RAG With Tool Calls in LlamaIndex

This notebook covers the basics of building a RAG app that supports tool calls. Here we demonstrate how to build the specific RAG app used in our tutorial: Integrate Codex as-a-Tool with LlamaIndex.
Here’s a typical architecture for RAG apps with tool calling:
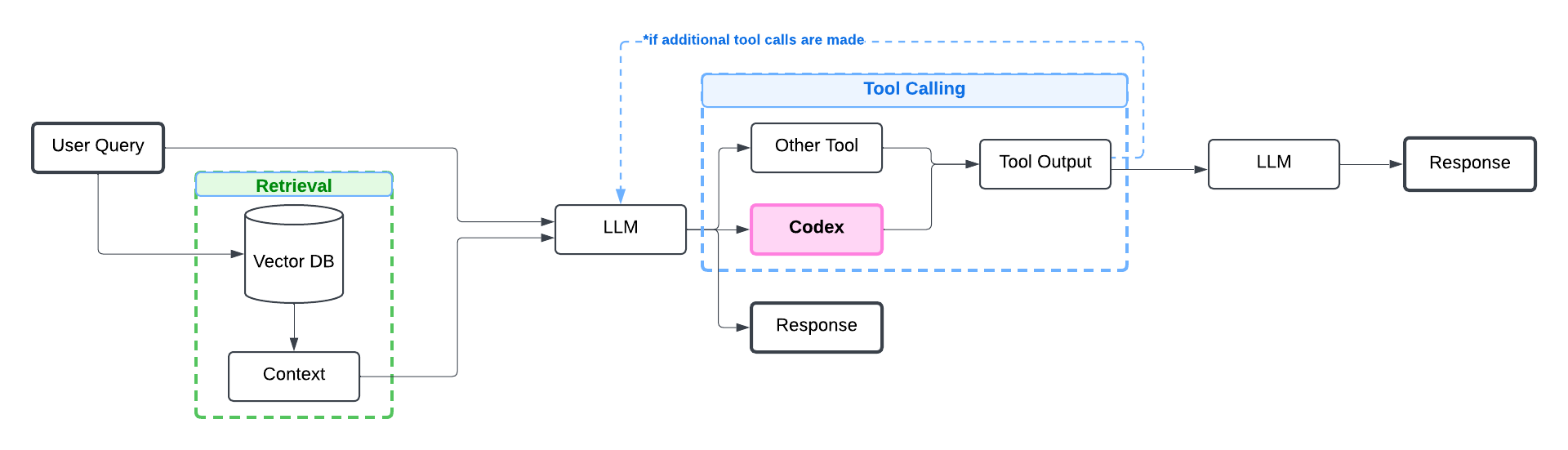
Let’s first install and setup LlamaIndex (this tutorial runs LlamaIndex with OpenAI LLMs, but you can use another LLM instead).
# Install necessary LlamaIndex packages
%pip install --upgrade llama-index llama-index-llms-openai # we used package-versions 0.12.10 0.4.1
import os
os.environ["OPENAI_API_KEY"] = "<YOUR-KEY-HERE>" # Replace with your OpenAI API key
model = "gpt-4o" # Which LLM to use
Example: Customer Service for a New Product
Consider a customer support / e-commerce RAG use-case where the Knowledge Base contains product listings like the following:
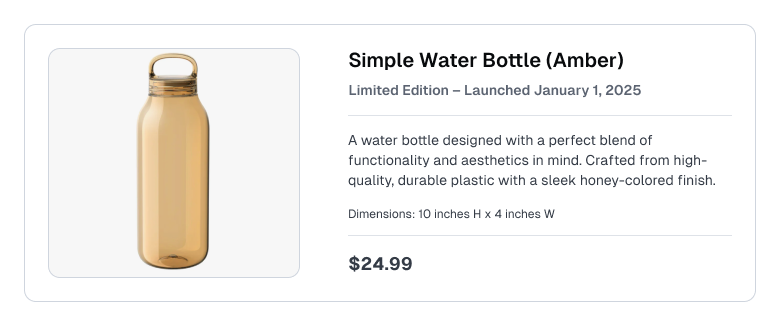
To keep this example minimal, we’ll use a simple in-memory vector store with a two documents. The documents will contain the context (product information) in the image above. Next, we specify functions to load the documents from the vector store, then connect the assistant to the documents.
