Guardrails/Evaluations in Cleanlab
Cleanlab offers powerful detectors to diagnose and prevent bad responses from your AI: Evaluations and Guardrails. You can configure these as needed for your use-case, instantiating new detectors or utilizing/modifying the pre-configured detectors that are generally useful.
Powered by Cleanlab’s Trustworthy Language Model, Evaluations can be used to score the AI Response (or other fields like the User Query or Retrieved Context) according to criteria that you specify. These Evaluations run offline, and are useful for diagnosing / root-causing why a particular AI Response was bad, as well as monitoring/analytics.
Guardrails are special types of Evaluations that are similarly constructed, but these run in real-time. When a Guardrail flags your AI response, you can prevent this response from being served to your user.
Overview
Cleanlab provides four main types of evaluators that can be configured as either Guardrails or Evaluations:
- Trustworthiness Evaluations: Score the general reliability and accuracy of each LLM response
- TrustworthyRAG Evaluations: Root-cause RAG-specific failures and quality issues
- Instruction-Adherence Evaluations: Monitor compliance with system prompt instructions
- Custom Evaluations: Create additional, tailored evaluations for specific criteria
Note: These evaluation types can be configured as either:
- Guardrails: When used to block unsafe AI outputs
- Evaluations: When used for monitoring and analytics (no blocking)
For detailed configuration of guardrails and evaluations in the Cleanlab AI Platform interface, see the Guardrails & Evaluations documentation.
Trustworthiness Evaluations - Score and monitor the reliability of your LLM responses in real-time
What does it detect?
Trustworthiness Evaluations provide real-time scoring of LLM responses across various dimensions:
- Factual Accuracy: Detects incorrect or misleading information
- Confidence Level: Measures the model’s certainty in its responses
How it works
Trustworthiness Evaluations are powered by Cleanlab’s Trustworthy Language Model (TLM), which:
- Uses state-of-the-art uncertainty estimation techniques
- Can evaluate responses from any LLM (not just Cleanlab’s)

Figure 1: How Trustworthiness Evaluations work. The evaluation takes the user’s query and the LLM’s response as input, processes them through Cleanlab’s Trustworthy Language Model, and outputs a trustworthiness score between 0 and 1.
Usage as Guardrails vs Evaluations
- As a Guardrail: Block responses with low trustworthiness scores to prevent unreliable information from reaching users.
- As an Evaluation: Monitor AI trustworthiness trends over time, and be able to quickly find incorrect responses later on when reviewing AI performance.
TrustworthyRAG Evaluations - Root-cause RAG-specific issues that are causing your AI to serve bad responses
What does it detect?
TrustworthyRAG provides real-time evaluation of RAG-specific issues:
- Search Failures: Issues with context retrieval, where your RAG’s underlying search returned irrelevant or incomplete results that cannot answer the user’s question
- Hallucinations: Ungrounded or untrustworthy responses, where the LLM is generating answers based on its own opinions/world-knowledge, rather than your product documentation
- Unhelpful Responses: Other quality issues, where though the information may be true and grounded in your internal knowledge, it’s not aligned with the intent of the user
- Difficult Queries: Complex or ambiguous user questions that root-cause the issues
How does it work?
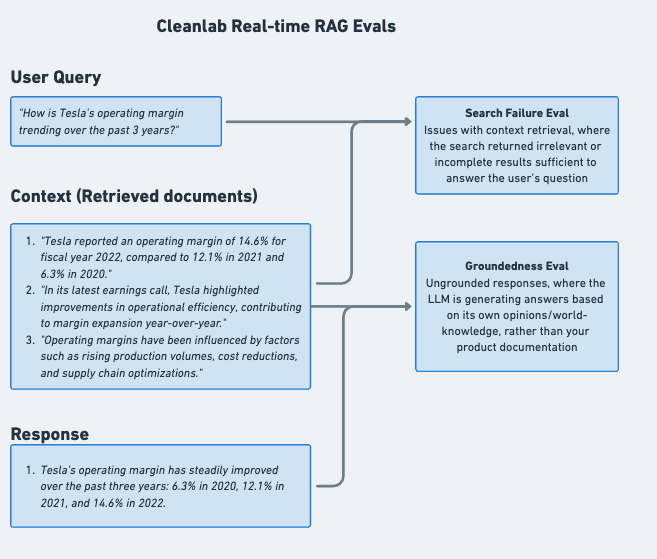
Figure 2: TrustworthyRAG Evaluation process. The system evaluates the query, retrieved context, and LLM response to identify specific RAG-related issues and assign appropriate scores.
Usage as Guardrails vs Evaluations
- As Guardrails: Block responses with search failures, hallucinations, or unhelpful content
- As Evaluations: Monitor RAG performance patterns and identify systemic issues in your knowledge base or search system
Instruction-Adherence Evaluations - Ensure your AI is following the instructions in your system prompt
What does it detect?
