Datasets
A Dataset corresponds to your original text/image/tabular data.
Cleanlab Studio can analyze and train/deploy models on diverse types of datasets. This page outlines how to format your data and the available options. Refer to our tutorials for specific examples. If you are unsure about anything, just ask: support@cleanlab.ai
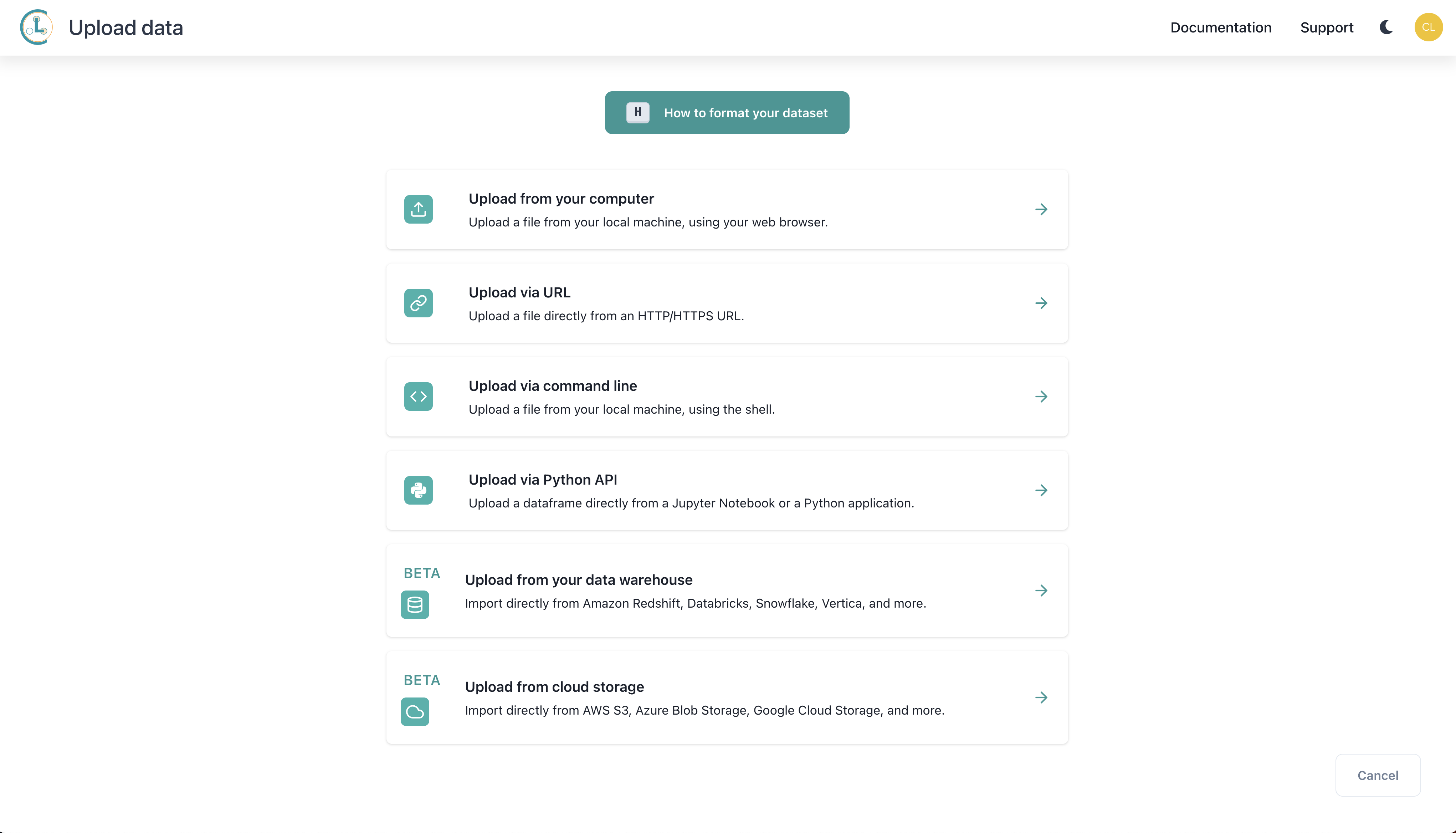
Modalities
Cleanlab Studio supports datasets of the following modalities:
- Tabular (structured data stored in tables with numeric/categorical/string columns, e.g. financial information, sensor measurements, customer records)
- Text (e.g. documents, customer requests, descriptions, LLM outputs)
- Image (e.g. photographs, product images, satellite imagery)
Text/Tabular
Text/tabular datasets are structured datasets composed of rows and columns, with each row representing an individual data point. Text/tabular datasets can be loaded in multiple formats, including CSV, JSON, Excel, and DataFrame.
