Studio project with just the remaining still-to-be-labeled data.
For simplicity in this tutorial, our 2nd round of data labeling just focuses on addressing mislabeled images. In practice, you should also manually label more of the unlabeled data (that could not be confidently auto-labeled yet). Every time you re-label data or label new data in your data annotation tool, run a Cleanlab Studio project on the updated dataset and Cleanlab’s results will automatically improve.
Optional: Helper function designed to help identify the right task IDs (associated with an image) in Label Studio for relabeling
def identify_tasks_to_relabel(tasks, images_to_relabel_list):
"""
Identifies tasks to relabel based on image URLs.
Parameters:
- tasks (list): A list of task dictionaries.
- images_to_relabel_list (list): A list of image URLs to relabel.
Returns:
- dict: A dictionary of task IDs to relabel, mapped to their filenames.
"""
# Extract the basename (filename) from the task image paths
task_filenames = {task['id']: task['data']['image'].split('/')[-1] for task in tasks}
# Extract filenames from the images_to_relabel_list
image_relabel_filenames = [image.split('/')[-1] for image in images_to_relabel_list]
# Filter the task IDs based on whether their filenames are in the list of images to relabel
tasks_to_relabel = {}
for task_id, filename in task_filenames.items():
if filename in image_relabel_filenames:
tasks_to_relabel[task_id] = filename
return tasks_to_relabel
def identify_tasks_to_autolabel(tasks, image_to_label_mapping):
"""
Identifies tasks to auto-label based on image URLs and assigns the suggested label.
Parameters:
- tasks (list): A list of task dictionaries.
- image_to_label_mapping (dict): A dictionary mapping image filenames to suggested labels.
Returns:
- dict: A dictionary of task IDs mapped to their suggested labels.
"""
tasks_to_autolabel = {}
# Extract the basename (filename) from the task image paths
for task in tasks:
filename = task['data']['image'].split('/')[-1]
if filename in image_to_label_mapping:
# Map task ID to the suggested label
tasks_to_autolabel[task['id']] = image_to_label_mapping[filename]
return tasks_to_autolabel
Let’s get all of the tasks (i.e. data points in Label Studio) that we want to relabel.
# Get all tasks to find the ones you want to relabel
tasks = project.get_tasks()
image_relabel_list = list(images_to_relabel["image"])
tasks_to_relabel = identify_tasks_to_relabel(tasks, image_relabel_list)
print("Task IDs to relabel:", tasks_to_relabel)
Let’s create a dict that maps our image filenames to the suggested labels that we are going to use to annotate our images in Label Studio and add a flag that they were auto-labeled.
# Convert DataFrame to dictionary mapping image filenames to suggested labels
image_to_label_mapping = dict(zip(auto_labeled_images['image'].apply(lambda x: x.split('/')[-1]), auto_labeled_images['suggested_label']))
# Assuming `tasks` is your list of task dictionaries
tasks_we_autolabeled = identify_tasks_to_autolabel(tasks, image_to_label_mapping)
The task_ids are formatted as a dictionary where each key is a task_id that maps to the filename of an image we want to relabel.
We have now found which task_ids to relabel and which we know we have auto-labeled, so we will remove our label (called an annotation in Label Studio) for these images associated with the relevant task_ids identified above. Then we will also mark (using a metadata column) which images need to be relabeled so that this is clearly visible in the Label Studio UI. We also will mark which images we have already auto-labeled in Label Studio so that one is not confused by which images still need to be labeled or not and which ones we have already auto-labeled with Cleanlab Studio.
You can use the code below to execute these steps and send the updates back to your Label Studio project that is running locally.
Optional: Helper functions that list annotations for a given task and clear/mark annotations for relabeling in Label Studio
from typing import Any
def fetch_annotation_metadata(api_key: str, task_id: int) -> List[Dict[str, Any]]:
"""
Fetches annotation metadata for a specific task from Label Studio.
Parameters:
- api_key (str): The API key for Label Studio.
- task_id (int): The ID of the task for which annotations are fetched.
Returns:
- List[Dict[str, Any]]: A list of annotations for the specified task.
Raises:
- Exception: If the request to the Label Studio API fails.
