Cleanset
A Cleanset is an improved version of your original dataset. You create one by labeling unlabed data or fixing detected data issues in your dataset, such as correcting erroneous labels or excluding examples that are outliers/duplicates. Use the Resolver to correct individual data points or Clean Top K button (at the bottom of a Project) to auto-fix many data points simultaneously. The resulting improved dataset has the same format as your original dataset and can be used as a plug-in replacement to get more reliable downstream modeling and analytics. After making your data improvements, obtain the Cleanset by exporting it from the web interface or Python API.

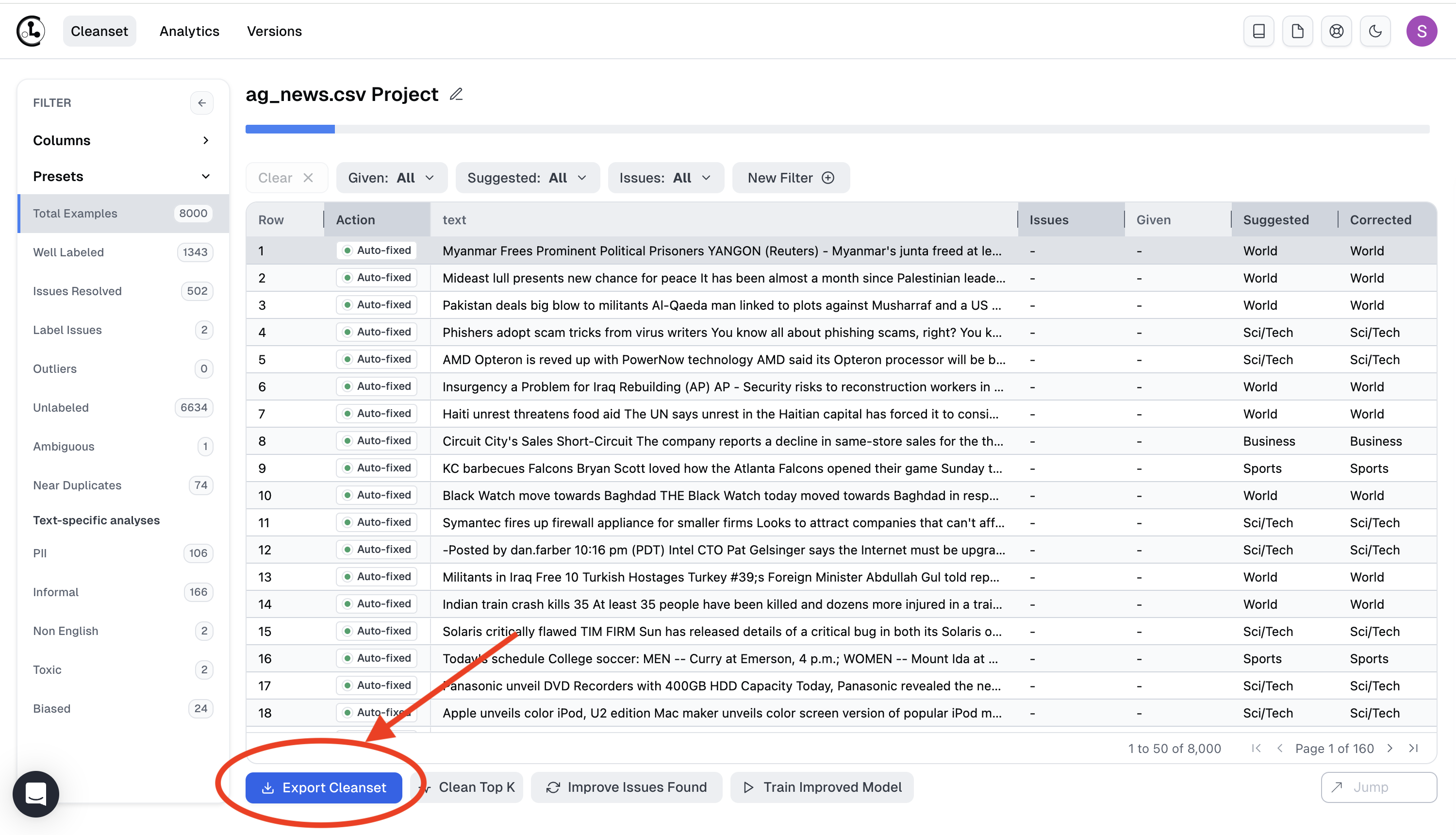
Exporting Cleanset
Web version
You can export your Cleanset by using the Export Cleanset button in the Web UI.
