Adding Tool calls to RAG

This tutorial covers the basics of building a RAG app that supports tool calls. Here we demonstrate how to build the specific RAG app used in our Integrate Codex as-a-Tool into any RAG framework tutorial, a minimal example just using OpenAI LLMs. Remember that Codex works with any RAG app, you can easily translate these ideas to more complex RAG pipelines and other LLMs.
Here’s a typical architecture for RAG apps with tool calling:
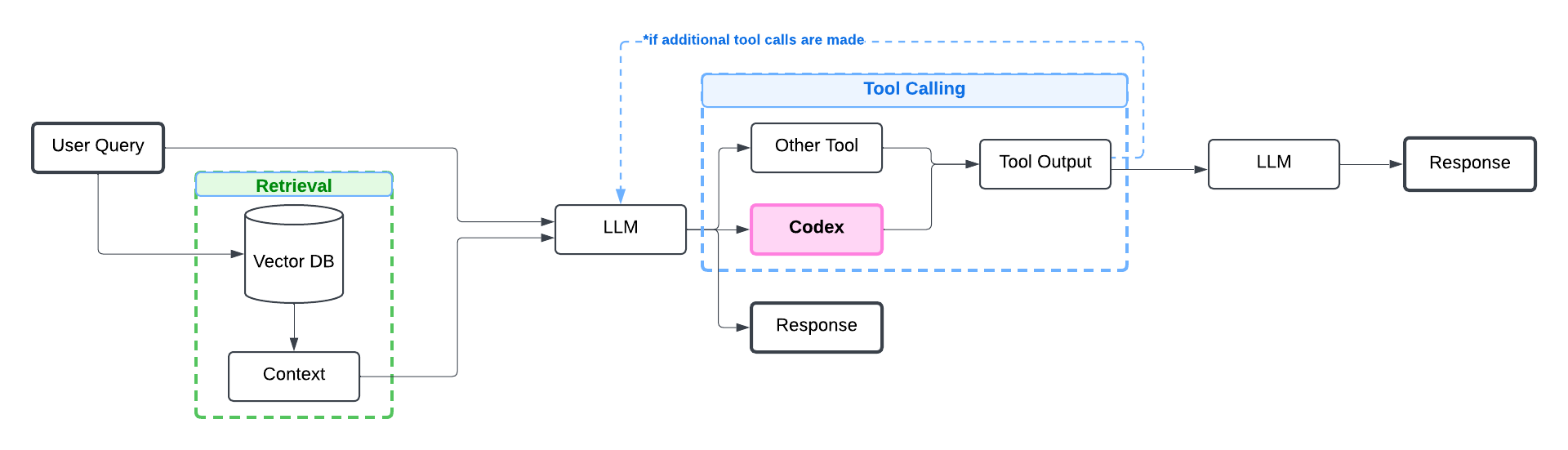
Let’s first install and setup the OpenAI client library.
%pip install --upgrade openai # we used package-version 1.63.2
from openai import OpenAI
import json
import os
os.environ["OPENAI_API_KEY"] = "<YOUR-KEY-HERE>" # Replace with your OpenAI API key
model = "gpt-4o" # which LLM to use
client = OpenAI()
Example RAG App: Product Customer Support
Consider a customer support / e-commerce RAG use-case where the Knowledge Base contains product listings like the following:
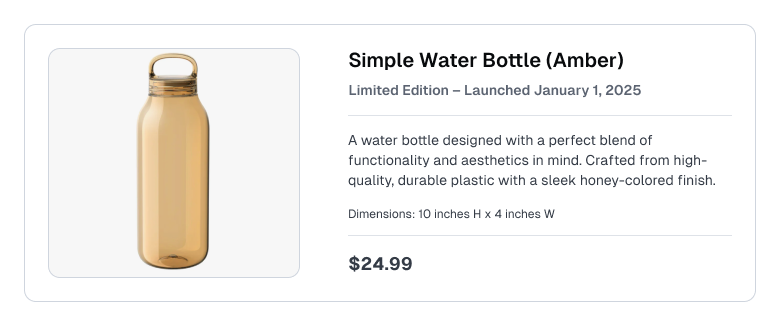
To keep our example minimal, we mock the retrieval step (you can easily replace our mock retrieval with actual search over a complex Knowledge Base or Vector Database). In our mock retrieval, the same context (product information) will always be returned for every user query. After retrieval, the next step in RAG is to combine the retrieved context with the user query into a LLM prompt that is used to generate a response.
