Detect and remediate bad responses from any RAG application

This tutorial demonstrates how to automatically improve any RAG application by integrating Cleanlab. The Cleanlab API takes in the AI-generated response from your RAG app, and the same inputs provided to the LLM that generated it: user query, retrieved context, and any parts of the LLM prompt. Cleanlab will automatically detect if your AI response is bad (e.g., untrustworthy, unhelpful, or unsafe). The Cleanlab API returns these real-time evaluation scores which you can use to guardrail your AI. If your AI response is flagged as bad, the Cleanlab API will also return an expert response whenever a similar query has been answered in the connected Cleanlab Project, or otherwise log this query into the Cleanlab Project for SMEs to answer.
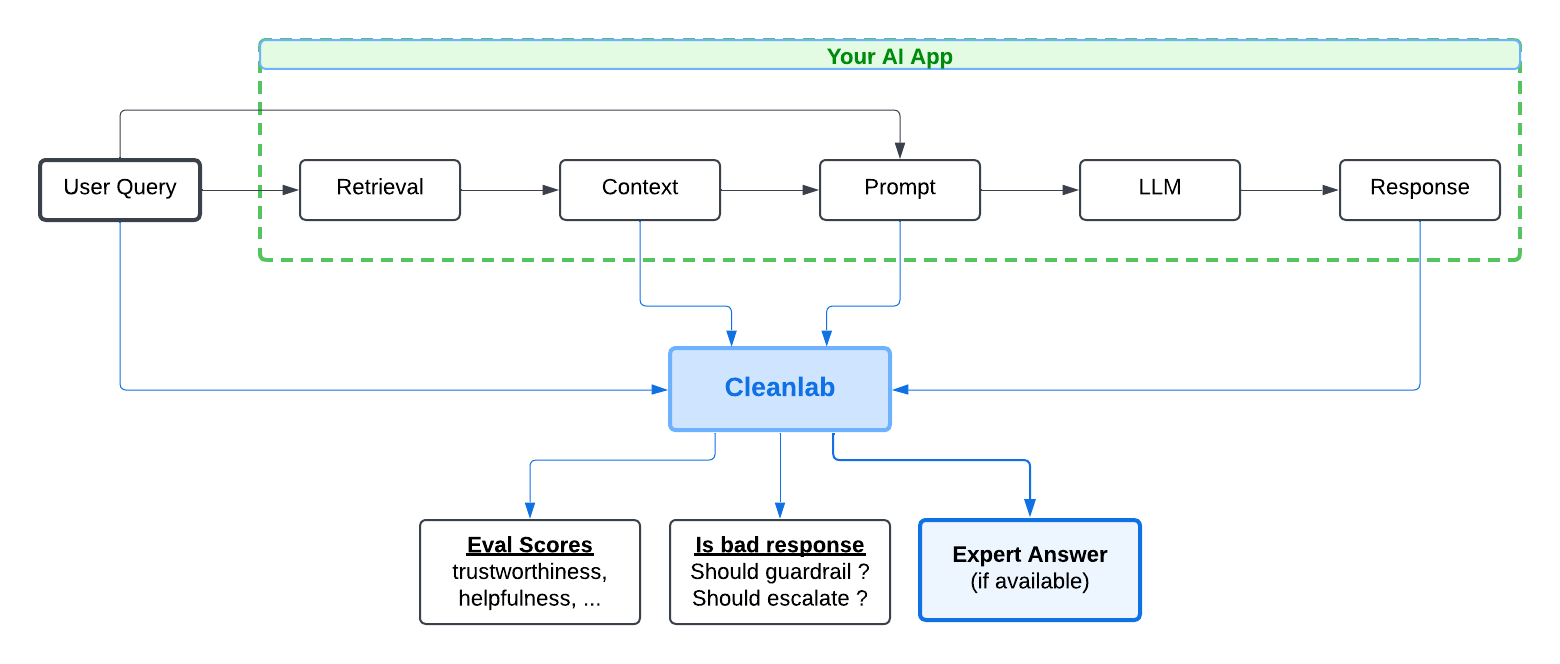
Overview
Here’s all the code needed for using Cleanlab with your RAG system.