Cleanlab’s analysis of text datasets focuses on a single text field for each data point (i.e. row), while Cleanlab can consider many columns of tabular datasets. Internally, Cleanlab’s AutoML system will predict a provided label column based on the single text field for a text datset, or based on all columns designated as predictive features for a tabular dataset. For more information on how to use text/tabular datasets, see our tabular and text quickstart tutorials.
Document Datasets
Cleanlab Studio also supports loading a text dataset as a heterogeneous collection of document files. Cleanlab Studio supports many document file types, including: csv, doc, docx, pdf, ppt, pptx, xls, xlsx. Your dataset can simultaneously contain many of these file types, it does not need to be homogeneous.
Document datasets can be loaded in multiple formats. If your document files are stored locally, you can use a ZIP format. If your document files are hosted (on an Internet-accessible web server or storage platform, like S3 or Google Drive), you can load your dataset by including links to your external documents via an external document column in a CSV, JSON, Excel, or DataFrame dataset.
Cleanlab automatically extracts the text from your documents into a column named text when you load your dataset. From there, you can subsequently work with it as a standard text dataset. Cleanlab’s results can be mapped back to the original documents via the column that specifies the file name (relative path) of each document.
Important: When loading a document dataset, ensure you do not have a column named text in either your metadata file (for Metadata ZIP formatted data) or your dataset file (for externally hosted document formatted data).
Image
Image datasets are datasets composed of rows of images with attached metadata (including but not limited to labels). Image datasets can be loaded in multiple formats. If your image files are stored locally, you can use one of the ZIP formats. If your image files are hosted (on an Internet-accessible web server or storage platform, like S3 or Google Drive), you can load your dataset by including links to your external images via an external image column in a CSV, JSON, Excel, or DataFrame dataset.
For more information on how to use image datasets, see our [image quickstart tutorial]tutorials/image_data_quickstart).
Machine Learning Task
Although you do not need to select a machine learning task type when loading data into Cleanlab Studio, different tasks require different data formatting. To make sure you don’t have problems creating Projects or producing the best results, you should first investigate the different task types and format your dataset accordingly. For more information on ML task types, see our [projects guide]guide/concepts/projects/#machine-learning-task–dataset-type).
Multi-class
In a multi-class classification task, the objective is to categorize data points into one of K distinct classes, e.g. classifying animals as one of “cat”, “dog”, “bird”.
To format your dataset for multi-class classification, ensure your dataset includes a column containing the class each row belongs to and follow the appropriate structure for your modality and file format.
Unlabeled data
To include unlabeled rows (i.e. rows without annotations) in your multi-class dataset, simply leave their values in the label column empty/blank.
Multi-label
In a multi-label classification task, each data point can belong to multiple (or no) classes, e.g. assigning non-disjoint tags to news articles.
For multi-label classification, your dataset’s label column should be formatted as a comma-separated string of classes, e.g. “politics,economics” (there should be no whitespace between labels). Note: for image datasets, you must use the Metadata or External Media formats.
Unlabeled data vs. Empty labels
For multi-label datasets, there’s an important distinction between unlabeled rows and rows with empty labels. Unlabeled rows are data points where the label(s) are unknown. You can use Cleanlab Studio to determine whether these rows belong to any of your dataset’s classes. Rows with empty labels are data points that have no labels – they have been annotated to indicate that they don’t belong to any of your dataset’s classes.
When loading a CSV or Excel dataset, any empty values in your label column will be interpreted as unlabeled rows rather than rows with empty labels. To distinguish between the two in your dataset, you must use JSON file format or DataFrame format.
You can represent these two types of data points in the JSON file format using the following values:
- empty labels:
""(empty string) - unlabeled:
null
You can represent these two types of data points in a DataFrame dataset using the following values:
- empty labels:
""(empty string) - unlabeled:
None,pd.NA
Note: If you only have empty labels (but no unlabeled data) you still need to provide the file in JSON format and set the labels to "". Empty string labels in CSV or Excel format will be interpreted as unlabeled.
Regression
In a regression task, the objective is to label each data point with a continuous numerical value, e.g. price, income, or age, rather than a discrete category.
To format your dataset for regression, ensure your dataset includes a label column containing the continuous numeric value you’d like to predict and follow the appropriate structure for your modality and file format. Note: you’ll need to set the column type for your label column to float before creating a regression project. See the Schema Updates section for information on how to do this.
Unlabeled data
To include unlabeled rows (i.e. rows without annotations) in your regression dataset, simply leave their values in the label column empty/blank.
See our regression tutorial for an example of using Cleanlab Studio for a regression task.
Unsupervised
For an unsupervised task, there is no target variable to predict for data points. This task type might be appropriate for your data if there is no clear “label column”. Follow the appropriate structure for your modality and file format.
See our unsupervised tutorial for an example of using Cleanlab Studio for an unsupervised task.
