Models
A Model is a machine learning model automatically trained and optimized for your dataset. Cleanlab Studio identifies the most appropriate model to detect issues in your dataset. After cleaning up the issues detected in your dataset, you can use your improved cleanset to re-train a highly accurate and robust version of the model (with a single click).
Deploy a Model
You can use your trained model for making predictions on new data (model inference). To get started, click the Deploy Model button at the bottom of your project and enter a model name. This will automatically identify and train the best type of ML model on the cleanset (i.e. current version of your dataset with all of your latest corrections applied).
Training make take a while – once it completes the status wheel will change to a View model button (you will also receive an email so you don’t have to actively monitor this). After that, you can inspect the model’s performance (prediction accuracy estimated via cross-validation) and get predictions for new data.
Below we show an example of model deployment with a multi-class classification dataset. Model deployment is also available for multi-label classification, and the steps involved are identical to the process shown below.
Using a Model to Make Predictions
To make predictions directly in the web interface:
- Select
View Model. - Select
Predict New Labelsin the upper right hand corner. - Upload your CSV with new data and select
Predict New Labels - Once the status says “Ready for export”, select
Exportto download your predictions.
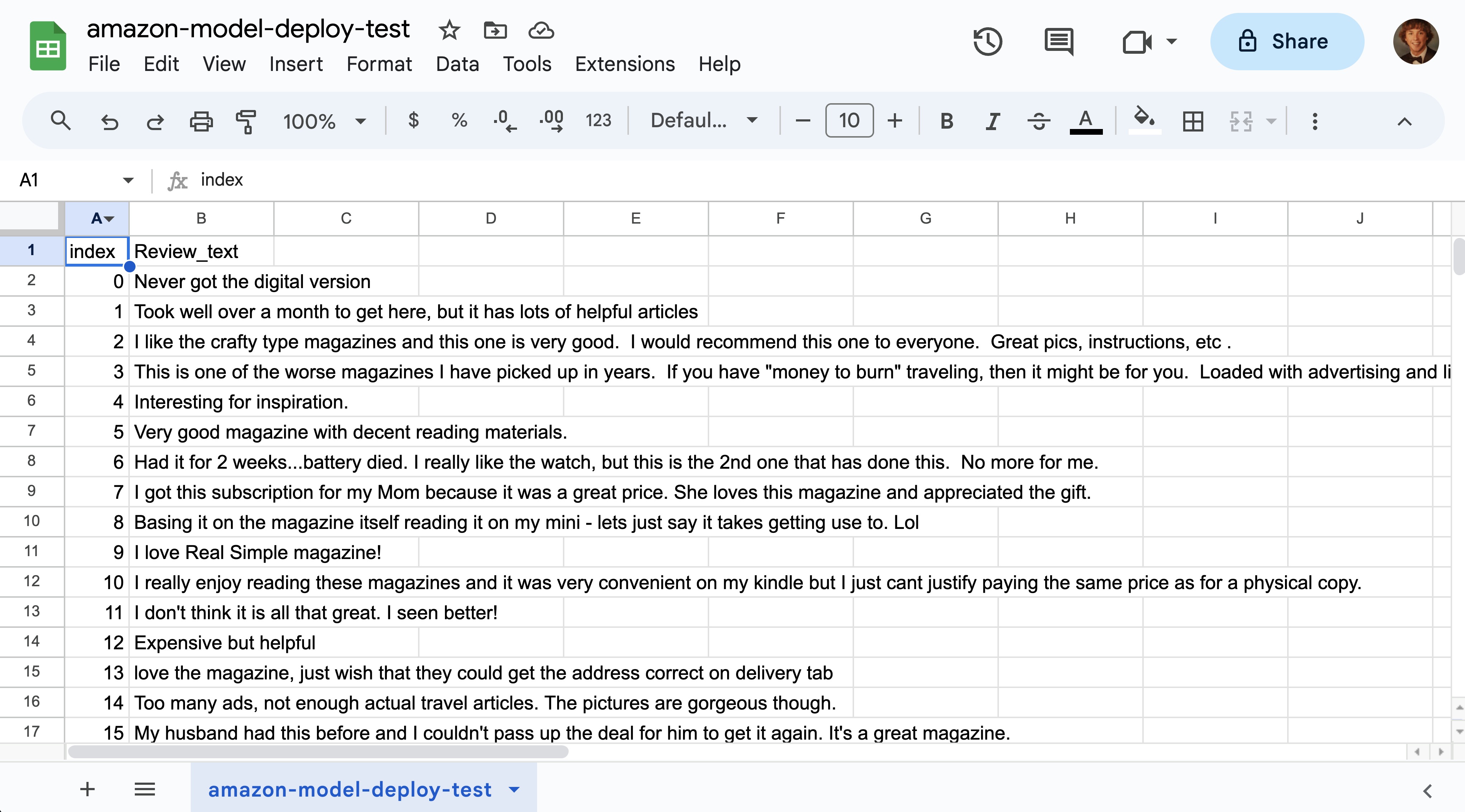
IMPORTANT: The column name(s) in the file used for predictions must match the column name(s) of the target variable(s) in your original dataset used for the project. In this example, the target (text) column is named Review_text which is also the column name in the CSV uploaded for predictions (below).
