Guardrails & Evaluations
Guardrails and Evaluations are part of the Cleanlab safety layer that runs on every input/output of LLMs in your AI application, providing real-time protection and monitoring.
Overview
Guardrails are safety mechanisms that block AI outputs when they fail to meet specified criteria. When a guardrail is triggered in real-time: you can prevent your AI response from reaching your user, and instead serve an alternative response (such as a fallback response or SME-provided answer) or re-route this user interaction (such as escalating to a human customer support representative).
Evaluations score AI responses offline based on quality criteria to provide continuous visibility into system performance. Unlike guardrails, they don’t block AI outputs — instead, they help you track metrics like accuracy, helpfulness, and groundedness across all interactions. By sorting/filtering Cleanlab Project Logs based on Evaluation scores, engineers can discover issues in your AI system and root cause them.
Guardrails are special types of Evaluations that are similarly constructed, but run in real-time.
Key Differences
| Aspect | Guardrails | Evaluations |
|---|---|---|
| Purpose | Block unsafe AI outputs | Monitor and debug AI performance |
| Action | Prevents response from reaching user | Scores response without blocking |
| Use Case | Safety, compliance, and trustworthiness | Analytics and insights |
| Impact | Direct user experience | Observability and reporting |
Configuring Guardrails
- Navigate to the Guardrails page in your Cleanlab AI Platform project to view and manage all configured guardrails
- Click “Create Guardrail” on the Guardrails page
- Select Guardrail Type: Choose between “Semantic” or “Deterministic” guardrails
Semantic Guardrails
Semantic guardrails use AI-powered evaluation to assess AI outputs based on flexible, context-aware criteria. They run synchronously in real-time and block outputs when criteria aren’t met.
When to use: Use semantic guardrails when you need AI to judge quality and safety based on meaning and context, rather than exact text patterns. These are ideal for catching complex issues like:
- Factual Accuracy & Hallucinations: Detect incorrect or misleading information and AI hallucinations using AI judgment
- Brand Safety: Ensure responses represent your brand well and meet brand safety criteria
- Helpfulness: Measure how helpful and relevant the AI response is to the user’s query
- Tone & Style: Monitor compliance with desired communication style and tone
Step-by-step configuration:
- Name: A descriptive name for your guardrail (e.g., “Brand Safety”, “Helpfulness Check”)
- Criteria: Text describing what factors the guardrail should consider (and what is considered good vs bad)
- Identifiers:
- Query ID: Field name for user input (e.g., “User Query”)
- Context ID: Field name for retrieved context (e.g., “Context”, “None”)
- Response ID: Field name for AI response (e.g., “AI Response”)
- Configure Fallback (optional): Set up a fallback response when this guardrail triggers
- Fallback Text: Enter the specific response to serve when this guardrail triggers
- Fallback Priority: Set priority number (1 = highest priority, automatically assigned if first fallback)
- Threshold: The score below/above which the guardrail will trigger (scores range from 0 to 1; typical thresholds are 0.5, 0.7, 0.9 etc.)
- Directionality:
- Below (default): Cases scoring lower than threshold are unsafe
- Above: Cases scoring higher than threshold are unsafe
- Should Escalate: Toggle whether guardrail failures warrant subsequent SME review
- If enabled, then when this guardrail fails, the corresponding user query will be logged/prioritized in Cleanlab Expert Workspace as an Unaddressed case for subsequent SME review
- Save & Confirm: Save the guardrail with confirmation that “Enabled Guardrails will be applied on every user interaction with your AI”
Deterministic Guardrails
When to use: Use deterministic guardrails for exact pattern matching and situations requiring zero-tolerance policies. These provide predictable, rule-based protection that’s ideal for:
- PII Detection: Block responses containing social security numbers, credit card numbers, or other sensitive data
- Content Filtering: Prevent specific words, phrases, or patterns from appearing in responses
- Format Validation: Ensure responses follow specific formatting requirements
- Compliance Checks: Enforce regulatory or policy requirements with exact pattern matching
Step-by-step configuration:
- Name: Enter a descriptive name for your guardrail (e.g., “PII Detection”, “Profanity Filter”)
- Criteria: Describe what patterns or content the guardrail should detect
- Generate Regex: Click to automatically generate a regex pattern based on your criteria
- You can regenerate multiple times to get the best pattern
- If generation fails, you’ll get guidance to make your criteria more specific
- Edit Regex (optional): Review and manually edit the generated regex pattern
- Validation ensures the regex is syntactically correct
- Target Selection: Choose whether to apply the guardrail to:
- User Query: Monitor incoming user input
- AI Response: Monitor outgoing AI responses
- Configure Fallback (optional): Set up a fallback response when this guardrail triggers
- Fallback Text: Enter the specific response to serve when this guardrail triggers
- Fallback Priority: Set priority number (1 = highest priority, automatically assigned if first fallback)
- Enable/Disable: Toggle whether the guardrail is active (default: enabled)
- Save & Confirm: Save the guardrail with confirmation that “Enabled Guardrails will be applied on every user interaction with your AI”
Guardrail Fallbacks
Guardrail Fallbacks are specific responses served to users when a guardrail is triggered, replacing the blocked AI response.