"""
headers = {'Authorization': f'Token {api_key}'}
response = requests.get(f'http://localhost:8080/api/tasks/{task_id}/annotations/', headers=headers)
if response.status_code == 200:
return response.json()
else:
raise Exception(f"Failed to fetch annotations. Status code: {response.status_code}, Response: {response.text}")
def clear_annotations_mark_for_relabeling_and_autolabel(api_key: str, tasks_to_relabel: Dict[int, str], auto_labeled_tasks: Dict[int, str]) -> None:
"""
Clears annotations for specified tasks, marks them for relabeling, and annotates auto-labeled tasks.
Parameters:
- api_key (str): The API key for Label Studio.
- tasks_to_relabel (Dict[int, str]): Tasks to be cleared and marked for relabeling.
- auto_labeled_tasks (Dict[int, str]): Task IDs mapped to their suggested label for auto-labeling.
Returns:
- None
Raises:
- Exception: If requests to the Label Studio API for deleting annotations, updating tasks, or creating annotations fail.
"""
for task_id in tasks_to_relabel.keys():
# List all annotations for the task using the custom function
annotations = fetch_annotation_metadata(api_key, task_id)
# Delete each annotation
for annotation in annotations:
response = requests.delete(f'http://localhost:8080/api/annotations/{annotation["id"]}/', headers={'Authorization': f'Token {api_key}'})
if response.status_code != 204:
raise Exception(f"Failed to delete annotation. Status code: {response.status_code}, Response: {response.text}")
# Fetch the task data
task_response = requests.get(f'http://localhost:8080/api/tasks/{task_id}/', headers={'Authorization': f'Token {api_key}'})
if task_response.status_code != 200:
raise Exception(f"Failed to fetch task. Status code: {task_response.status_code}, Response: {task_response.text}")
task_data = task_response.json()['data']
# Update the task to indicate it needs relabeling
if task_data.get('metadata') is None:
task_data['metadata'] = {}
task_data['metadata']['needs_relabeling'] = True
# Update the task with the modified data
update_response = requests.patch(f'http://localhost:8080/api/tasks/{task_id}/', json={'data': task_data}, headers={'Authorization': f'Token {api_key}'})
if update_response.status_code != 200:
raise Exception(f"Failed to update task. Status code: {update_response.status_code}, Response: {update_response.text}")
print("Annotations cleared and tasks marked for relabeling in Label Studio.")
# Handling auto-labeled tasks
for task_id, suggested_label in auto_labeled_tasks.items():
# Fetch the task data for updating metadata
task_response = requests.get(f'http://localhost:8080/api/tasks/{task_id}/', headers={'Authorization': f'Token {api_key}'})
if task_response.status_code != 200:
raise Exception(f"Failed to fetch task. Status code: {task_response.status_code}, Response: {task_response.text}")
task_data = task_response.json()['data']
# Update task metadata to indicate auto-labeled
if task_data.get('metadata') is None:
task_data['metadata'] = {}
task_data['metadata']['auto_labeled'] = True
# Update the task with the modified data including auto-labeled flag
update_response = requests.patch(f'http://localhost:8080/api/tasks/{task_id}/', json={'data': task_data}, headers={'Authorization': f'Token {api_key}'})
if update_response.status_code != 200:
raise Exception(f"Failed to update task. Status code: {update_response.status_code}, Response: {update_response.text}")
# Correct API endpoint for creating annotations
annotation_endpoint = f'http://localhost:8080/api/tasks/{task_id}/annotations/'
# Prepare annotation data
annotation_data = {
'result': [{
'from_name': 'label',
'to_name': 'image',
'type': 'choices',
'value': {'choices': [suggested_label]}
}]
}
# Attempt to create the annotation
annotation_response = requests.post(annotation_endpoint, json=annotation_data, headers={'Authorization': f'Token {api_key}'})
if annotation_response.status_code not in [200, 201]:
raise Exception(f"Failed to create annotation. Status code: {annotation_response.status_code}, Response: {annotation_response.text}")
print("Tasks that were auto-labeled were successfully annotated in Label Studio.")
We can look at specific annotation metadata for each task_id using the Label Studio API. This can help understand important details about the annotation, including when it was created, last updated, what the project id number is and more.
Here is an example of how to list the annotation metadata for a specific task_id in Label Studio using a helper function we defined:
example_task_id = list(tasks_to_relabel.keys())[0]
print(fetch_annotation_metadata(label_studio_api_key, example_task_id))
Clear annotations for images and mark them for relabeling in Label Studio
Note: You can skip this section if you already know how to use Label Studio or are using another data annotation tool.