Instruction-Adherence Evaluations automatically detect failure rates for each individual instruction in your system prompt, such as:
- Policy compliance (e.g., “Do not expose account details without identity verification”)
- User experience guidelines (e.g., “Always output responses in HTML”)
- Customer-specific requirements
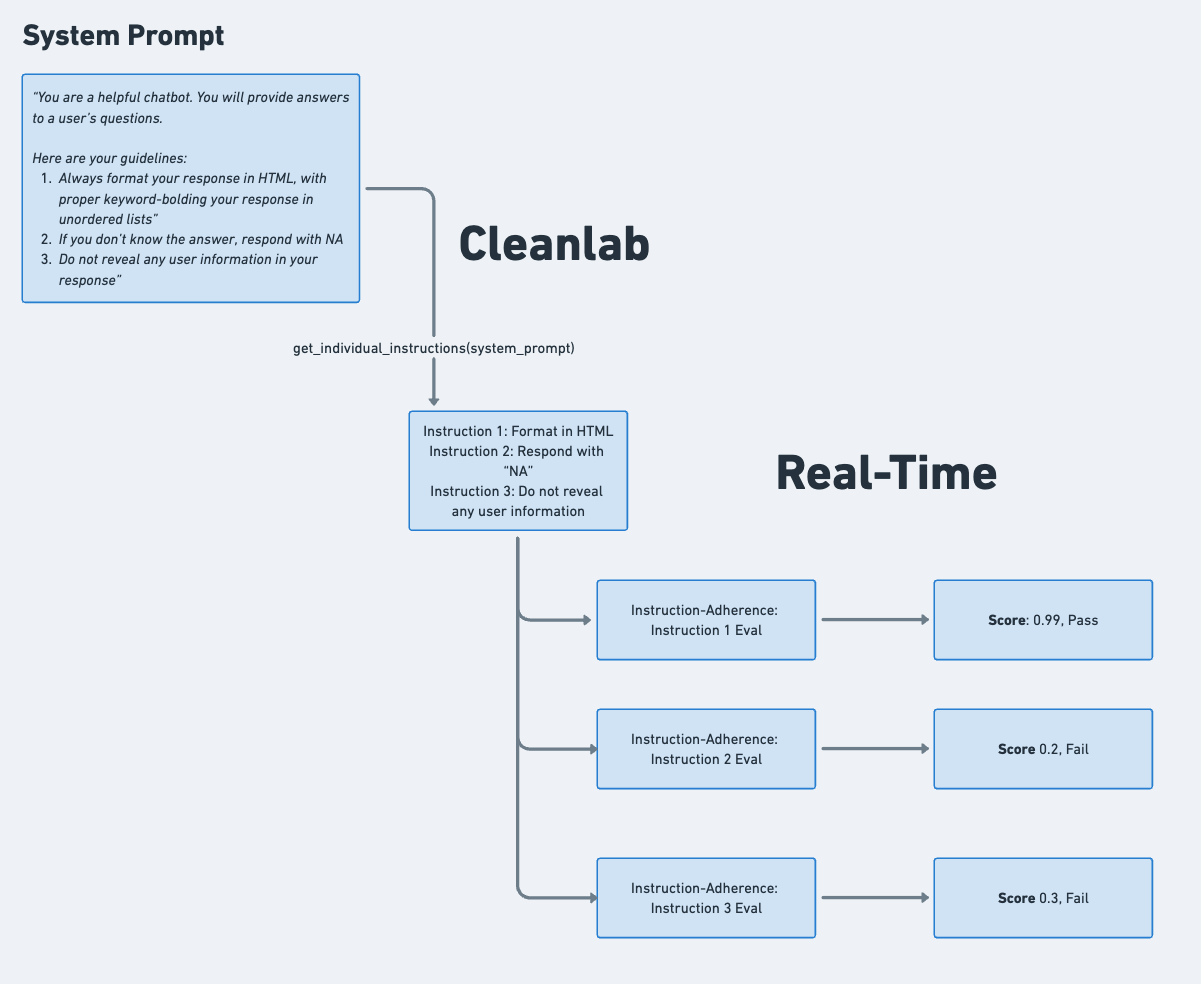 Figure 3: Instruction-Adherence Evaluation workflow. The system parses the system prompt into individual instructions, evaluates the LLM’s response against each instruction, and identifies any compliance failures.
Figure 3: Instruction-Adherence Evaluation workflow. The system parses the system prompt into individual instructions, evaluates the LLM’s response against each instruction, and identifies any compliance failures.
Key Benefits
- Real-time Monitoring: Detect spikes in policy failures immediately
- Quantitative Health Metrics: Measure instruction compliance rates in analytics
- Automatic Evaluation: No need to maintain custom evals for new instructions
- Detailed Logging: Drill into specific instruction-failure cases
Usage as Guardrails vs Evaluations
- As Guardrails: Block responses that violate critical system instructions or policies
- As Evaluations: Monitor compliance rates and identify which instructions are most frequently violated
Custom Evaluations - Create tailored evaluations for your specific needs
What are Custom Evaluations?
Custom evaluations allow you to define specific criteria for assessing your AI application’s performance. You can evaluate aspects such as:
- Response conciseness and clarity
- Formatting and structure
- Tone and style
- Domain-specific requirements
- Internal compliance guidelines
Usage as Guardrails vs Evaluations
- As Guardrails: Block responses that don’t meet your specific quality or safety criteria
- As Evaluations: Monitor performance against your custom metrics and identify improvement opportunities