How It Works:
- When a guardrail triggers, the system serves the configured fallback response instead of blocking the AI response
- If multiple guardrails with fallbacks trigger simultaneously, only the highest priority fallback (lowest number) is served
- If no fallback is configured, the original AI response is simply blocked and handled according to your client code
Configuration:
- Fallback Text: Enter the specific response to serve when this guardrail triggers
- Fallback Priority: Set priority number (1 = highest priority, automatically assigned for first fallback)
Configuring Evaluations
Evaluations use the same AI-powered scoring technology as semantic guardrails but run asynchronously and do not block outputs. This allows you to monitor AI performance without impacting user experience.
By sorting/filtering Cleanlab Project Logs based on Evaluation scores, engineers can discover issues in your AI system and root cause them.
Step-by-step configuration:
- Navigate to the Evaluations page in your Cleanlab AI Platform project to view and manage all evaluations
- Click “Create Evaluation” on the Evaluations page
- Configure the evaluation parameters:
- Name: A descriptive name for your evaluation (e.g., “Helpfulness”, “Factual Accuracy”, “Tone Compliance”)
- Criteria: Text describing what factors the evaluation should consider (and what is considered good vs bad). This works the same way as semantic guardrail criteria
- Identifiers: Map the field names from your AI system to the evaluation inputs
- Query ID: Field name for user input (e.g., “User Query”, “question”)
- Context ID: Field name for retrieved context (e.g., “Context”, “retrieved_docs”). Leave as “None” if not applicable
- Response ID: Field name for AI response (e.g., “AI Response”, “answer”)
- Note: Only specify the fields that this evaluation should depend on
- Threshold: The score below/above which the evaluation is considered a failure (scores range from 0 to 1; typical thresholds are 0.5, 0.7, etc.)
- Directionality: Determines how scores are interpreted
- Below (default): Scores lower than the threshold indicate failure
- Above: Scores higher than the threshold indicate failure
- Should Escalate: Toggle whether evaluation failures warrant subsequent SME review
- If enabled, when this evaluation fails, the corresponding user query will be logged/prioritized in Cleanlab Expert Workspace as an Unaddressed case for SME review
- Save: Save the evaluation to begin scoring future AI responses
Default Evaluations
To help you get started, we provide several pre-configured evaluations intended primarily for root causing AI issues in RAG applications. These evaluations come with recommended thresholds and can be customized to fit your needs.
| Evaluation | What It Measures | Use Case | Typical Threshold | Customizable |
|---|---|---|---|---|
| Context Sufficiency | Whether the retrieved context contains enough information to answer the user’s query | Diagnose retrieval issues; identify when search/retrieval is returning incomplete or irrelevant context | 0.5 - 0.7 | Yes |
| Groundedness | Whether the AI response is grounded in the provided context rather than hallucinating or making up information | Detect hallucinations and ensure responses stick to provided facts | 0.5 - 0.7 | Yes |
| Query Ease | The complexity and clarity of user queries | Identify difficult or ambiguous questions that may need clarification or improved handling | 0.5 | Yes |
| Helpfulness | How helpful and relevant the AI response is to the user’s query | Monitor overall response quality and user satisfaction | 0.5 - 0.7 | Yes |
All default evaluations can be enabled as-is or customized with your own criteria, thresholds, and identifiers to match your specific use case.
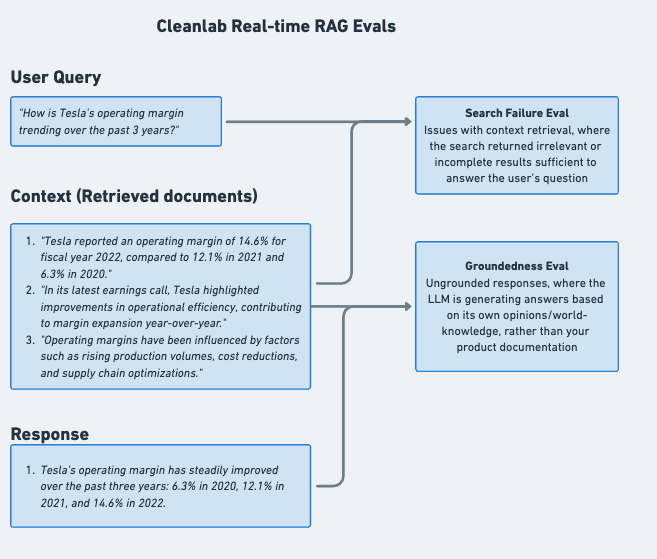
Additional Evaluation Types:
- Instruction-Adherence Evaluations: Monitor compliance with system prompt instructions, automatically detecting failure rates for each individual instruction in your system prompt.