Let’s use a helper function to clear the existing annotation in Label Studio for the images (each corresponding to a task in Label Studio) we know we want to relabel.
We also flag these images with a metadata column value to help you find the images that you manually need to relabel. If you had significantly more images to label than those in this tutorial, this flag would help you find the subset of images you are trying to relabel more easily.
You could also obtain the exact task_ids of the images and manually find each image to relabel without clearing the annotations in an automated way, but that would be a more difficult and time consuming method of relabeling your data in Label Studio.
We also flag the images that we’ve already auto-labeled, as mentioned earlier, with a metadata column value to more easily help you see which images do not need to be labeled within Label Studio due to Cleanlab Studio already helping us label those images.
For more information on deleting annotations in Label Studio, you can go here.
clear_annotations_mark_for_relabeling_and_autolabel(label_studio_api_key, tasks_to_relabel, tasks_we_autolabeled)
Now you can go to your Label Studio project to now relabel the images that we flagged.
In your Label Studio project, you’ll see that the images that need to be relabeled have a value in the metadata column of your project that says {"needs_relabeling":true}. The images we have already auto-labeled have a value in the metadata column that says “
Here is a video showing you how to find the images that need to be relabeled and also which images we have already auto-labeled. Then we show how to actually relabel the specified images within Label Studio:
After relabeling, export the labels as seen below.
Update final labels DataFrame with our 2nd round of labels obtained via Label Studio
Note: You can skip this section if you already know how to use Label Studio or are using another data annotation tool.
After relabeling some images in Label Studio, we update the DataFrame serving as our master record of each image’s final label.
We’ll reuse our Label Studio project ID defined earlier and our previously defined helper function to export the new image labels from Label Studio into a csv file:
relabeled_export_filename = "relabeled_label_studio_potato_chips_annotations.csv" # REPLACE YOUR FILENAME HERE
export_data_from_label_studio_project(ls_project_id, label_studio_api_key, relabeled_export_filename)
Let’s read in our image data we just exported out of Label Studio and filter out the images we did not relabel.
# Read in relabeled data exported from Label Studio
relabeled_df = pd.read_csv(relabeled_export_filename)
relabeled_df = relabeled_df[relabeled_df["metadata"] == '{"needs_relabeling":true}']
Here are the images that we relabeled:
relabeled_df.head(10)
| annotation_id | annotator | choice | created_at | id | image | lead_time | metadata | updated_at | |
|---|---|---|---|---|---|---|---|---|---|
| 42 | 2307 | 1 | Defective | 2024-03-22T13:40:20.268734Z | 161903 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_014842.jpg | 2.569 | {"needs_relabeling":true} | 2024-03-22T13:40:20.268757Z |
| 43 | 2308 | 1 | Defective | 2024-03-22T13:40:24.147650Z | 161904 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_013912.jpg | 2.230 | {"needs_relabeling":true} | 2024-03-22T13:40:24.147698Z |
| 44 | 2309 | 1 | Non-Defective | 2024-03-22T13:40:27.828297Z | 161905 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_003322.jpg | 2.220 | {"needs_relabeling":true} | 2024-03-22T13:40:27.828330Z |
| 46 | 2310 | 1 | Defective | 2024-03-22T13:40:31.009574Z | 161907 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_014306.jpg | 1.953 | {"needs_relabeling":true} | 2024-03-22T13:40:31.009615Z |
You can confirm the metadata column values show we did in fact relabel this data. The choice column represents what our now correct label value is after relabeling.
Let’s proceed with updating our final labels with our newly relabeled data. We will look at our final labels before AND after we update the values using our relabeled Label Studio images to illustrate the difference.
# Final labels before we update them with newly relabeled images
final_labels_df.loc[relabeled_df.index]
| image | label | historical_labels | |
|---|---|---|---|
| 42 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_014842.jpg | Non-Defective | [Non-Defective] |
| 43 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_013912.jpg | Non-Defective | [Non-Defective] |
| 44 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_003322.jpg | Defective | [Defective] |
| 46 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_014306.jpg | Non-Defective | [Non-Defective] |
# Apply updated labels from Label Studio to final labels
final_labels_df = update_final_labels_via_labelstudio(final_labels_df, relabeled_df)
# Final labels after we update them with newly relabeled images
final_labels_df.loc[relabeled_df.index]
| image | label | historical_labels | |
|---|---|---|---|
| 42 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_014842.jpg | Defective | [Non-Defective, Defective] |
| 43 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_013912.jpg | Defective | [Non-Defective, Defective] |
| 44 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_003322.jpg | Non-Defective | [Defective, Non-Defective] |
| 46 | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_To_Label/IMG_20210319_014306.jpg | Defective | [Non-Defective, Defective] |
You can see that we have new labels for several images that originally were Non-Defective (which was incorrect) and are now (correctly) Defective. Similarly, we correct images that were supposed to be Non-Defective and were not.