Alternatively learn how to make predictions via Python API in our tutorial: Deploying Reliable Models in Production.
Inference Results
Selecting the Inference Results tab (at the top of the web interface) shows all of the datasets you have produced predictions for using this model. Here you can can Export or Delete each set of predictions.
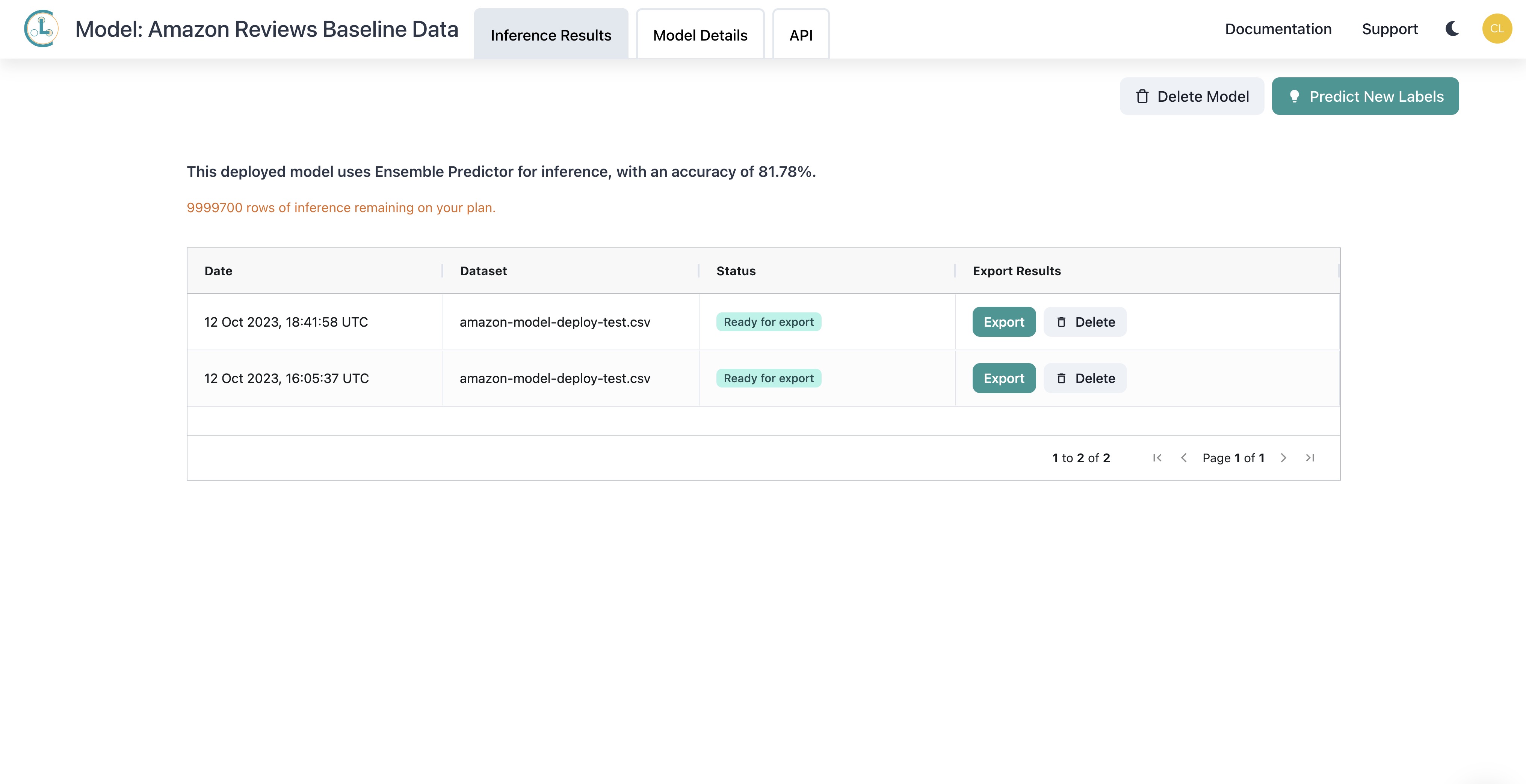
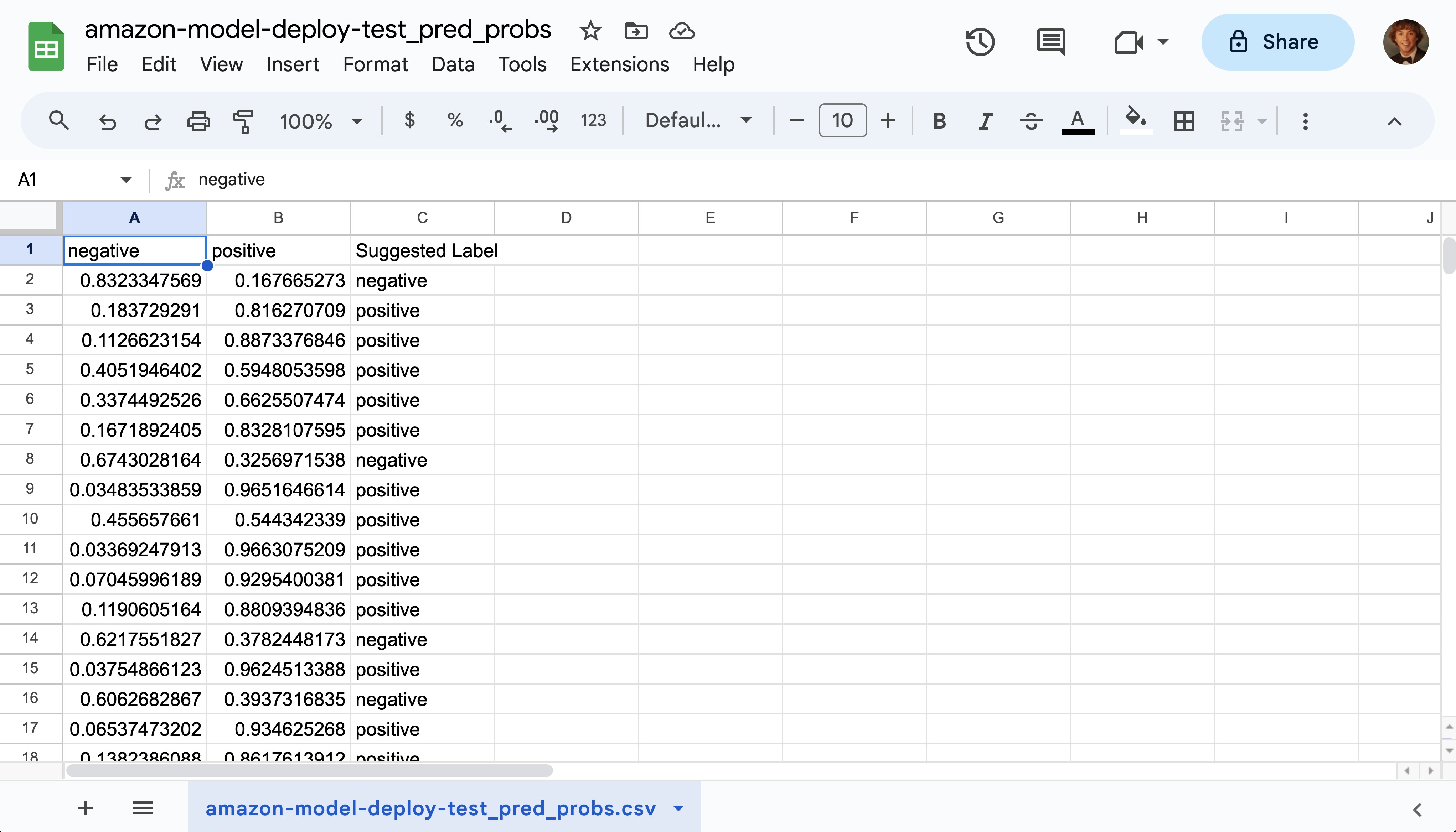
For example, below is a CSV file of exported predictions opened in Google Sheets. In this particular export, each row corresponds to the respective example found in the uploaded amazon-model-deploy-test.csv data file. The possible classes that the model can predict are listed as column headers (negative and positive for this example dataset) with the corresponding predicted probability of each class listed in the rows. This file also lists the Suggested Label which is the predicted class for each row (i.e. the class with the highest predicted probability).
For multi-label classification, the output also has columns representing the predicted probabilities of each label, along with a Suggested Label column. In the case of multi-label classification, the probability for each label represents the likelihood of that label being present, so the sum of probabilities in one row may exceed $1$ if multiple labels are present for that data point. The Suggested Label consists of the predicted labels for each data point, which will be returned as a comma-separated string, e.g. “wearing_hat,has_glasses” (with no whitespaces).