File Formats
Cleanlab Studio natively supports datasets in CSV, JSON, Excel, or ZIP file formats. In addition, the Python API supports data stored in Pandas, PySpark, and Snowpark DataFrames (for Databricks and Snowflake users). We also offer tutorials to convert other text and image Python data formats into one of Cleanlab’s natively supported formats (Huggingface, Tensorflow, Torchvision, Scikit-learn, …).
CSV
CSV is a standard file format for storing text/tabular data, where each row represents a data record and consists of one or more fields (columns) separated by a delimiter.
Make sure your CSV dataset follows these formatting requirements:
- Each row is represented by a single line of text with fields separated by a
,delimiter. - String values containing the delimiter character (
,) or special characters (e.g. newline characters) should be enclosed within double quotes (” “). - The first row should be a header containing the names of all columns in the dataset.
- Empty fields are represented by consecutive delimiter characters with no value in between or empty double quotes (
""). - Each row should contain the same number of columns, with missing values represented as empty fields.
- Each row should be separated by a newline.
Unlabeled data.
You can indicate if a data point is not yet annotated/labeled by leaving its value in the label column empty. Note: for multi-label tasks, if you need data points with empty labels, you must use the JSON file format.
Example CSV text dataset
review_id,review,label
f3ac,The sales rep was fantastic!,positive
d7c4,He was a bit wishy-washy.,negative
439a,They kept using the word "obviously," which was off-putting.,positive
a53f,,negative
JSON
JSON is a standard file format for storing and exchanging structured data organized using key-value pairs. In a JSON dataset, each row is represented by an object where keys correspond to column names.
Your JSON dataset should follow these formatting requirements:
- Each row is represented as a JSON object consisting of key-value pairs (separated by colons
:) enclosed in curly braces{}. Each key is a string (enclosed in double quotes" ") that uniquely identifies the value associated with it. - The rows of your dataset are enclosed in a JSON array (square brackets
[]) and separated by commas,. - Valid types for values in your dataset include strings, numbers, booleans, and null values.
- Your dataset cannot contain nested array or object values. Ensure these are flattened.
- Every key is present in every row of your dataset.
Unlabeled data
If you’re formatting a dataset for a multi-class or regression task, you can indicate if a data point is not yet annotated/labeled using a "" or null value.
For multi-label tasks, you must use null values to indicate data points that are not yet annotated/labeled. This allows us to distinguish between data points where no class applies (indicated by "") and data points that are not yet annotated (see here for more information on the difference between these).
Example JSON multi-label text dataset
In this example dataset each data point is a text review. The first data point f3ac is a data point with an empty label (has been annotated as belonging to none of the classes), while the last review a53f is an unlabeled data point (that has not yet been annotated). Note the difference between their label values to distinguish these cases.
[
{
"review_id": "f3ac",
"review": "The message was sent yesterday.",
"label": ""
},
{
"review_id": "d7c4",
"review": "He was a bit rude to the staff.",
"label": "negative,rude,mean"
},
{
"review_id": "439a",
"review": "They provided a wonderful experience that made us very happy.",
"label": "positive,happy,joy"
},
{
"review_id": "a53f",
"review": "Please let her know I appreciated the hospitality.",
"label": null
}
]
Excel
Excel is a popular file format for spreadsheets. Cleanlab Studio supports both .xls and .xlsx files.
Your Excel dataset should follow these formatting requirements:
- Only the first sheet of your spreadsheet will be imported as your dataset.
- The first row of your sheet should contain names for all of the columns.
Unlabeled data
You can indicate if a data point is not yet annotated/labeled by leaving its value in the label column empty. Note: for multi-label tasks, if you need data points with empty labels, you must use the JSON file format.
Example Excel text dataset
| _ | review_id | review | label |
|---|---|---|---|
| 0 | f3ac | The sales rep was fantastic! | positive |
| 1 | d7c4 | He was a bit wishy-washy. | negative |
| 2 | 439a | They kept using the word “obviously,” which wa… | positive |
| 3 | a53f | negative |
DataFrame
Cleanlab Studio’s Python API supports a number of DataFrame formats, including Pandas, PySpark DataFrames, and Snowpark DataFrames. You can load data directly from a DataFrame in a Python script or Jupyter notebook.
See our Databricks integration and Snowflake integration for more details on loading data from PySpark and Snowpark DataFrames.
Unlabeled data
If you’re formatting a dataset for a multi-class or regression task, you can indicate if a data point is not yet annotated/labeled using a "", None, or pd.NA value (or the equivalent null value for PySpark/Snowpark).
For multi-label tasks, you must use None or pd.NA values to indicate data points that are not yet annotated/labeled. This allows us to distinguish between data points where no class applies (indicated by "") and data points that are not yet annotated (see here for more information on the difference between these).