Optional: Helper methods for a toy RAG application
def retrieve_context(user_question: str) -> str:
"""Mock retrieval function returns same context for any user_question. Replace with actual retrieval step in your RAG system."""
contexts = """Simple Water Bottle - Amber (limited edition launched Jan 1st 2025)
A water bottle designed with a perfect blend of functionality and aesthetics in mind. Crafted from high-quality, durable plastic with a sleek honey-colored finish.
Price: $24.99 \nDimensions: 10 inches height x 4 inches width"""
return contexts
def form_prompt(user_question: str, retrieved_context: str) -> str:
question_with_context = f"Context:\n{retrieved_context}\n\nUser Question:\n{user_question}"
indented_question_with_context = "\n".join(f" {line}" for line in question_with_context.splitlines()) # line is just formatting the final prompt for readability in the tutorial
return indented_question_with_context
Log tool calls in the message history
Conversational AI applications rely on message history to track a dialogue between the user and AI assistant. When the AI can choose to call tools, we must update the message history to reflect when a tool was called and what it returned. The required formats for the message history differ between: a regular LLM response, a tool call request from the LLM, and a response from the tool.
Optional: Helper methods to handle message history with tool calls
# Functions for appropriately formatting model responses, tool calls, and tool outputs for the message history.
# The format varies by LLM provider. If you are not using OpenAI, adjust these functions for your required format.
def simulate_response_as_message(response: str) -> list[dict]:
"""Commits the response to a conversation history to return back to the model."""
return {"role": "assistant", "content": response}
def simulate_tool_call_as_message(tool_call_id: str, function_name: str, function_arguments: str) -> dict:
"""Commits the tool call to a conversation history to return back to the model."""
tool_call_message = {
"role": "assistant",
"tool_calls": [{
"id": tool_call_id,
"type": "function",
"function": {
"arguments": function_arguments,
"name": function_name
}
}]}
return tool_call_message
def simulate_tool_call_response_as_message(tool_call_id: str, function_response: str) -> dict:
"""Commits the result of the function call to a conversation history to return back to the model."""
function_call_result_message = {
"role": "tool",
"content": function_response,
"tool_call_id": tool_call_id,
}
return function_call_result_message
Run LLM and tool calls
In this example, our LLM will use token streaming to produce its responses in real-time. When prompting the LLM, we provide a list of tools that the LLM can optionally choose to call instead of generating a response. If the LLM chooses to use a tool instead of returning a response right away, then you need to execute the function corresponding to this tool yourself using the argument values generated by the LLM. After calling the function, give the return value to the LLM in a new message. The LLM can then decide how to respond to the user, or may choose to call yet another tool.
All of this is handled for any tool in the below helper methods.
Optional: Helper methods to generate responses and call tools
# If you are not using OpenAI LLMs, adjust these functions for your required format for tool calling and prompting.
def stream_response(client, messages: list[dict], model: str, tools: list[dict]) -> str:
"""Processes a streaming response dynamically handling any tool.