from cleanlab_codex import Project
project = Project.from_access_key(access_key)
# Your existing RAG code:
context = rag_retrieve_context(user_query)
messages = rag_form_prompt(user_query, context)
response = rag_generate_response(messages)
# Detect bad responses and remediate with Cleanlab
results = project.validate(messages=messages, query=user_query, context=context, response=response)
final_response = (
results.expert_answer if results.expert_answer # and results.escalated_to_sme (Note: uncomment this to utilize Cleanlab expert-answers solely as a backup)
else fallback_response if results.should_guardrail
else response
)
Note: This tutorial is for Single-turn Q&A Apps. If you have a Multi-turn Chat app, a similar workflow is covered in the Detect and Remediate bad responses in Conversational Apps tutorial.
Setup
This tutorial requires a Cleanlab API key. Get one here.
%pip install --upgrade cleanlab-codex pandas
# Set your Codex API key
import os
os.environ["CODEX_API_KEY"] = "<API key>" # Get your free API key from: https://codex.cleanlab.ai/account
# Import libraries
import pandas as pd
from cleanlab_codex import Project
Example RAG App: Product Customer Support
Consider a customer support / e-commerce RAG use-case where the Knowledge Base contains product listings like the following:
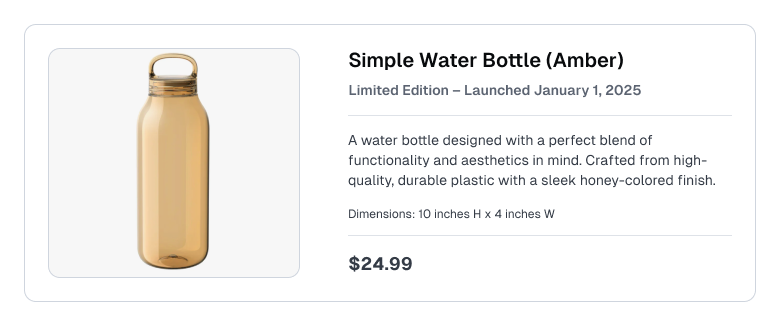
Here, the inner workings of the RAG app are not important for this tutorial. What is important is that the RAG app generates a response based on a user query and a context, which are all made available for evaluation.
For simplicity, our context is hardcoded as the product listing below. You should replace these with the outputs of your RAG system, noting that Cleanlab can detect issues in these outputs in real-time.
product_listing = """Simple Water Bottle - Amber (limited edition launched Jan 1st 2025)
A water bottle designed with a perfect blend of functionality and aesthetics in mind. Crafted from high-quality, durable plastic with a sleek honey-colored finish.
Price: $24.99
Dimensions: 10 inches height x 4 inches width"""
Optional: Example queries and retrieved context + generated response from RAG system dataframe
data = [
{
"query": "How much water can the Simple Water Bottle hold?",
"context": product_listing,
"response": "The Simple Water Bottle can hold 16 oz of Water"
},
{
"query": "How can I order the Simple Water Bottle in bulk?",
"context": product_listing,
"response": "Based on the available information, I cannot provide a complete answer to this question."
},
{
"query": "How much does the Simple Water Bottle cost?",
"context": product_listing,
"response": "The Simple Water Bottle costs $10"
},
]
df = pd.DataFrame(data)
df
In practice, your RAG system should already have functions to retrieve context, generate responses, and build a messages object to prompt the LLM with. For this tutorial, we’ll simulate these functions using the above fields as well as define a simple fallback_response and prompt_template.
Optional: Toy RAG methods you should replace with existing methods from your RAG system
fallback_response = "I'm sorry, I couldn't find an answer for that — can I help with something else?"
prompt_template = """You are a customer service agent. Your task is to answer the following customer questions based on the product listing.