Example DataFrame text dataset
| _ | review_id | review | label |
|---|---|---|---|
| 0 | f3ac | The sales rep was fantastic! | positive |
| 1 | d7c4 | He was a bit wishy-washy. | negative |
| 2 | 439a | They kept using the word “obviously,” which wa… | positive |
| 3 | a53f | negative |
ZIP
ZIP files are commonly used for storing and transferring multiple files/directories as a single compressed file. You can run Cleanlab Studio on a dataset with image OR document files by including them all within one ZIP file. Supported ways to organize your ZIP file are outlined below.
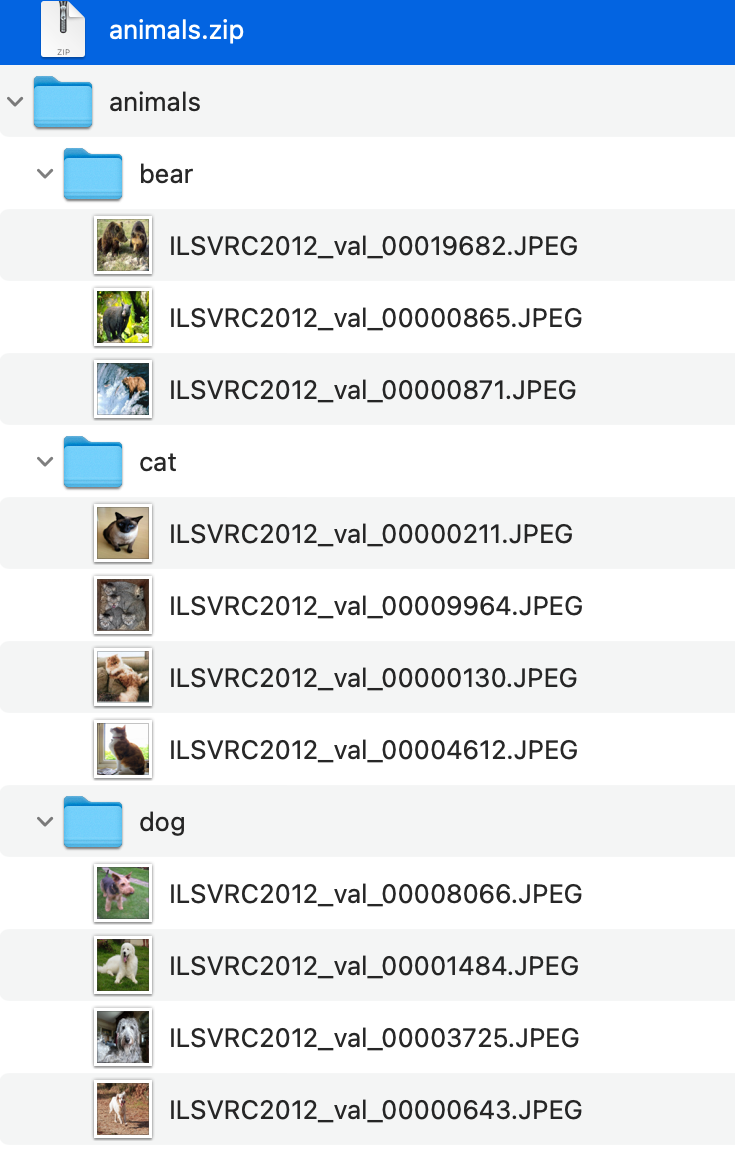
Simple ZIP
Note: Simple ZIP format is only supported for multi-class datasets.
To format a simple ZIP dataset:
- Create a top-level folder for your dataset.
- Inside the top-level folder, create a folder for each class in your dataset. The name of each folder will be used as the class label for images or documents within the folder.
- Inside each class folder, add image/document files belonging to the class.
- ZIP the top-level folder.
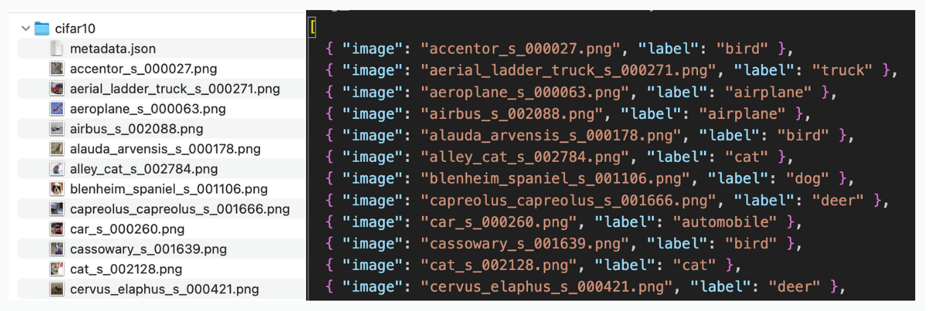
Metadata ZIP
If you are loading an image/document dataset for a multi-label, regression, or unsupervised task or would like to include metadata associated with examples (i.e. rows) in your dataset, you can include either a metadata.csv or metadata.json file in your ZIP dataset.
To format your dataset as a ZIP with metadata:
- Create a top-level folder for your dataset.