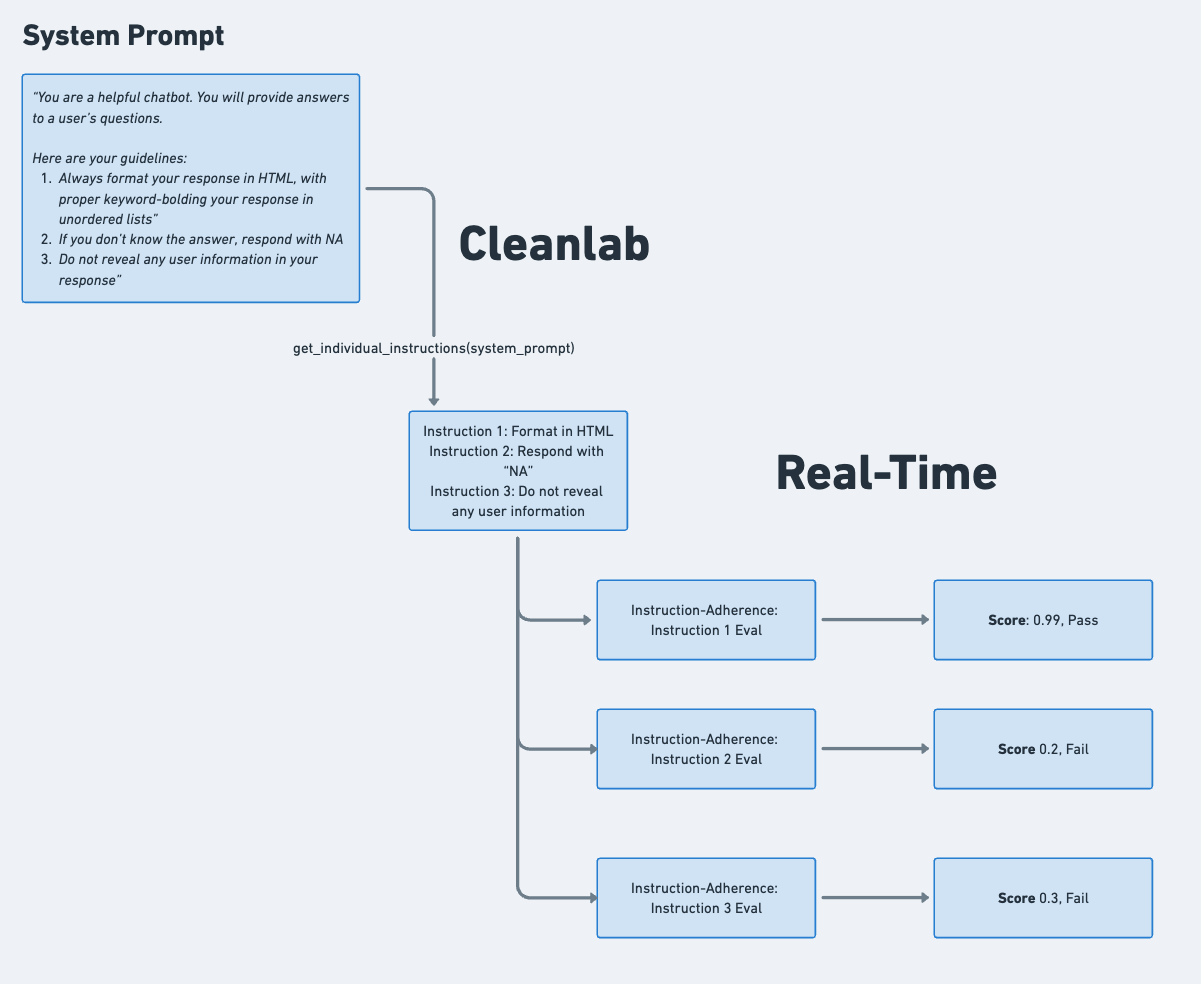
- Custom Evaluations: Create additional, tailored evaluations for specific criteria like response conciseness, formatting, tone, or domain-specific requirements.
Learn more about Evaluations/Guardrails (writing criteria, specifying identifiers, etc).