Python API
Alternatively, you can export your cleanset programmatically. Retrieve the Cleanset ID by selecting Export Cleanset and then Export Using API. Then, use the download_cleanlab_columns method from the API. Here’s a code snippet showing how to do this.
from cleanlab_studio import Studio
studio = Studio('YOUR_API_KEY')
cleanlab_columns = studio.download_cleanlab_columns('YOUR_CLEANSET_ID')
The Cleanset is exported with the same structure as your original dataset, making it a drop-in replacement with little effort. The exported Cleanset contains many columns of smart metadata that can be used to further make informed decisions. It contains the original label column (if your dataset had labels), columns specific to issues found in the dataset, and additional metadata columns related to model training and dataset provided by Cleanlab’s AutoML. Please note that the content of all these columns is collected from the Cleanlab Studio Project run.
Label column
This column is specific to your dataset and has the same name as the label column in the dataset. These are the labels present in the dataset before running Cleanlab analysis.
Issue Specific columns
These are columns related to issues detected by Cleanlab like label issues, outliers, etc. The detailed descriptions of issue related columns can be found in Cleanlab Columns guide.
Other Metadata columns
Apart from issue columns, the Cleanset also contains some metadata columns related to model training and dataset.
cleanlab_corrected_label
This column contains the corrected labels and the labels assigned to unlabeled rows in the dataset.
cleanlab_action
This column indicates the state of action. For rows where there was no suggested action it is empty. For other rows where an action is suggested, it shows whether it is unresolved or the action taken on that row, for example auto-fix or exclude.
cleanlab_given_label_prob
This column contains the probability of the given label as determined by Cleanlab’s AutoML.
cleanlab_has_rare_class
This is a boolean column indicating whether the specific row lies belongs to a rare class. Here, a rare class refers to a class that has less than 5 samples in the dataset.
cleanlab_is_initially_unlabeled
This is a boolean column indicating whether the specific row was initially unlabeled in the dataset.