- Add image/document files for your dataset to the folder. These files can optionally be organized within subfolders.
- Add a
metadata.csvormetadata.jsonfile inside your top-level folder. - ZIP the top-level folder.
Your metadata file (metadata.csv or metadata.json) should follow these formatting requirements:
- The file should contain a column named
image(if loading an image dataset) ordocument(if loading a document dataset). The values in this column should correspond to the relative paths to images/documents from yourmetadata.csvormetadata.jsonfile. Do not include another column with this special name in your metadata. - If loading a dataset for a multi-class, multi-label, or regression task, the file should include a column for the labels corresponding to each image/document (some entries of this column may be missing if there are unlabeled examples in your dataset). Do not rely on file paths in the
imageordocumentcolumn to specify how your data is labeled, that must be encoded in a separate label column ofmetadata.csvormetadata.json. - The file can optionally include other columns with additional metadata about each data point that you would like to view or filter by in Cleanlab Studio (these columns will not be considered by Cleanlab’s AutoML system and thus will not directly affect Project results).
- See the CSV and JSON file format sections for more details on each file type.
Note: If your dataset contains any unlabeled data, you must use the metadata ZIP format rather than the simple ZIP format. Ensure that in the metadata.csv file, your image or documents that are unlabeled have empty values in the label column (e.g. empty string: "").
Schemas
Schemas define the type of each column in your dataset. This allows Cleanlab Studio to understand the structure of your data and provide the best possible analysis and model training experience.
Cleanlab Studio supports the following column types:
| Column Type | Sub-types | Override Name |
|---|---|---|
| Untyped | - | untyped |
| Integer | - | integer |
| Float | - | float |
| Boolean | - | boolean |
| String | - | string |
| Image | - | - |
| External Image | - | image_external |
| Document | - | - |
| External Document | - | document_external |
| Date | Seconds (epoch) Milliseconds (epoch) Microseconds (epoch) Nanoseconds (epoch) Parse | date_epoch_sdate_epoch_msdate_epoch_usdate_epoch_nsdate_parse |
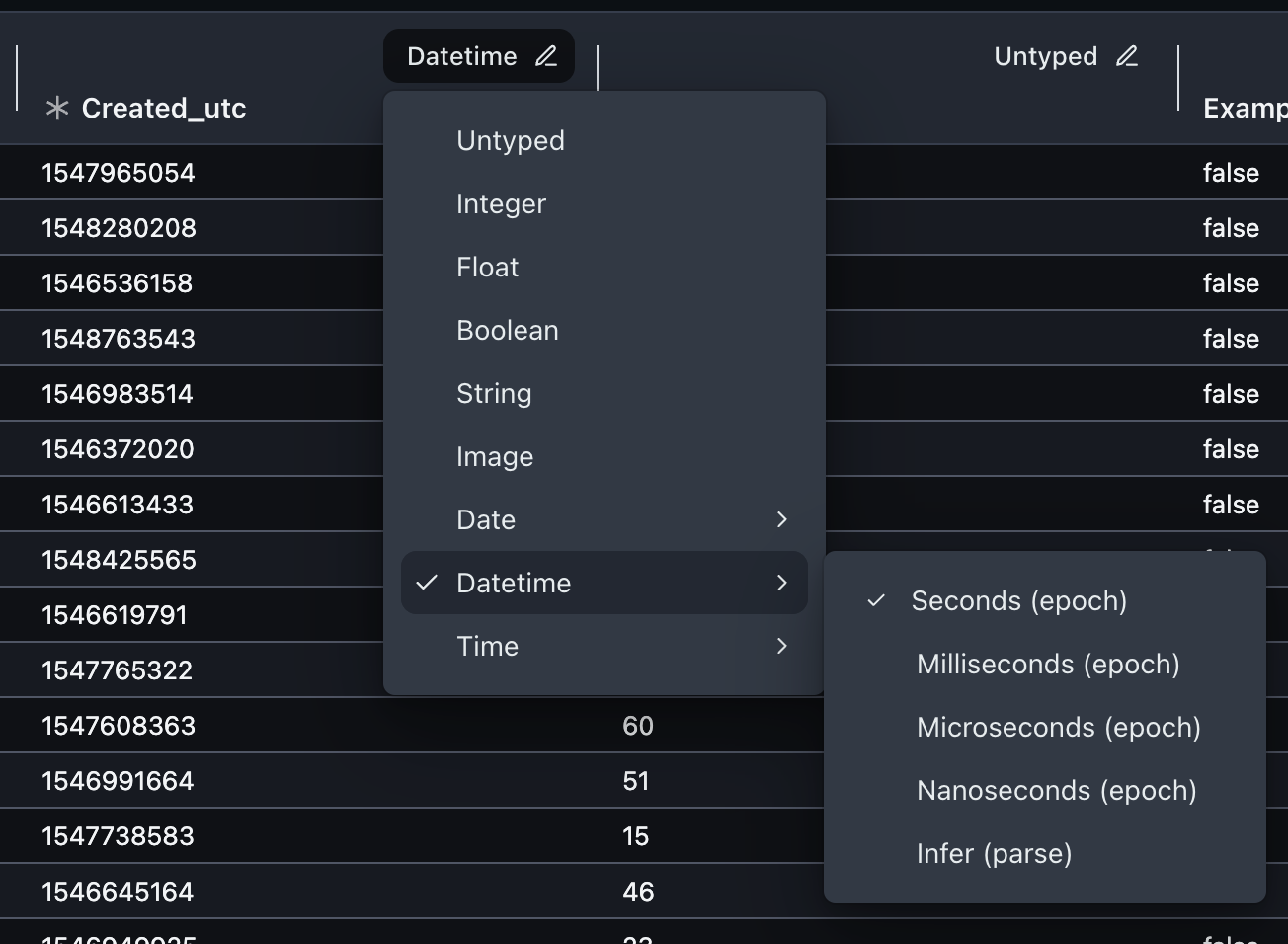
| Datetime | Seconds (epoch) Milliseconds (epoch) Microseconds (epoch) Nanoseconds (epoch) Parse | datetime_epoch_sdatetime_epoch_msdatetime_epoch_usdatetime_epoch_nsdatetime_parse |
| Time | Seconds (epoch) Milliseconds (epoch) Microseconds (epoch) Nanoseconds (epoch) Parse | time_epoch_stime_epoch_mstime_epoch_ustime_epoch_nstime_parse |
By default, Cleanlab Studio sets all columns to Untyped, which will defer data type inference internally to Cleanlab’s AutoML system.
If you want to enforce the type of certain columns, this can be overridden by:
- In the Web Application, updating the dataset schema after loading your dataset
