Detect and remediate bad responses from Tool Calling AI applications

This notebok demonstrates how to automatically improve any Tool Calling AI application by integrating Cleanlab. Cleanlab will automatically detect if your AI response is bad (e.g. untrustworthy, unhelpful, or unsafe), returning real-time scores you can use to guardrail your AI and prevent wrong responses or tool calls.
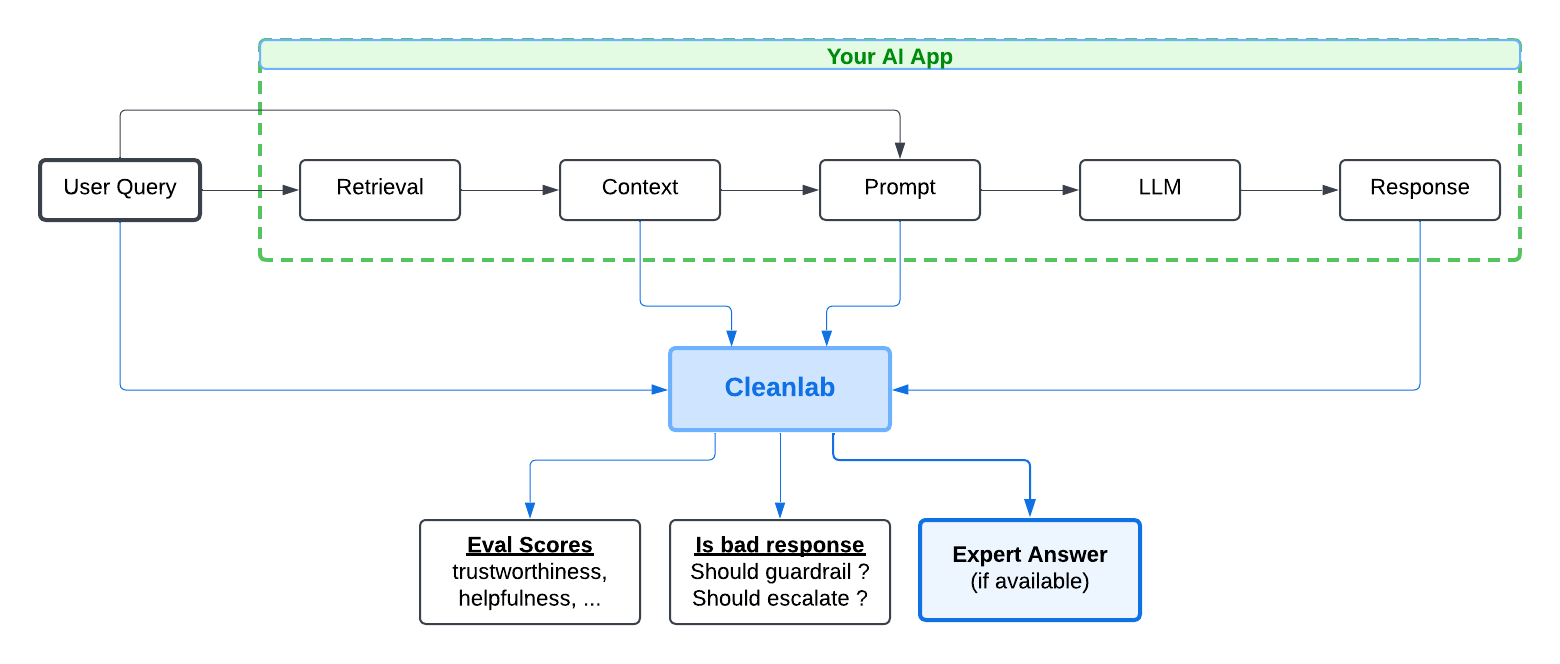
Note: While this tutorial uses OpenAI as an example Tool Calling AI Agent, Cleanlab works with any AI Agent and Tool Calling framework (simply translate your Agent outputs into OpenAI format as necessary).
Overview
This notebook shows how Cleanlab can detect and prevent wrong Tool Calls or bad AI responses from happening, and also serve expert answers in scenarios where your AI previously responded incorrectly or output a wrong Tool Call.
Setup
This tutorial requires a Cleanlab API key. Get one here.