Product Listing: {context}
Customer Question: {query}
"""
def rag_retrieve_context(query):
"""Simulate retrieval from a knowledge base"""
# In a real system, this would search the knowledge base
for item in data:
if item["query"] == query:
return item["context"]
return ""
def rag_generate_response(messages):
"""Simulate LLM response generation"""
# In a real system, this would call an LLM
user_prompt = messages[0]["content"]
query = user_prompt.split("Customer Question: ")[1].split("\n")[0]
for item in data:
if item["query"] == query:
return item["response"]
# Return a fallback response if the LLM is unable to answer the question
return "Based on the available information, I cannot provide a complete answer to this question."
def rag_form_prompt(query, context):
"""
Form a prompt for your LLM response-generation step (from the user query, retrieved context, system instructions, etc). We represent the `prompt` using OpenAI's `messages` format, which matches the input to Cleanlab's `validate()` method.
"""
user_prompt = prompt_template.format(query=query, context=context)
messages = [{
"role": "user",
"content": user_prompt,
}]
return messages
Create Cleanlab Project
To later use the Cleanlab AI Platform, we must first create a Project. Here we assume some (question, answer) pairs have already been added to the Cleanlab Project.
Our existing Cleanlab Project contains the following entries:

User queries where Cleanlab detected a bad response from your RAG app will be logged in this Project for SMEs to later answer.
Running detection and remediation
Now that our Cleanlab Project is configured, we can use the Project.validate() method to detect bad responses from our RAG application. A single call runs many real-time Evals to score each AI response, and when scores fall below certain thresholds, the response is flagged for guardrailing or for SME review.
When your AI response is flagged for SME review, the Project.validate() call will simultaneously query Cleanlab for an expert answer that can remediate your bad AI response. If no suitable expert answer is found, this query will be logged as Unaddressed in the Cleanlab Project for SMEs to answer
When a response is flagged for guardrailing, the should_guardrail return value will be marked as True. You can choose to return a safer fallback response in place of the original AI response, or escalate to a human employee rather than letting your AI handle this case.
Here’s some logic to determine the final_response to return to your user.
final_response = (
results.expert_answer if results.expert_answer and results.escalated_to_sme # you can optionally omit the 2nd part of the AND statement to always use expert answers when available
else fallback_response if results.should_guardrail
else initial_response
)
Let’s initialize the Project using our access key:
access_key = "<YOUR-PROJECT-ACCESS-KEY>" # Obtain from your Project's settings page: https://codex.cleanlab.ai/
project = Project.from_access_key(access_key)
Applying the validate() method to a RAG system is straightfoward. Here we do this using a helper function that applies the Validator to one row from our example dataframe.
def df_row_validation(df, row_index, project, verbosity=0):
"""
Detect and remediate bad responses in a specific row from the dataframe
Args:
df (DataFrame): The dataframe containing the query, context, and response to validate.
row_index (int): The index of the row in the dataframe to validate.
project (Project): The Codex Project object used to detect bad responses and remediate them. verbosity (int): Whether to print verbose output. Defaults to 0.
At verbosity level 0, only the query and final response are printed.
At verbosity level 1, the initial RAG response and the validation results are printed as well.
At verbosity level 2, the retrieved context is also printed.
"""
# 1. Get user query
user_query = df.iloc[row_index]["query"]
print(f"Query: {user_query}\n")
# 2. Standard RAG pipeline
# a. retrieve the context
retrieved_context = rag_retrieve_context(user_query)
if verbosity >= 2:
print(f"Retrieved context:\n{retrieved_context}\n")
# b. build prompt for RAG system
messages = rag_form_prompt(
query=user_query,
context=retrieved_context,
)
# c. simulate LLM response generation
initial_response = rag_generate_response(messages)
if verbosity >= 1:
print(f"Initial RAG response: {initial_response}\n")
# 3. Detect and remediate bad responses
results = project.validate(
messages=messages,
response=initial_response,
query=user_query,
context=retrieved_context,
)
# 4. Get the final response:
# - Use the fallback_response if the response was flagged as requiring guardrails
# - Use an expert answer if available
# - Otherwise, use the initial response
final_response = (
results.expert_answer if results.expert_answer # and results.escalated_to_sme (Note: uncomment this to utilize Cleanlab expert-answers solely as a backup)
else fallback_response if results.should_guardrail
else initial_response
)
print(f"Final Response: {final_response}\n")
# For tutorial purposes, show validation results
if verbosity >= 1:
print("Validation Results:")
for key, value in results.model_dump().items():
print(f" {key}: {value}")
Let’s validate the RAG response to our first example query. The final dictionary printed by our helper functions are the results of Project.validate(), which we’ll break down below.
df_row_validation(df, 0, project, verbosity=1)
The Project.validate() method returns a comprehensive dictionary containing multiple evaluation metrics and remediation options. Let’s examine the key components of these results:
Core Validation Results
-
expert_answer(String | None)- Contains the remediation response retrieved from the Cleanlab Project.