- In the Python API, providing the
schema_overridesargument when loading your dataset
See Schema Updates section for more information.
Column Types
Untyped
This is the default type for columns in Cleanlab Studio. It is used when the type of a column is not specified.
Columns with type Untyped are interpreted as text.
Integer
Columns with type Integer are interpreted as 64-bit integer numbers.
Float
Columns with type Float are interpreted as 64-bit floating point numbers.
Boolean
Columns with type Boolean are interpreted as boolean values.
The following values are interpreted as True: true, yes, on, 1.
The following values are interpreted as False: false, no, off, 0.
Unique prefixes of these strings are also accepted, for example t or n. Leading or trailing whitespace is ignored, and case does not matter.
String
Columns with type String are interpreted as text.
Image
Columns with type Image are interpreted as image references. This type is used for ZIP image datasets, and cannot be set manually. The column type for a column with type Image also cannot be updated.
External Image
Columns with type External Image are interpreted as URLs to external images. This type is used for external media image datasets.
Example external media image dataset
| _ | img | label |
|---|---|---|
| 0 | https://s.cleanlab.ai/DCA_Competition_2023_Dat… | c |
| 1 | https://s.cleanlab.ai/DCA_Competition_2023_Dat… | h |
| 2 | https://s.cleanlab.ai/DCA_Competition_2023_Dat… | y |
| 3 | https://s.cleanlab.ai/DCA_Competition_2023_Dat… | p |
| 4 | https://s.cleanlab.ai/DCA_Competition_2023_Dat… | j |
Document
Columns with type Document are interpreted as document references. This type is used for ZIP document datasets, and cannot be set manually. The column type for a column with type Document also cannot be updated. Such a column is used to track which extracted text and Cleanlab results correspond to which document in a document dataset.
External Document
Column with type External Document are interpreted as URLs to external documents. This type is used for external media document datasets.
Date
Columns with type Date are interpreted as dates. The column sub-types specify how the data is converted into a date.
For example, date_epoch_s specifies that the column contains Unix timestamps in seconds.
date_parse specifies that the column contains dates in a custom format, which is parsed from the following formats:
| Format | Example | Description |
|---|---|---|
%Y-%m-%d | 1999-02-15 | ISO 8601 format |
%Y/%m/%d | 1999/02/15 | |
%B %d, %Y | February 15, 1999 | |
%Y-%b-%d | 1999-Feb-15 | |
%d-%m-%Y | 15-02-1999 | |
%d/%m/%Y | 15/02/1999 | |
%d-%b-%Y | 15-Feb-1999 | |
%b-%d-%Y | Feb-15-1999 | |
%d-%b-%y | 15-Feb-99 | |
%b-%d-%y | Feb-15-99 | |
%Y%m%d | 19990215 | |
%y%m%d | 990215 | |
%Y.%j | 1999.46 | year and day of year |
%m-%d-%Y | 02-15-1999 | |
%m/%d/%Y | 02/15/1999 |
For more information on format codes, see the Python documentation.
Time
Columns with type Time are interpreted as times. The column sub-types specify how the data is converted to a time.