%pip install --upgrade cleanlab-codex pandas
# Set your Codex API key
import os
os.environ["OPENAI_API_KEY"] = "<API key>" # Get your free API key from: https://platform.openai.com/account/api-keys
os.environ["CODEX_API_KEY"] = "<API key>" # Get your free API key from: https://codex.cleanlab.ai/account
# Import libraries
from cleanlab_codex import Project
from openai import OpenAI
import time
import uuid
from openai.types.chat import ChatCompletion, ChatCompletionMessage
import json
from cleanlab_tlm.utils.chat import form_response_string_chat_completions_api
import pandas as pd
from copy import deepcopy
Example AI App: Bank Loan Customer Support
As an example use-case, let’s consider customer support AI for bank loans where the underlying Knowledge Base contains information on loans like the following:
**Knowledge Base Article: Application Review Process**
- Once a customer submits their application, it enters the **Review Stage**.
- **Review Stage Timeline:** Typically 3–5 business days.
- **What Happens During Review:**
- Verification of identity and personal details
- Credit report evaluation
- Fraud checks and risk assessment
The details of this AI app are not important for this tutorial. What is important is that this RAG app generates a response based on a set of provided tools, user query, a retrieved context, and a prior conversation history, which are all made available for evaluation.
For simplicity, our context and tool responses are hardcoded below. You should replace these with the outputs of your AI system, noting that Cleanlab can detect issues in these outputs in real-time.
from datetime import date, timedelta
CONTEXT = "Knowledge Base Article: Application Review Process\nOnce a customer submits their application, it enters the Review Stage.\nReview Stage Timeline: Typically 3–5 business days.\nWhat Happens During Review:\n- Verification of identity and personal details\n- Credit report evaluation\n- Fraud checks and risk assessment"
def get_application_status():
"""A tool that simulates fetching the application status for a customer.
**Note:** This tool returns a hardcoded *realistic* application status for demonstration purposes."""
return {
"status": "RATE_ACCEPTED",
"bank_accounts": [
{"is_verified": True, "added_via": "PLAID"}
],
}
def get_payment_schedule():
"""A tool that simulates fetching a payment schedule for a customer.
**Note:** This tool returns a hardcoded *unrealistic* payment schedule for demonstration purposes."""
return {
"currency": "USD",
"payments": [
{
"due_date": str(date.today() + timedelta(days=30)),
"amount_due": 350000000000000.00,
"status": "UPCOMING"
},
{
"due_date": str(date.today() + timedelta(days=60)),
"amount_due": 350000000000000.00,
"status": "UPCOMING"
}
],
"next_payment_due": str(date.today() + timedelta(days=30))
}
In practice, your AI system should already have functions to process tool calls, retrieve context, generate responses, and build a messages object to prompt the LLM with.
For this tutorial, we’ll simulate these functions using the above fields as well as define a simple fallback_response, system_prompt, and prompt_template.
Optional: Toy methods you should replace with existing methods from your AI system
client = OpenAI()
SYSTEM_PROMPT = "You are a customer service agent. Be polite and concise in your responses."
FALLBACK_RESPONSE = "I'm sorry, but I need to direct you to our customer service team for assistance with this inquiry. Please reach out to example_lenders@money.com for help."
PROMPT_TEMPLATE = """Answer the following customer question.
Customer Question: {question}
"""
CONVERSATION_HISTORY = []
mock_tools = [
{
"type": "function",
"function": {
"name": "get_application_status",
"description": "Returns the current loan application status.",
"parameters": {
"type": "object",
"properties": {},
"required": []
}
}
},
{
"type": "function",
"function": {
"name": "get_payment_schedule",
"description": "Retrieves the upcoming payment schedule for the active loan application.",
"parameters": {
"type": "object",
"properties": {}
}
}
},
]
#### AI helper methods
def rag_form_prompt(conversation_history, user_query=None, context=None):
"""Form a prompt for your LLM response-generation step (from the user query, retrieved context, conversation history, system instructions, etc). We represent the `prompt` in OpenAI's `messages` format, which matches the input to Cleanlab's `validate()` method.
**Note:** In `messages`, it is recommended to inject retrieved context into the system prompt rather than each user message.
"""
system_message = f"System message: {SYSTEM_PROMPT}\n\nContext: {context}\n\n"
messages = [
{"role": "system", "content": system_message},
*conversation_history, # Include previous messages
]
if user_query:
user_message = PROMPT_TEMPLATE.format(context=context, question=user_query)
messages.append({"role": "user", "content": user_message})
return messages
def rag_retreive_context(query):
"""Retrieve relevant context for the given query. In practice, this would involve querying a vector database or similar system."""