cleanlab_predicted_label
This column contains the label predicted by Cleanlab’s AutoML.
cleanlab_predicted_label_prob
This column contains the probability of the label predicted by Cleanlab’s AutoML.
cleanlab_top_labels
This column contains the top suggested labels for the each row in descending order.
cleanlab_top_probs
This column contains the probabilities of top suggested labels for each row in descending order.
Creating Improved dataset from Cleanset
import pandas as pd
cleanlab_columns = pd.read_csv("cleanlab_ag_news.csv")
# Construct final labels using original labels, auto-labeled and corrected labels
cleanlab_columns["label"] = cleanlab_columns["label"].fillna(
cleanlab_columns["cleanlab_corrected_label"]
)
# Set the index of cleanlab columns same as the index of the dataset
cleanlab_columns["cleanlab_row_ID"] = cleanlab_columns["cleanlab_row_ID"] - 1
cleanlab_columns.set_index("cleanlab_row_ID", inplace=True)
cleanlab_columns.index.name = None
# Merge cleanlab columns with the original dataset
# This will automatically handle excluded rows
df = pd.read_csv("ag_news.csv")
new_df = df.merge(
cleanlab_columns[["label"]],
left_index=True,
right_index=True,
suffixes=("_original", "_cleaned"),
)
# Drop unnecessary columns and save the cleaned dataset
new_df = new_df.drop(columns=["label_original"])
new_df = new_df.rename(columns={"label_cleaned": "label"})
new_df.to_csv("ag_news_cleaned.csv", index=False)
Improve Results
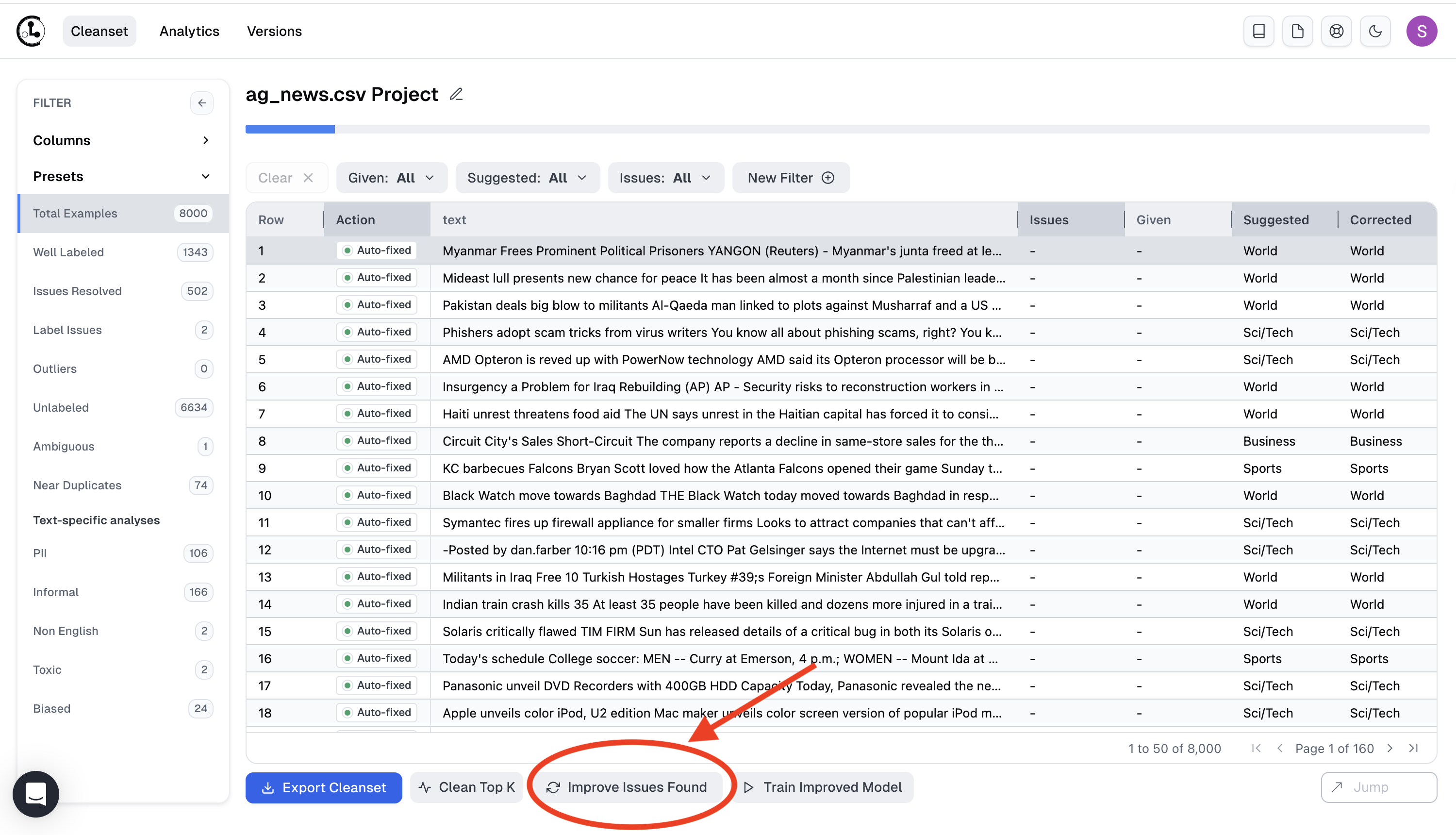
Cleanlab Studio learns to iteratively improve results as you fix issues and label unlabeled examples in the dataset. Once you’ve improved more than 5% of your dataset, click Improve Issues Found to obtain further improved data quality analysis and suggested actions. Selecting Improve Issues Found re-runs Cleanlab Studio to incorporate the corrected issues and labeled examples you added. This allows Cleanlab Studio to learn from your corrections which yields more accurate detection of data issues and suggested labels.
A recommended workflow is:
- Run Cleanlab Studio on your original dataset
- Correct 5%-50% of the detected issues
- Run
Improve Issues Found - Repeat steps 2 and 3 until you achieve desired data quality or ML model deployment accuracy.