The historical_labels column is also correctly updated for these images. The label that is at the end of this historical_labels list is considered the most up-to-date label we are using for the image in the data point. The labels in this list, for each data point, are sorted by least recent label to most recent label of our image in that row.
We will update our metadata column in Label Studio to remove the flag that images need to be relabeled. You can run the following code to do this:
Optional: Helper function to update the relabeling status of all relabeled images
def update_tasks_relabeling_status(api_key: str, task_ids: List[int], needs_relabeling: bool) -> None:
"""
Updates the relabeling status of multiple tasks in Label Studio.
Parameters:
- api_key (str): The API key for Label Studio.
- task_ids (List[int]): A list of task IDs to update.
- needs_relabeling (bool): True to mark the tasks as needing relabeling, False to clear the mark.
Raises:
- Exception: If any request to update a task fails.
"""
headers = {'Authorization': f'Token {api_key}'}
for task_id in task_ids:
task_response = requests.get(f'http://localhost:8080/api/tasks/{task_id}/', headers=headers)
if task_response.status_code != 200:
raise Exception(f"Failed to fetch task {task_id}. Status code: {task_response.status_code}, Response: {task_response.text}")
task_data = task_response.json()['data']
if 'metadata' not in task_data or task_data['metadata'] is None:
task_data['metadata'] = {}
if needs_relabeling:
task_data['metadata']['needs_relabeling'] = True
else:
# Remove the needs_relabeling key if it exists
task_data['metadata'].pop('needs_relabeling', None)
# If the metadata dictionary is empty, set it to None
if not task_data['metadata']:
task_data['metadata'] = None
update_response = requests.patch(f'http://localhost:8080/api/tasks/{task_id}/', json={'data': task_data}, headers=headers)
if update_response.status_code != 200:
raise Exception(f"Failed to update task {task_id}. Status code: {update_response.status_code}, Response: {update_response.text}")
print(f"All tasks relabeling status updated successfully.")
# Remove metadata flag from Label Studio that images need to be relabeled.
relabeled_task_ids = list(tasks_to_relabel.keys())
update_tasks_relabeling_status(label_studio_api_key, relabeled_task_ids, needs_relabeling=False)
Now you can check your project in Label Studio to make sure no images there still have the needs_relabeling flag set to True. Without doing this step, it will be confusing to know which images you already relabeled and which images you did not relabel. This can otherwise be complex to manage for big datasets.
Note: For brevity, we did not annotate any more unlabeled data points in Label Studio during this 2nd round of labeling in this tutorial. In practice, you should also manually label some more of the unlabeled data in this 2nd round using your data annotation platform (to help Cleanlab’s AI learn not only from label corrections but new labels as well).
Round 2: Use Cleanlab Studio for further auto-labeling and label error detection
We will now follow the same process to first properly format our dataset (including both labeled and the rest of the unlabeled images) to ingest the newest version of our data back into Cleanlab Studio.
And we will create both a new Cleanlab Studio dataset and project that will be used to auto-label our remaining unlabeled images in our final labels.
In this tutorial, we choose to only auto-label the remainder of our data points given the size of the sample being used. In practice, you can try to repeat the process to detect data points that you want to re-label with your data annotation tool AND use Cleanlab to auto-label more unlabeled data points as many times as you deem necessary to achieve optimal results for your use case. Each time you label more data / correct existing labels and then launch a Cleanlab Studio project, Cleanlab’s AI will get better at auto-labeling your data and detecting label errors.