Params:
messages: message history list in openai format
model: model name
tools: list of tools model can call
Returns:
response: final response in openai format
"""
response_stream = client.chat.completions.create(
model=model,
messages=messages,
stream=True,
tools=tools,
parallel_tool_calls=False, # prevents OpenAI from making multiple tool calls in a single response
)
collected_messages = []
final_tool_calls = {}
for chunk in response_stream:
if chunk.choices[0].delta.content:
collected_messages.append(chunk.choices[0].delta.content)
for tool_call in chunk.choices[0].delta.tool_calls or []:
index = tool_call.index
if index not in final_tool_calls:
final_tool_calls[index] = tool_call
final_tool_calls[index].function.arguments += tool_call.function.arguments
if chunk.choices[0].finish_reason == "tool_calls":
for tool_call in final_tool_calls.values():
function_response = _handle_any_tool_call_for_stream_response(tool_call.function.name, json.loads(tool_call.function.arguments))
print(f'[internal log] Called {tool_call.function.name} tool, with arguments: {tool_call.function.arguments}')
print(f'[internal log] Tool response: {str(function_response)}')
tool_call_response_message = simulate_tool_call_response_as_message(tool_call.id, function_response)
# If the tool call resulted in an error, return the message instead of continuing the conversation
if "error" in tool_call_response_message["content"]:
return tool_call_response_message
response = [
simulate_tool_call_as_message(tool_call.id, tool_call.function.name, tool_call.function.arguments),
tool_call_response_message,
]
# If needed, extend messages and re-call the stream response
messages.extend(response)
response = stream_response(client=client, messages=messages, model=model, tools=tools) # This recursive call handles the case when a tool calls another tool until all tools are resolved and a final response is returned
else:
collected_messages = [m for m in collected_messages if m is not None]
full_str_response = "".join(collected_messages)
response = simulate_response_as_message(full_str_response)
return response
def _handle_any_tool_call_for_stream_response(function_name: str, arguments: dict) -> str:
"""Handles any tool dynamically by calling the function by name and passing in collected arguments.
Returns a dictionary of the tool output.
Returns error message if the tool is not found, not callable or called incorrectly.
"""
try:
tool_function = globals().get(function_name) or locals().get(function_name)
if callable(tool_function):
# Dynamically call the tool function with arguments
tool_output = tool_function(**arguments)
return json.dumps(tool_output)
else:
return json.dumps({
"error": f"Tool '{function_name}' not found or not callable.",
"arguments": arguments,
})
except Exception as e:
return json.dumps({
"error": f"Exception in handling tool '{function_name}': {str(e)}",
"arguments": arguments,
})
Define single-turn RAG application (Q&A)
We integrate the above helper methods into a standard RAG app that can respond to any user query, calling tools as the LLM deems necessary.
def rag(client, model: str, user_question: str, system_prompt: str, tools: list[dict]) -> str:
retrieved_context = retrieve_context(user_question)
question_with_context = form_prompt(user_question, retrieved_context)
print(f"[internal log] Invoking LLM text\n{question_with_context}\n\n")
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": question_with_context},
]
response_messages = stream_response(client=client, messages=messages, model=model, tools=tools)
return f"\n[RAG response] {response_messages.get('content')}"
Example Tool: get_todays_date
Let’s define an example tool get_todays_date() that our RAG app can rely on. Here we follow OpenAI’s format for representing the tool, but other LLM providers are similar. We describe the actual function to the LLM in a JSON format, listing the arguments and their properties as well.
from datetime import datetime
def get_todays_date(date_format: str) -> str:
"""A tool that returns today's date in the date format requested."""
datetime_str = datetime.now().strftime(date_format)
return datetime_str
todays_date_tool_json = {
"type": "function",
"function": {
"name": "get_todays_date",
"description": "A tool that returns today's date in the date format requested. Options for date_format parameter are: '%Y-%m-%d', '%d', '%m', '%Y'.",
"parameters": {
"type": "object",
"properties": {
"date_format": {
"type": "string",
"enum": ["%Y-%m-%d", "%d", "%m", "%Y"],
"default": "%Y-%m-%d",
"description": "The date format to return today's date in."
}
},
"required": ["date_format"], # indicates this is a required argument whose value must be specified when calling this tool.