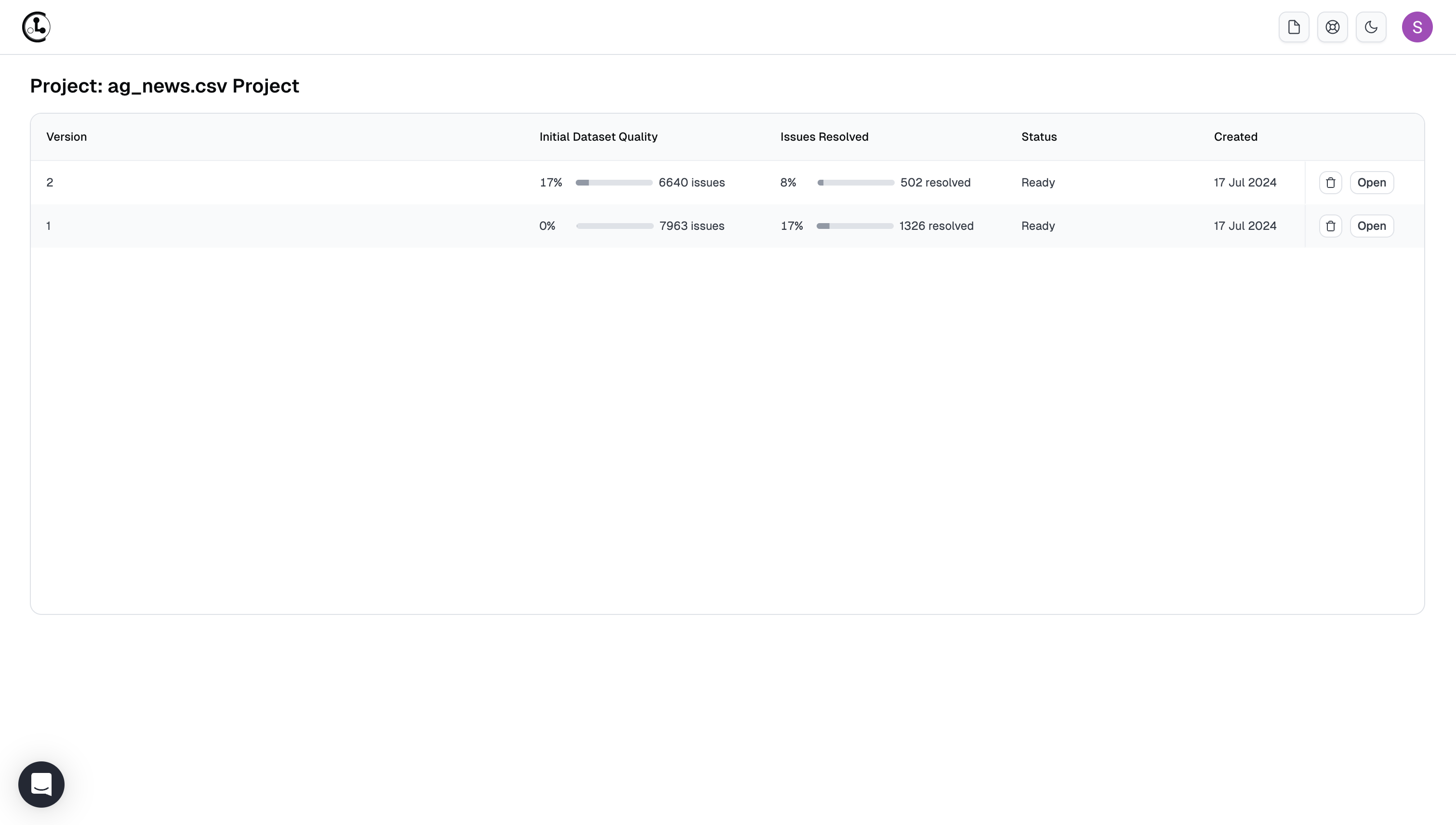
Dataset Versions
Cleanlab Studio creates a dataset snapshot each time you run analyses on your dataset (or Cleanset) via Improve Issues Found. These versions are accessible via the Versions button. The snapshot saves your dataset corrections and labels that were made at that point in time. This allows you to revisit the state of the dataset at each re-run of the Project.