Optional: Initialize vector store + add documents
from llama_index.llms.openai import OpenAI
from llama_index.core import VectorStoreIndex, Document
# Ingest documents into a vector database, and set up a retriever
documents = [
Document(text="Simple Water Bottle - Amber (limited edition launched Jan 1st 2025) \n\nA water bottle designed with a perfect blend of functionality and aesthetics in mind. Crafted from high-quality, durable plastic with a sleek honey-colored finish."),
Document(text="Price: $24.99 \nDimensions: 10 inches height x 4 inches width"),
]
index = VectorStoreIndex.from_documents(documents) # Set up your own doc-store and vector database here
retriever = index.as_retriever(similarity_top_k=5)
Create Chat App with Tool Calls
We now define a tool-calling RAG app.
Optional: Define RAG app (following the LlamaIndex format)
from llama_index.core.llms import ChatMessage, ChatResponse
from llama_index.core.llms.function_calling import FunctionCallingLLM
from llama_index.core.retrievers import BaseRetriever
from llama_index.core.tools import FunctionTool
class RAGApp:
def __init__(self,
llm: FunctionCallingLLM,
tools: list[FunctionTool],
retriever: BaseRetriever,
messages: list[ChatMessage] | None = None,
):
self.llm = llm
self.tools = tools
self._tools_map = {tool.metadata.name: tool for tool in tools}
self.retriever = retriever
self.chat_history = messages or []
def __call__(self, user_query: str) -> ChatResponse:
"""Process user input: retrieve context to enrich query, get response (possibly using tools), update conversation."""
self.chat_history.append(ChatMessage(role="user", content=user_query))
context = self._retrieve_context(user_query)
query_with_context = self._form_prompt(user_question=user_query, retrieved_context=context)
response = self.handle_response_and_tools(query_with_context)
self.chat_history.append(response.message)
return response
def _form_prompt(self, user_question: str, retrieved_context: str) -> str:
question_with_context = f"Context:\n{retrieved_context}\n\nUser Question:\n{user_question}"
# Below step is just formatting the final prompt for readability in the tutorial
indented_question_with_context = "\n".join(f" {line}" for line in question_with_context.splitlines())
return indented_question_with_context
def _retrieve_context(self, user_query: str) -> str:
"""Retrieves and formats context from documents matching the user query."""
context_strings = [node.text for node in self.retriever.retrieve(user_query)]
return "\n".join(context_strings) # Basic context formatting for demo-purposes
def handle_response_and_tools(self, query: str) -> ChatResponse:
"""Manages tool-calling conversation loop using transient message history.
Creates temporary chat history to track tool interactions without affecting main conversation.
Loops through tool calls and responses until completion, then returns final response to user.
"""
# Create a temporary chat history for tool interactions
temp_chat_history = self.chat_history.copy()
print(f"[internal log] Invoking LLM text\n{query}\n\n")
response = self.llm.chat_with_tools(
tools=self.tools,
user_msg=query,
chat_history=temp_chat_history[:-1],
)
tool_calls = self.llm.get_tool_calls_from_response(
response, error_on_no_tool_call=False
)
while tool_calls:
temp_chat_history.append(response.message)
# If any tools are called, run with the tools until we hit the Alpha tool and return
for tool_call in tool_calls:
print(f'[internal log] Called {tool_call.tool_name} tool, with arguments: {tool_call.tool_kwargs}')
tool = self._tools_map[tool_call.tool_name]
tool_kwargs = tool_call.tool_kwargs
tool_output = tool(**tool_kwargs)
temp_chat_history.append(ChatMessage(role="tool", content=str(tool_output), additional_kwargs={"tool_call_id": tool_call.tool_id}))
response = self.llm.chat_with_tools([tool], chat_history=temp_chat_history)
print(f'[internal log] Tool response: {response.message.content}')
tool_calls = self.llm.get_tool_calls_from_response(
response, error_on_no_tool_call=False
)
return response
Example tool: get_todays_date
Let’s define an example tool get_todays_date() that our RAG app can rely on. LlamaIndex makes this much easier - just write normal Python functions and it automatically: reads your function name and docstring, understands your parameters and type hints, and creates the LLM-friendly format for you.