Let’s create our DataFrame object to ingest into Cleanlab Studio:
new_cleanlab_df = final_labels_df.drop("historical_labels", axis=1)
Let’s load our new set of currently labeled/unlabeled images into Cleanlab Studio. As mentioned earlier, it’s important to provide your full dataset to get the best results from Cleanlab’s AI.
new_dataset_id = studio.upload_dataset(new_cleanlab_df, dataset_name="Round_2_Pepsico_RnD_Potato_Chip_Image_Data_Tutorial", schema_overrides=[{"name": "image", "column_type": "image_external"}])
print(f"Dataset ID: {new_dataset_id}")
Once the new data are loaded, we create a new Project based on this Dataset in Cleanlab Studio.
new_project_id = studio.create_project(
dataset_id=new_dataset_id,
project_name="Round_2_Pepsico_RnD_Potato_Chip_Image_Data_Tutorial_Project",
modality="image",
task_type="multi-class",
model_type="regular",
label_column="label",
)
print(
f"Project successfully created and ML training has begun! project_id: {new_project_id}"
)
Note: the Project will take a while for Cleanlab’s AI models to train on your dataset and analyze it. You’ll receive an email when the results are ready. Run the cell below to fetch the cleanset_id from Cleanlab Studio, this code will block until your project results are ready. For big datasets, if your notebook times out, do not recreate the project. Instead just re-run the cell below to fetch the cleanset_id based on the project_id (which you can also find in the Cleanlab Studio Web App).
new_cleanset_id = studio.get_latest_cleanset_id(new_project_id)
print(f"cleanset_id: {new_cleanset_id}")
studio.wait_until_cleanset_ready(new_cleanset_id)
Let’s now download the metadata columns from Cleanlab Studio as we did before and see what the columns look like:
new_cleanlab_columns_df = studio.download_cleanlab_columns(new_cleanset_id)
new_cleanlab_columns_df.head(10)
| cleanlab_row_ID | corrected_label | is_label_issue | label_issue_score | suggested_label | suggested_label_confidence_score | is_ambiguous | ambiguous_score | is_well_labeled | is_near_duplicate | ... | is_odd_size | odd_size_score | is_low_information | low_information_score | is_grayscale | is_odd_aspect_ratio | odd_aspect_ratio_score | aesthetic_score | is_NSFW | NSFW_score | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | <NA> | False | 0.147065 | <NA> | 0.852935 | False | 0.997672 | False | False | ... | False | 0.0 | False | 0.305794 | False | False | 0.0 | 0.532279 | False | 0.041162 |
| 1 | 2 | <NA> | False | 0.194291 | <NA> | 0.805709 | False | 0.999998 | False | False | ... | False | 0.0 | False | 0.314794 | False | False | 0.0 | 0.511932 | False | 0.051039 |
| 2 | 3 | <NA> | False | 0.144631 | <NA> | 0.855369 | False | 0.997418 | False | False | ... | False | 0.0 | False | 0.278744 | False | False | 0.0 | 0.519195 | False | 0.113037 |
| 3 | 4 | <NA> | False | 0.166404 | <NA> | 0.833596 | False | 0.999222 | False | False | ... | False | 0.0 | False | 0.300383 | False | False | 0.0 | 0.479944 | False | 0.054440 |
| 4 | 5 | <NA> | False | 0.144390 | <NA> | 0.855610 | False | 0.997392 | False | False | ... | False | 0.0 | False | 0.330797 | False | False | 0.0 | 0.482801 | False | 0.052081 |
| 5 | 6 | <NA> | False | 0.161320 | <NA> | 0.838680 | False | 0.998895 | False | False | ... | False | 0.0 | False | 0.291288 | False | False | 0.0 | 0.464114 | False | 0.000000 |
| 6 | 7 | <NA> | True | 0.844409 | Defective | 0.844409 | False | 0.998458 | False | False | ... | False | 0.0 | False | 0.348319 | False | False | 0.0 | 0.552842 | False | 0.137950 |
| 7 | 8 | <NA> | False | 0.793626 | Defective | 0.793626 | True | 0.999799 | False | False | ... | False | 0.0 | False | 0.328956 | False | False | 0.0 | 0.584307 | False | 0.092091 |
| 8 | 9 | <NA> | False | 0.297036 | <NA> | 0.702964 | False | 0.987958 | False | False | ... | False | 0.0 | False | 0.310666 | False | False | 0.0 | 0.489662 | False | 0.108625 |
| 9 | 10 | <NA> | False | 0.123683 | <NA> | 0.876317 | False | 0.994688 | False | False | ... | False | 0.0 | False | 0.327839 | False | False | 0.0 | 0.525412 | False | 0.110453 |
10 rows × 33 columns
Let’s repeat the process of joining our Cleanlab Studio metadata columns with some of our original data columns in order to more easily observe the important columns that Cleanlab Studio generated for us.