}
}
}
Update our LLM system prompt with tool call instructions
For the best performance, add instructions on when to use the tool into the system prompt that governs your LLM. Below we simply added Step 3. in our list of instructions, which otherwise represent a typical RAG system prompt. In most RAG apps, one instructs the LLM what fallback answer to respond with when it does not know how to answer a user’s query. Such fallback instructions help you reduce hallucinations and more precisely control the AI.
fallback_answer = "Based on the available information, I cannot provide a complete answer to this question."
system_prompt = f"""You are a helpful assistant designed to help users navigate a complex set of documents for question-answering tasks. Answer the user's Question based on the following possibly relevant Context and previous chat history using the tools provided if necessary. Follow these rules in order:
1. NEVER use phrases like "according to the context", "as the context states", etc. Treat the Context as your own knowledge, not something you are referencing.
2. Use only information from the provided Context.
3. Give a clear, short, and accurate Answer. Explain complex terms if needed.
4. If the answer to the question requires today's date, use the following tool: get_todays_date. Return the date in the exact format the tool provides it.
5. If the Context doesn't adequately address the Question or you are unsure how to answer the Question, say: "{fallback_answer}" only, nothing else.
Remember, your purpose is to provide information based on the Context, not to offer original advice.
"""
RAG in action
Let’s run our RAG application over different questions commonly asked by users about the Simple Water Bottle in our example.
Scenario 1: RAG can answer the question without tools
user_question = "How big is the water bottle?"
response = rag(client, model=model, user_question=user_question, system_prompt=system_prompt, tools=[todays_date_tool_json])
print(response)
Here the LLM was able to provide a good answer because the retrieved context contains the necessary information.
Scenario 2: RAG can answer the question using tools
user_question = "Has the limited edition Amber water bottle already launched?"
response = rag(client, model=model, user_question=user_question, system_prompt=system_prompt, tools=[todays_date_tool_json])
print(response)
In this case, the LLM chose to call our get_todays_date tool to obtain information necessary for properly answering the user’s query. Note that a proper answer to this question also requires considering information from the retrieved context as well.
Scenario 3: RAG cannot answer the question
user_question = "Can I return my simple water bottle?"
response = rag(client, model=model, user_question=user_question, system_prompt=system_prompt, tools=[todays_date_tool_json])
print(response)
Note that the Context does not contain information about the return policy, and the get_todays_date tool would not help either.
In this case, we want to return our fallback response to the user.
Next Steps
Adding tool calls to your RAG system expands the capabilities of what your AI can do and the types of questions it can answer.
Once you have a RAG app with tools set up, adding Codex as-a-Tool takes only a few lines of code (regardless what RAG framework you are using). Codex enables your RAG app to answer questions it previously could not (like Scenario 3 above). Learn how via our tutorial: Integrate Codex as-a-Tool into any RAG framework.
Need help? Check the FAQ or email us at: support@cleanlab.ai
Conversational RAG (multi-turn dialogues)
Extending our single-turn RAG function above into a conversational chat application (with tool calling) is easy:
Update the helper method stream_response defined above: add a messages argument that tracks conversation history, and append generated responses to this history.
(Note: to make the code in this section runnable, you’ll have to actually update the above rag() helper methods according to the descriptions here.)
def stream_response(..., messages):
# same code as stream_response() function defined in the above helper method, we only show how to update the final Else clause here
else:
collected_messages = [m for m in collected_messages if m is not None]
full_str_response = "".join(collected_messages)
response = simulate_response_as_message(full_str_response)
messages.append(response)
return messages
Define a global message_history variable to pass into RAG function called at each conversation turn in a dialogue. Each time you start a new dialogue (user interaction), simply reset message_history.
message_history = [
{
"role": "system",
"content": (
system_prompt
),
},
]
For each turn in a conversation, call rag() with message_history. The last message in this history corresponds to the final response for a specific query that you can give the user.
Here’s an example conversation (first update the rag() helper methods above before running this code).
user_query = "What color is the Simple Water Bottle?"
message_history = rag(model=model, user_query=user_query, message_history=message_history, tools=tools)
message_history[-1].get("content") # Print final response to return to user
user_query = "How big is it?"
message_history = rag(model=model, user_query=user_query, message_history=message_history, tools=tools)
message_history[-1].get("content") # Print final response to return to user