For example, time_epoch_us specifies that the column contains Unix timestamps in microseconds.
time_parse specifies that the column contains times in a custom format, which is parsed from the following formats:
| Format | Example | Description |
|---|---|---|
%H:%M:%S.%f | 04:05:06.789 | ISO 8601 format |
%H:%M:%S | 04:05:06 | ISO 8601 format |
%H:%M | 04:05 | ISO 8601 format |
%H%M%S | 040506 | |
%H%M | 0405 | |
%H%M%S.%f | 040506.789 | |
%I:%M %p | 04:05 AM | |
%I:%M:%S %p | 04:05:06 PM | |
%H:%M:%S.%f%z | 04:05:06.789-08:00 | ISO 8601 format with UTC offset for PST timezone |
%H:%M:%S%z | 04:05:06-08:00 | |
%H:%M%z | 04:05-08:00 | |
%H%M%S.%f%z | 040506.789-08:00 | |
%H:%M:%S.%f %Z | 04:05:06.789 PST | Note: most common timezone abbreviations are supported, but not all. See full list in section below. |
%H:%M:%S %Z | 04:05:06 PST | |
%H:%M %Z | 04:05 PST | |
%H%M %Z | 0405 PST | |
%H%M%S.%f | 040506.789 PST | |
%I:%M %p %Z | 04:05 AM PST | |
%I:%M:%S %p %Z | 04:05:06 PM PST |
For more information on format codes, see the Python documentation.
Supported Time Zone Abbreviations
| Time Zone | UTC Offset | Description |
|---|---|---|
| NZDT | +13:00 | New Zealand Daylight Time |
| IDLE | +12:00 | International Date Line, East |
| NZST | +12:00 | New Zealand Standard Time |
| NZT | +12:00 | New Zealand Time |
| AESST | +11:00 | Australia Eastern Summer Standard Time |
| ACSST | +10:30 | Central Australia Summer Standard Time |
| CADT | +10:30 | Central Australia Daylight Savings Time |
| SADT | +10:30 | South Australian Daylight Time |
| AEST | +10:00 | Australia Eastern Standard Time |
| EAST | +10:00 | East Australian Standard Time |
| GST | +10:00 | Guam Standard Time |
| LIGT | +10:00 | Melbourne, Australia |
| SAST | +09:30 | South Australia Standard Time |
| CAST | +09:30 | Central Australia Standard Time |
| AWSST | +09:00 | Australia Western Summer Standard Time |
| JST | +09:00 | Japan Standard Time |
| KST | +09:00 | Korea Standard Time |
| MHT | +09:00 | Kwajalein Time |
| WDT | +09:00 | West Australian Daylight Time |
| MT | +08:30 | Moluccas Time |
| AWST | +08:00 | Australia Western Standard Time |
| CCT | +08:00 | China Coastal Time |
| WADT | +08:00 | West Australian Daylight Time |
| WST | +08:00 | West Australian Standard Time |
| JT | +07:30 | Java Time |
| ALMST | +07:00 | Almaty Summer Time |
| WAST | +07:00 | West Australian Standard Time |
| CXT | +07:00 | Christmas (Island) Time |
| ALMT | +06:00 | Almaty Time |
| MAWT | +06:00 | Mawson (Antarctica) Time |
| IOT | +05:00 | Indian Chagos Time |
| MVT | +05:00 | Maldives Island Time |
| TFT | +05:00 | Kerguelen Time |
| AFT | +04:30 | Afganistan Time |
| EAST | +04:00 | Antananarivo Savings Time |
| MUT | +04:00 | Mauritius Island Time |
| RET | +04:00 | Reunion Island Time |
| SCT | +04:00 | Mahe Island Time |
| IT | +03:30 | Iran Time |
| EAT | +03:00 | Antananarivo, Comoro Time |
| BT | +03:00 | Baghdad Time |
| EETDST | +03:00 | Eastern Europe Daylight Savings Time |
| HMT | +03:00 | Hellas Mediterranean Time (?) |
| BDST | +02:00 | British Double Standard Time |
| CEST | +02:00 | Central European Savings Time |
| CETDST | +02:00 | Central European Daylight Savings Time |
| EET | +02:00 | Eastern Europe, USSR Zone 1 |
| FWT | +02:00 | French Winter Time |
| IST | +02:00 | Israel Standard Time |
| MEST | +02:00 | Middle Europe Summer Time |
| METDST | +02:00 | Middle Europe Daylight Time |
| SST | +02:00 | Swedish Summer Time |
| BST | +01:00 | British Summer Time |
| CET | +01:00 | Central European Time |
| DNT | +01:00 | Dansk Normal Tid |
| FST | +01:00 | French Summer Time |
| MET | +01:00 | Middle Europe Time |
| MEWT | +01:00 | Middle Europe Winter Time |
| MEZ | +01:00 | Middle Europe Zone |
| NOR | +01:00 | Norway Standard Time |
| SET | +01:00 | Seychelles Time |
| SWT | +01:00 | Swedish Winter Time |
| WETDST | +01:00 | Western Europe Daylight Savings Time |
| GMT | +00:00 | Greenwich Mean Time |
| UT | +00:00 | Universal Time |
| UTC | +00:00 | Universal Time, Coordinated |
| Z | +00:00 | Same as UTC |
| ZULU | +00:00 | Same as UTC |
| WET | +00:00 | Western Europe |
| WAT | -01:00 | West Africa Time |
| NDT | -02:30 | Newfoundland Daylight Time |
| ADT | -03:00 | Atlantic Daylight Time |
| AWT | -03:00 | (unknown) |
| NFT | -03:30 | Newfoundland Standard Time |