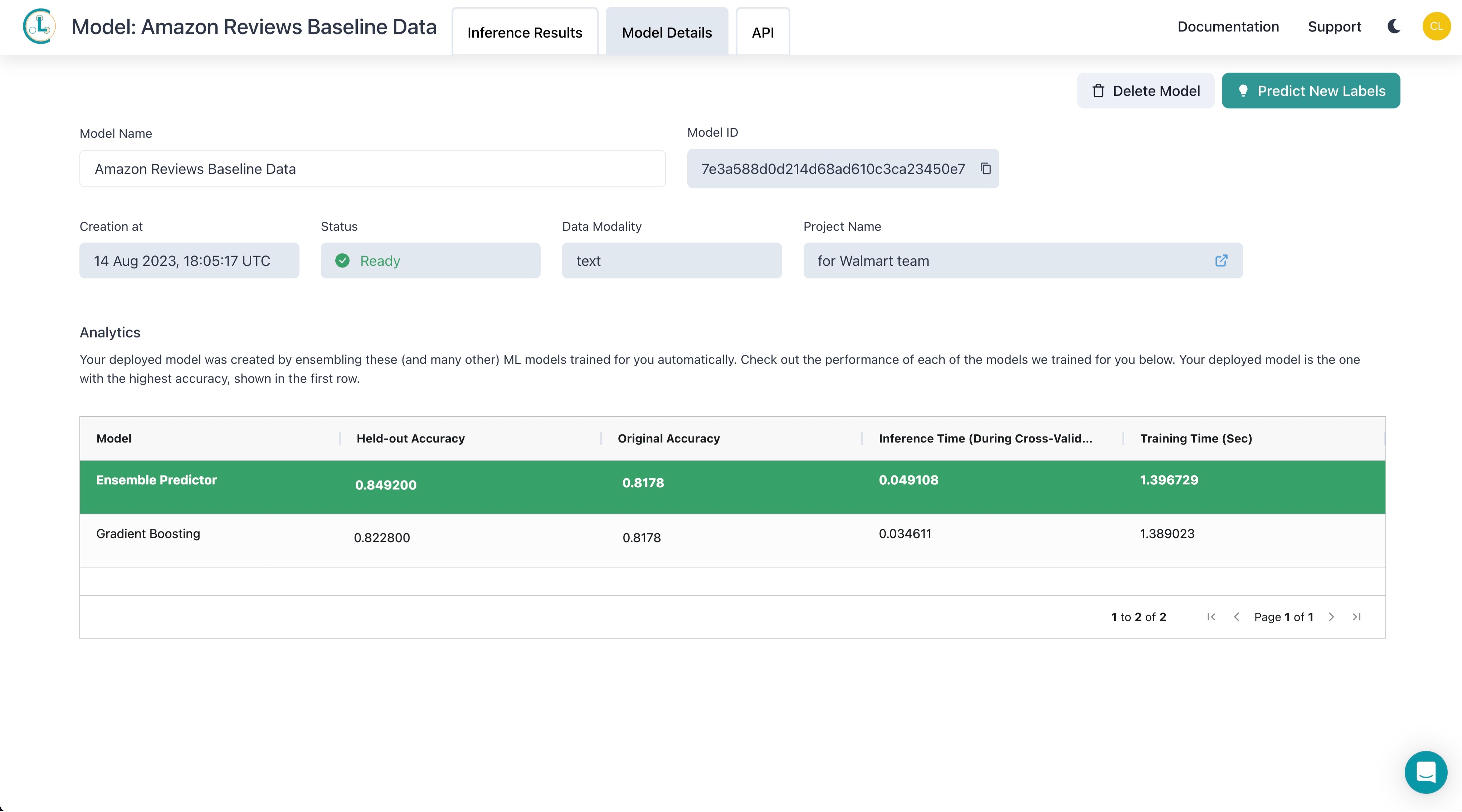
Model Details
Selecting the Model Details tab at the top displays information about the Model. Your deployed model was automatically created by training and ensembling the listed types of ML models. Your deployed model is the one with the highest accuracy, shown in the first row.
Here you can see these statistics:
- Model: Type of ML model trained (Ensemble Predictor corresponds to a combination of the other models listed below).
- Held-out Accuracy: Accuracy of the deployed model, trained on your improved cleanset
- Original Accuracy: Accuracy of the model trained on your original unmodified dataset, estimated via cross-validation.
- Inference Time: Time it took (in seconds) to complete cross-validated inference for this model.
- Training Time: Time it took (in seconds) to complete model training for this model.