# For this tutorial, we return the hardcoded context
return CONTEXT
#### Tool calling helper methods
mock_tool_registry = {
"get_application_status": get_application_status,
"get_payment_schedule": get_payment_schedule,
}
def mock_tool_handler(tool_name, arguments):
if tool_name in mock_tool_registry:
return json.dumps(mock_tool_registry[tool_name]())
return json.dumps({"error": "Unknown tool"})
Optional: Cleanlab helper methods for validation and managing conversation history
def get_final_response_with_cleanlab(results, initial_response: ChatCompletion, FALLBACK_RESPONSE: str) -> ChatCompletion:
"""
Extracts the final response from the initial response and validation results using the following logic:
- If the expert answer is provided and the query was escalated to an SME, return that.
- If a guardrail was triggered, return the fallback response.
- Otherwise, return the initial response from your own AI system.
Returns response in ChatCompletion as the initial response.
"""
def make_cleanlab_response_into_minimal_chatcompletion(
content: str,
) -> ChatCompletion:
"""
Create the smallest valid ChatCompletion object per schema with content.
Args:
content: The text to set as the message content.
Returns:
ChatCompletion: Minimal valid ChatCompletion object.
"""
return ChatCompletion(
id=f"chatcmpl-{uuid.uuid4().hex[:8]}",
object="chat.completion",
created=int(time.time()),
model="cleanlab",
choices=[
{
"index": 0,
"finish_reason": "stop",
"message": ChatCompletionMessage(
role="assistant",
content=content,
),
}
],
)
if results.expert_answer and results.escalated_to_sme:
return make_cleanlab_response_into_minimal_chatcompletion(
results.expert_answer
)
elif results.should_guardrail:
return make_cleanlab_response_into_minimal_chatcompletion(
FALLBACK_RESPONSE
)
else:
return initial_response
from openai.types.chat import ChatCompletionMessage
def clean_conversation_history(conversation):
"""Removes bad tool calls in the current chat turn if final assistant has no tool calls."""
if len(conversation) == 0:
return conversation
# Find start of current turn (last user message)
start_index = next(
i for i in range(len(conversation) - 1, -1, -1)
if (isinstance(conversation[i], ChatCompletionMessage) and conversation[i].role == "user") or (isinstance(conversation[i], dict) and conversation[i].get("role") == "user")
)
chat_turn = conversation[start_index:]
final_assistant = chat_turn[-1]
# Remove tool calls if final assistant has no tool_calls
if getattr(final_assistant, "tool_calls", None) is None:
skip_tool_ids = {tc.id for m in chat_turn if getattr(m, "tool_calls", None)
for tc in getattr(m, "tool_calls", [])}
# Replace slice in place
conversation[start_index:] = [
m for m in chat_turn if not (
(getattr(m, "tool_calls", None) and any(tc.id in skip_tool_ids for tc in m.tool_calls)) or
(isinstance(m, dict) and m.get("role") == "tool" and m.get("tool_call_id") in skip_tool_ids)
)
]
Create Cleanlab Project
To later use the Cleanlab AI Platform, we must first create a Project. Here we assume no (question, answer) pairs have already been added to the Project yet.
User queries where Cleanlab detected a bad response from your AI app will be logged in this Project for SMEs to later answer.
from cleanlab_codex.client import Client
codex_client = Client()
# Create a project
project = codex_client.create_project(
name="Mortgage lending AI Chatbot (with tools)",
description="Customer facing chatbot for a mortgage lending company.",
)
Run detection and remediation
Now that our Project is configured, we can use the Project.validate() method to detect bad responses from our AI app for each chat turn.
import uuid
# This is used to show consecutive messages from the same conversation in the Project's UI
# but it is not used in the code logic.
thread_id = str(uuid.uuid4())
Applying the Project.validate() method to any AI app is straightfoward. Here we showcase this with a toy AI app built with OpenAI.
def run_rag_with_cleanlab(
user_query: str,
context: str,
conversation_history: list[ChatCompletionMessage],
thread_id: str = None,
) -> ChatCompletion:
"""Validate AI response using Cleanlab's `Project.validate()` method.
Args:
user_query: The user's question.
context: The context retrieved for the query.
conversation_history: The history of the conversation as a list of ChatCompletionMessage objects.
thread_id: Optional thread ID for the conversation.
Returns:
List[ChatCompletion]: Conversation history after processing the user query and validation.