- Returns
Nonein one scenario:- When no suitable expert answer exists in the Cleanlab Project for similar queries.
- Returns a string containing the expert-provided answer when:
- A semantically similar query exists in the Cleanlab Project with an expert answer.
-
escalated_to_sme(Boolean)- Will be
Trueif any eval fails withshould_escalate=True, meaning the score for that specific eval falls below a configured threshold.
- Will be
-
should_guardrail(Boolean)- Will be
Truewhen any configured guardrails are triggered withshould_guardrail=True, meaning the score for that specific guardrail falls below a configured threshold. - Does not trigger checking Cleanlab for an expert answer and flagging the query for review.
- Will be
Evaluation Metrics
Each evaluation metric has a triggered_guardrail and triggered_escalation boolean flag that indicates whether the metric’s score falls below its configured threshold, which determines if a response needs remediation or guardrailing.
By default, the Project.validate() method uses the following metrics as Evaluations for escalation:
trustworthiness: overall confidence that your RAG system’s response is correct.response_helpfulness: evaluates whether the response attempts to helpfully address the user query vs. abstaining or saying ‘I don’t know’.
By default, the Project.validate() method uses the following metrics as Guardrails:
trustworthiness: overall confidence that your RAG system’s response is correct (used for guardrailing and escalation).
You can modify these metrics or add your own by defining a custom list of Evaluations and/or Guardrails for a Project in the Cleanlab Web App.
Let’s validate another example from our RAG system. For this example, the response is flagged as bad, but no expert answer is available in the Cleanlab Project. The corresponding query will be logged there for SMEs to answer.
df_row_validation(df, 1, project, verbosity=1)
The RAG system is unable to answer this question because there is no relevant information in the retrieved context, nor has a similar question been answered in the Cleanlab Project (see the contents of the Cleanlab Project above).
Cleanlab automatically recognizes this question could not be answered and logs it into the Project where it awaits an answer from a SME (notice that escalated_to_sme is True).
Navigate to your Cleanlab Project in the Web App where you (or a SME at your company) can enter the desired answer for this query.
As soon as an answer is provided in Cleanlab, our RAG system will be able to answer all similar questions going forward (as seen for the previous query).
Advanced Usage
You can configure many aspects of the bad response detection like what score thresholds to use inside the Cleanlab Web App.
Response Quality Thresholds
Thresholds determine when a response needs intervention:
-
A metric (trustworthiness, pii_detection, etc.) can be defined as an Evaluation, Guardrail , or both.
-
Each metric has its own threshold (0-1) and a defined threshold direction (below/above).
-
If any Evaluation’s score violates the threshold condition, the response is escalated to an SME and an expert answer is attempted to be returned.
-
If any Guardrail’s score violates the threshold condition,
Project.validate()returns with theshould_guardrail=Trueflag and no other action is taken. -
Example: With Evaluation metric Hallucination (trustworthiness) threshold set to “below 0.85”
- Score 0.80 -> Escalated to an SME
- Score 0.90 -> Passes validation
Setting thresholds affects your validation strategy:
- Higher thresholds (e.g. 0.9) = Stricter validation
- More responses marked as “should_escalate”
- More queries logged for SMEs to answer
- Better response quality but higher SME workload
- Lower thresholds (e.g. 0.7) = More lenient validation
- Fewer responses marked as “should_escalate”
- Fewer queries logged for SMEs to answer
- Lower SME workload, but may allow lower quality responses from your RAG app to be returned unremediated.