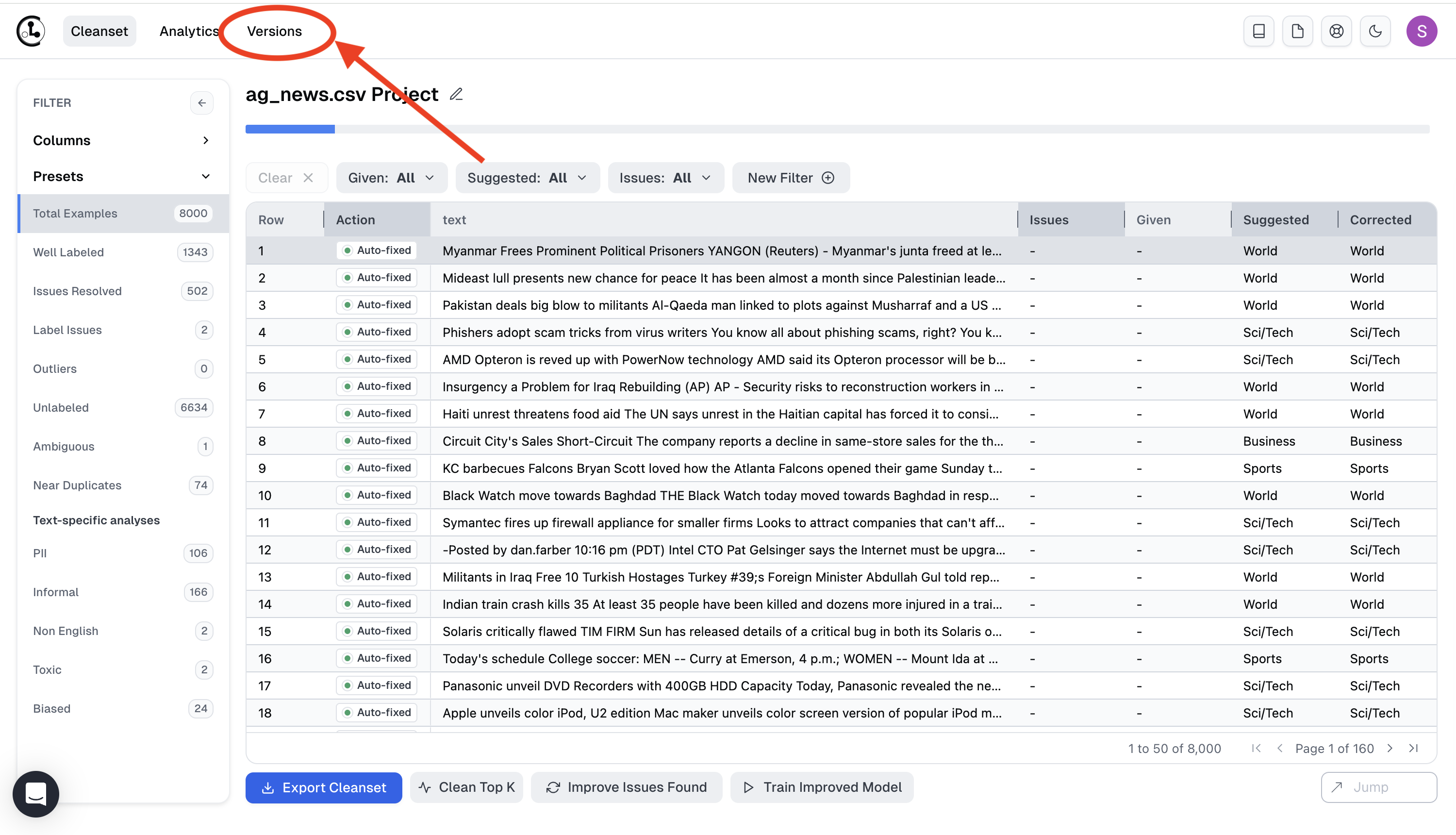
Here you can view each stage of dataset correction, with recent data corrections that produced the newest Cleanset version building on top of older data corrections from previous Cleansets. Use this to export an older dataset version and track which stage of dataset corrections produce the best downstream results.