new_cleanlab_df = new_cleanlab_df.reset_index().rename(columns={'index': 'cleanlab_row_ID'})
new_cleanlab_columns_df = new_cleanlab_columns_df.merge(new_cleanlab_df[['cleanlab_row_ID', 'label', 'image']], left_index=True, right_index=True)
Update final labels DataFrame with our 2nd round of Cleanlab Studio results
With our new Cleanlab Studio results we can now auto-label the remainder of our unlabeled data points and update our final labels object accordingly.
As mentioned before, based on some threshold value we set for our suggested_label_confidence_score column, we should auto-label (using the suggested_label column) any images that are currently unlabeled and that are greater than or equal to this threshold value.
In this round, we we only execute the auto-labeling logic in our helper function and not the label error detection logic (to find data points to re-label). In practice, you should repeat both of these steps as many times as you need to accurately label your dataset. In between each Cleanlab Studio project, you should aim to manually label a bit more unlabeled data in your data annotation tool (this will improve Cleanlab’s AI in the subsequent rounds). To keep this tutorial short, we won’t show many rounds of this process, and here only focus on auto-labeling in this 2nd round.
We’ll also choose a slightly lower (less conservative) threshold value for suggested_label_confidence_score when using our helper function this time around. This illustrates how you can choose different threshold values in different rounds of the labeling process as Cleanlab’s AI improves over multiple rounds.
# Obtain updated final labels and newly auto-labeled images
final_labels_df, _, new_auto_labeled_images = update_final_labels_via_cleanlab(final_labels_df, new_cleanlab_columns_df, suggested_label_confidence_score_threshold=0.5, run_auto_labeling_only=True)
We’ve updated our final labels and auto-labeled the unlabeled data points that could be confidently handled by Cleanlab’s AI. Let’s see how many unlabeled data points we were able to auto-label:
print(new_auto_labeled_images.shape)
The number of data points we auto-labeled matches the number of unlabeled data points remaining from the previous round of labeling! Cleanlab’s AI improved so much from our 2nd round of manual annotations that it was able to auto-label all of the remaining unlabeled data.
Let’s inspect some images we auto-labeled in this round to review if they were correct. We will see what our suggested_label is for 2 of the images we auto-labeled and the image_shown column to see what the images actually look like:
display_images_in_df(new_auto_labeled_images.head(2)[["is_initially_unlabeled", "image", "label", "suggested_label"]])
| is_initially_unlabeled | image | image_shown | label | suggested_label | |
|---|---|---|---|---|---|
| 102 | True | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_Unlabeled/IMG_20210319_004902.jpg |  |
None | Defective |
| 394 | True | https://s.cleanlab.ai/PepsiCo-Potato-Chip-Images/Label_Studio_Tutorial_Potato_Chip_Images_Unlabeled/IMG_20210319_013246.jpg |  |
None | Defective |
The suggested_label values confidently predicted by Cleanlab’s AI are correct for these examples!
Here’s how many unlabeled data points remain after this round of auto-labeling:
print(final_labels_df["label"].isnull().sum())
We do not have any unlabeled images left, so we have successfully used a 3rd party data annotation tool combined with Cleanlab Studio to label all of our data points! Otherwise you could manually label some more images with your data annotation platform (in a 3rd round), and then run another Cleanlab Studio Project to further improve the auto-labeling of your data.
Summary
This tutorial demonstrated how easily Cleanlab Studio can be used with any 3rd party data annotation tool. By incorporating Cleanlab Studio into our workflow, we only had to manually label 50 data points (plus the 6 relabeled points) in our data annotation tool instead of all 400 data points. The other 350 data points we were able to accurately auto-label using Cleanlab Studio, which is ~88% of our images, saving time and effort. Cleanlab Studio can scale to massive datasets just as easily, unlocking immense savings.
Cleanlab also automatically caught incorrect labels, allowing us to produce a higher-quality dataset.
While we focused on image data here, all of this works for text and tabular datasets as well. The same workflow can also be applied in other data annotation applications beyond multi-class classification, such as image/document tagging. We re-emphasize that you can apply this same workflow with any data annotation tool of your choosing (see beginning of tutorial for links to other tools beyond Label Studio).