Configure Custom Evaluations and Guardrails
You can configure these directly in the Cleanlab Web UI. For a detailed walkthrough, see the Adding custom guardrails section of our other tutorial.
Logging Additional Information
When project.validate() returns results indicating a response should be escalated to an SME, it logs the query into your Cleanlab Project. By default, this log automatically includes the evaluation scores (like trustworthiness), the context and LLM response.
You can include additional information that would be helpful for Subject Matter Experts (SMEs) when they review the logged queries in the Cleanlab Project later.
To add any extra information, simply pass in any key-value pairs into the metadata parameter in the validate() method. For example, you can add the location the Query came from like so:
metadata = {"location": "USA"}
results = project.validate(
messages=messages,
response=response,
query=query,
context=context,
metadata=metadata,
)
Run the example below to add an entry into Cleanlab that contains this additional metadata.
def df_row_log_metadata(df, row_index, project, verbosity=0):
"""
Detect and remediate bad responses in a specific row from the dataframe
Args:
df (DataFrame): The dataframe containing the query, context, and response to validate.
row_index (int): The index of the row in the dataframe to validate.
project (Project): The Codex Project object used to detect bad responses and remediate them.
verbosity (int): Whether to print verbose output. Defaults to 0.
At verbosity level 0, only the query and final response are printed.
At verbosity level 1, the initial RAG response and the validation results are printed as well.
At verbosity level 2, the retrieved context is also printed.
"""
# 1. Get user query
user_query = df.iloc[row_index]["query"]
print(f"Query: {user_query}\n")
# 2. Standard RAG pipeline
# a. retrieve the context
retrieved_context = rag_retrieve_context(user_query)
if verbosity >= 2:
print(f"Retrieved context:\n{retrieved_context}\n")
# b. build prompt for RAG system
messages = rag_form_prompt(
query=user_query,
context=retrieved_context,
)
# c. simulate LLM response generation
initial_response = rag_generate_response(messages)
if verbosity >= 1:
print(f"Initial RAG response: {initial_response}\n")
# 3. Detect and remediate bad responses
results = project.validate(
messages=messages,
response=initial_response,
query=user_query,
context=retrieved_context,
metadata={"location": "USA"},
)
# 4. Get the final response:
# - Use the fallback_response if the response was flagged as requiring guardrails
# - Use an expert answer if available
# - Otherwise, use the initial response
final_response = (
results.expert_answer if results.expert_answer # and results.escalated_to_sme (Note: uncomment this to utilize Cleanlab expert-answers solely as a backup)
else fallback_response if results.should_guardrail
else initial_response
)
print(f"Final Response: {final_response}\n")
# For tutorial purposes, show validation results
if verbosity >= 1:
print("Validation Results:")
for key, value in results.model_dump().items():
print(f" {key}: {value}")
df_row_log_metadata(df, 2, project, verbosity=1)
Next Steps
Now that Cleanlab is integrated with your Single-turn Q&A App, you and SMEs can open the Cleanlab Project and answer questions logged there to continuously improve your AI.
This tutorial demonstrated how to use Cleanlab to automatically detect and remediate bad responses in any Single-turn Q&A application. Cleanlab provides a robust way to evaluate response quality and automatically fetch expert answers when needed. For responses that don’t meet quality thresholds, Cleanlab automatically logs the queries for SME review.
Note: Automatic detection and remediation of bad responses for a Multi-turn Conversational Chat app is covered in the Detect and Remediate bad responses in Conversational Apps tutorial.
Adding Cleanlab only improves your RAG app. Once integrated, it automatically identifies problematic responses and either remediates them with expert answers or logs them for review. Using a simple web interface, SMEs at your company can answer the highest priority questions in the Cleanlab Project. As soon as an answer is entered in Cleanlab, your RAG app will be able to properly handle all similar questions encountered in the future.
Cleanlab is the fastest way for nontechnical SMEs to directly improve your RAG system. As the Developer, you simply integrate Cleanlab once, and from then on, SMEs can continuously improve how your system handles common user queries without needing your help.
Need help, more capabilities, or other deployment options?
Check the FAQ or email us at: support@cleanlab.ai