| NST | -03:30 | Newfoundland Standard Time |
| AST | -04:00 | Atlantic Standard Time (Canada) |
| ACST | -04:00 | Atlantic/Porto Acre Summer Time |
| ACT | -05:00 | Atlantic/Porto Acre Standard Time |
| EDT | -04:00 | Eastern Daylight Time |
| CDT | -05:00 | Central Daylight Time |
| EST | -05:00 | Eastern Standard Time |
| CST | -06:00 | Central Standard Time |
| MDT | -06:00 | Mountain Daylight Time |
| MST | -07:00 | Mountain Standard Time |
| PDT | -07:00 | Pacific Daylight Time |
| AKDT | -08:00 | Alaska Daylight Time |
| PST | -08:00 | Pacific Standard Time |
| YDT | -08:00 | Yukon Daylight Time |
| AKST | -09:00 | Alaska Standard Time |
| HDT | -09:00 | Hawaii/Alaska Daylight Time |
| YST | -09:00 | Yukon Standard Time |
| AHST | -10:00 | Alaska-Hawaii Standard Time |
| HST | -10:00 | Hawaii Standard Time |
| CAT | -10:00 | Central Alaska Time |
| NT | -11:00 | Nome Time |
| IDLW | -12:00 | International Date Line, West |
Datetime
Columns with type Datetime are interpreted as datetimes. The column sub-types specify how the data is converted to a datetime.
For example, datetime_epoch_ms specifies that the column contains Unix timestamps in milliseconds.
datetime_parse specifies that the column contains datetimes in a custom format. Some examples of supported formats are listed below (we support any combination of the date and time formats):
| Format | Example |
|---|---|
%Y-%m-%dT%H:%M:%S.%f | 1999-02-15T04:05:06.789 |
%Y/%m/%d %H:%M | 1999/02/15 04:05 |
%B %d, %Y %I:%M %p %Z | February 15, 1999 04:05 AM PST |
%Y%m%dT%H%M%S | 19990215T040506 |
For more information on format codes, see the Python documentation.
Schema Updates
If you do nothing, Cleanlab Studio will automatically infer the column types in your dataset that lead to the best results. However you sometimes may wish to enforce certain column types (e.g. to specify that a column of integers actually represents discrete categories rather than numeric data). There are two ways to enforce a particular schema (column types) for your dataset:
- Using the Web Application after loading your dataset.
- Providing a schema override when programmatically loading your dataset via Python API. You can provide partial schema overrides by specifying column types for a subset of columns. You do not need to provide overrides for all columns in your dataset.
[
{
"name": "<name of column to override>",
"column_type": "<column type to update to>"
}
]
For an example of using schema overrides in the Python API, see our regression tutorial.
Data Ingestion
You can load your data into Cleanlab Studio from various sources: local files, cloud storage, using the Python API, etc.
Dataset Ingestion via Signed URL
If you are trying to ingest your private data into Cleanlab Studio via a URL, you can do so using a signed URL from the external cloud provider you are using. For example, you may have a bucket in your cloud provider containing image data. You can create a signed URL that will give temporary access to this bucket of images, so that you are able to ingest the images into Cleanlab Studio. The signed URL you create will have an expiration time that only allows access to the data it is connected to for a limited time within your cloud environment. You only need an amount of time that is necessary to ingest the data into Cleanlab Studio, so we suggest starting with a 1-2 hour limit that you can adjust accordingly. Once the data from your bucket is ingested into Cleanlab Studio via the signed URL, the data will still be available within Cleanlab Studio even if the URL (access to the bucket) expires.
Whether you are creating a URL for images or another data modality, you will need to format the data in your private cloud bucket properly first depending on the modality and you can refer to the Modalities section on this page for more details.
To actually generate the signed URL, you can refer to this page for a reference on how to do this from Google Cloud Platform (GCP) or this page for a reference on how to do this from Amazon Web Services (AWS).
Once you have generated the URL, simply copy and paste it into the Upload via URL option in the Cleanlab Studio data ingestion page. This is a simple way to run Cleanlab Studio on data in your private GCP/AWS storage. Alternate ways are available on the Enterprise plan.