"""
conversation_history_turn = deepcopy(conversation_history)
messages = rag_form_prompt(conversation_history_turn, user_query, context)
conversation_history_turn.append({"role": "user", "content": user_query})
print(f'---User Question---\n{user_query}')
while True:
initial_response = client.chat.completions.create(
model="gpt-4.1",
messages=messages,
tools=mock_tools,
)
### New code to add for Cleanlab API ###
print(f'---Original LLM Response---\n{form_response_string_chat_completions_api(initial_response.choices[0].message)}')
validation_result = project.validate(
response=initial_response,
query=user_query,
context=context,
messages=messages,
tools=mock_tools,
metadata={"thread_id": thread_id}, # Add thread id to track conversation in Project's UI
)
print(f"---Cleanlab Validation---")
print(f"Escalated to SME: {validation_result.escalated_to_sme}")
print(f"Should Guardrail: {validation_result.should_guardrail}")
print(f"Expert Answer Available: {bool(validation_result.expert_answer)}")
response = get_final_response_with_cleanlab(validation_result, initial_response, FALLBACK_RESPONSE)
print(f'---Final LLM Response (after Cleanlab validation)---\n{form_response_string_chat_completions_api(response.choices[0].message)}')
### End of new code to add for Cleanlab API ###
conversation_history_turn.append(response.choices[0].message)
if not response.choices[0].message.tool_calls:
if response != initial_response: # If Cleanlab validation stepped in to change the response, remove bad tool calls from history
clean_conversation_history(conversation_history_turn)
break
else:
tools_for_print = []
for tool_call in response.choices[0].message.tool_calls:
args = json.loads(tool_call.function.arguments)
tool_response = mock_tool_handler(
tool_call.function.name,
tool_call.function.arguments
)
tool_dict = {
"role": "tool",
"tool_call_id": tool_call.id,
"content": str(tool_response),
}
conversation_history_turn.append(tool_dict)
tools_for_print.append(tool_dict)
# Update the messages with the new conversation history
print(f'---Tool Responses---\n{tools_for_print}')
messages = rag_form_prompt(conversation_history_turn, None, None)
print('-'*40)
return conversation_history_turn
Chat Turn 1: “What’s the status of my application?”
This turn requires a single tool call to answer user query
Note: The validation_result object below returned by Project.validate() contains all sorts of other useful information. See more details about it here.
user_query1 = "What's the status of my application?"
context1 = rag_retreive_context(user_query1)
CONVERSATION_HISTORY = run_rag_with_cleanlab(
user_query1,
context1,
CONVERSATION_HISTORY,
thread_id=thread_id,
)
Chat Turn 2: “what is my payment schedule?”
This turn also requires a single tool call to answer user query, however, the get_payment_schedule() tool is intentionally defined to have a inaccurate or unrealistic output.
Cleanlab’s validation software steps in and prevents such an output from being returned to the user.
user_query2 = "what is my payment schedule?"
context2 = rag_retreive_context(user_query2)
CONVERSATION_HISTORY = run_rag_with_cleanlab(
user_query2,
context2,
CONVERSATION_HISTORY,
thread_id=thread_id,
)
Chat Turn 3: “how long does it take to review an application?”
This turn does not require any tool calling.
user_query3 = "how long does it take to review an application?"
context3 = rag_retreive_context(user_query3)
CONVERSATION_HISTORY = run_rag_with_cleanlab(
user_query3,
context3,
CONVERSATION_HISTORY,
thread_id=thread_id,
)
View entire conversation history
Notice how the untrustworthy Initial LLM response to the user query “what is my payment schedule?” is guardrailed by Cleanlab and the fallback response is safely returned.
for c in CONVERSATION_HISTORY:
role = c["role"] if isinstance(c, dict) and "role" in c else c.role
print(f"{role.upper()}: {form_response_string_chat_completions_api(c)}")
Next Steps
Now that Cleanlab is integrated with your Tool Calling AI App, you and SMEs can open the connected Cleanlab Project and answer questions logged there to continuously improve your AI.
This tutorial only demonstrated the basics of using Cleanlab to automatically detect and remediate bad responses from any Tool Calling AI application. Advanced Usage is covered in our Detect and remediate bad responses from conversational RAG applications tutorial. We recommend connecting your Tool-Calling AI Agents to a separate Cleanlab Project from your Q&A / Chat AI Agents.
Cleanlab provides a robust way to evaluate response quality and automatically fetch expert answers when needed. For responses that don’t meet quality thresholds, the connected Cleanlab Project automatically logs the queries for SME review.
Adding Cleanlab only improves your Tool Calling AI app. Once integrated, it automatically identifies problematic responses and either remediates them with expert answers or logs them for review. Using a simple web interface, SMEs at your company can answer the highest priority questions in the Cleanab Project. As soon as an answer is entered in the Project, your AI app will be able to properly handle all similar questions encountered in the future.
Need help, more capabilities, or other deployment options?
Check the FAQ or email us at: support@cleanlab.ai