from datetime import datetime
def get_todays_date(date_format: str) -> str:
"A tool that returns today's date in the date format requested. Options for date_format parameter are: '%Y-%m-%d', '%d', '%m', '%Y'."
datetime_str = datetime.now().strftime(date_format)
return datetime_str
Update our LLM system prompt with tool call instructions
For the best performance, add instructions on when to use the tool into the system prompt that governs your LLM. Below we simply added Step 3. in our list of instructions, which are otherwise represent a typical RAG system prompt. In most RAG apps, one instructs the LLM on what fallback_answer to respond with when it does not know how to answer a user’s query. Such fallback instructions help you reduce hallucinations and more precisely control the AI.
fallback_answer = "Based on the available information, I cannot provide a complete answer to this question."
system_message = f"""You are a helpful assistant designed to help users navigate a complex set of documents for question-answering tasks. Answer the user's Question based on the following possibly relevant Context and previous chat history using the tools provided if necessary. Follow these rules in order:
1. NEVER use phrases like "according to the context", "as the context states", etc. Treat the Context as your own knowledge, not something you are referencing.
2. Use only information from the provided Context.
3. Give a clear, short, and accurate Answer. Explain complex terms if needed.
4. If the answer to the question requires today's date, use the following tool: get_todays_date. Return the date in the exact format the tool provides it.
5. If the Context doesn't adequately address the Question or you are unsure how to answer the Question, say: "{fallback_answer}" only, nothing else.
Remember, your purpose is to provide information based on the Context, not to offer original advice.
"""
Initialize our RAG App
Finally, let’s set up our LLM that supports tool calling and initialize our RAG App. Any LlamaIndex-compatible LLM can be used here, as long as it supports tool calling
llm = OpenAI(model=model) # API key can be set via OPENAI_API_KEY environment variable or .env file
chat_history = [
ChatMessage(role="system", content=system_message),
]
tools = [FunctionTool.from_defaults(fn=get_todays_date)] # Add your tools here
rag = RAGApp(llm=llm, tools=tools, retriever=retriever, messages=chat_history)
RAG in action
Let’s run our RAG application over different questions commonly asked by users about the Simple Water Bottle in our example.
Scenario 1: RAG can answer the question without tools
response = rag("How big is the water bottle?")
print(f'\n[RAG response] {response.message.content}')
Here the LLM was able to provide a good answer because the retrieved context contains the necessary information.
Scenario 2: RAG can answer the question using tools
response = rag("Has the limited edition Amber water bottle already launched?")
print(f'\n[RAG response] {response.message.content}')
In this case, the LLM chose to call our get_todays_date tool to obtain information necessary for properly answering the user’s query. Note that a proper answer to this question also requires considering information from the retrieved context as well.
Scenario 3: RAG cannot answer the question
response = rag("Can I return my simple water bottle?")
print(f'\n[RAG response] {response.message.content}')
Note that the Context does not contain information about the return policy, and the get_todays_date tool would not help either.
In this case, we want to return our fallback response to the user.
Next Steps
Adding tool calls to your RAG system expands the capabilities of what your AI can do and the types of questions it can answer.
Once you have a RAG app with tools set up, adding Codex as-a-Tool takes only a few lines of code. Codex enables your RAG app to answer questions it previously could not (like Scenario 3 above). Learn how via our tutorial: Integrate Codex as-a-Tool with LlamaIndex.
Need help? Check the FAQ or email us at: support@cleanlab.ai