RAG with Tool Calls in AWS Bedrock Knowledge Bases

This tutorial covers the basics of building a conversational RAG application that supports tool calls, via the AWS Bedrock Knowledge Bases and Converse APIs. Here we demonstrate how to build the specific RAG app used in our Integrate Codex as-a-Tool with AWS Bedrock Knowledge Bases tutorial. Remember that Codex works with any RAG app, you can easily translate these ideas to more complex RAG pipelines.
Here’s a typical architecture for RAG apps with tool calling:
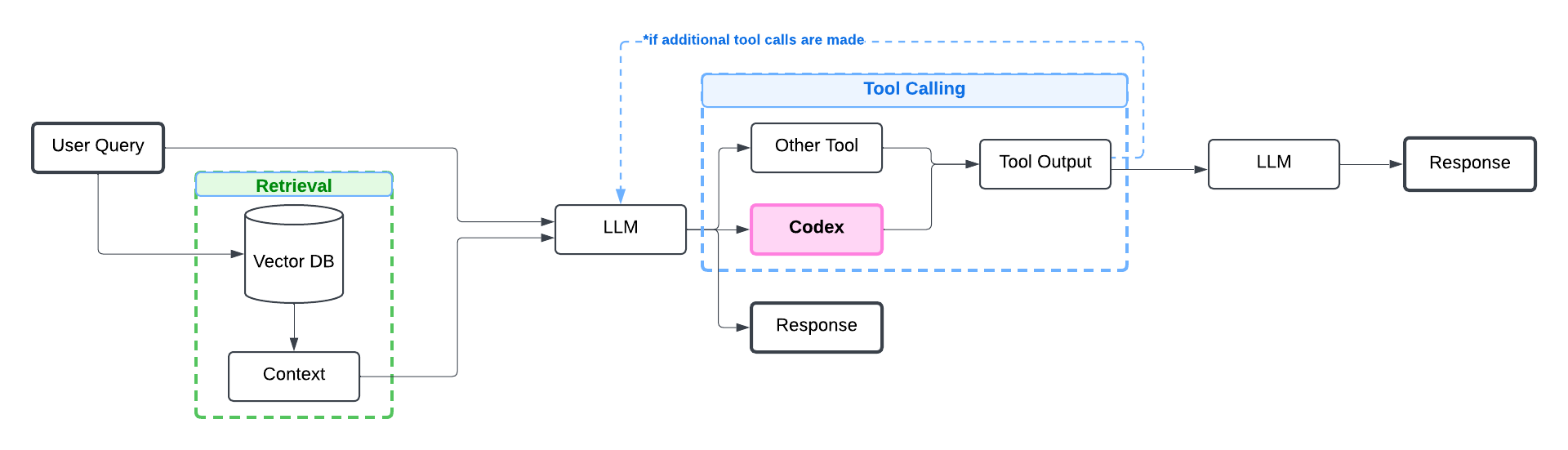
Let’s first install packages required for this tutorial and set up AWS credentials.
%pip install -U boto3 # we used package-version 1.36.0
Optional: Set up AWS configurations
import os
import boto3
os.environ["AWS_ACCESS_KEY_ID"] = (
"<YOUR_AWS_ACCESS_KEY_ID>" # Your permament access key (not session access key)
)
os.environ["AWS_SECRET_ACCESS_KEY"] = (
"<YOUR_AWS_SECRET_ACCESS_KEY>" # Your permament secret access key (not session secret access key)
)
os.environ["MFA_DEVICE_ARN"] = (
"<YOUR_MFA_DEVICE_ARN>" # If your organization requires MFA, find this in AWS Console under: settings -> security credentials -> your mfa device
)
os.environ["AWS_REGION"] = "us-east-1" # Specify your AWS region
# Load environment variables
aws_access_key_id = os.getenv("AWS_ACCESS_KEY_ID")
aws_secret_access_key = os.getenv("AWS_SECRET_ACCESS_KEY")
region_name = os.getenv("AWS_REGION", "us-east-1") # Default to 'us-east-1' if not set
mfa_serial_number = os.getenv("MFA_DEVICE_ARN")
# Ensure required environment variables are set
if not all([aws_access_key_id, aws_secret_access_key, mfa_serial_number]):
raise EnvironmentError(
"Missing required environment variables. Ensure AWS_ACCESS_KEY_ID, "
"AWS_SECRET_ACCESS_KEY, and MFA_DEVICE_ARN are set."
)
# Enter MFA code in case your AWS organization requires it
mfa_token_code = input("Enter your MFA code: ")
print("MFA code entered: ", mfa_token_code)
sts_client = boto3.client(
"sts",
aws_access_key_id=aws_access_key_id,
aws_secret_access_key=aws_secret_access_key,
region_name=region_name,
)
try:
# Request temporary credentials
response = sts_client.get_session_token(
DurationSeconds=3600 * 24, # Valid for 24 hours
SerialNumber=mfa_serial_number,
TokenCode=mfa_token_code,
)
temp_credentials = response["Credentials"]
temp_access_key = temp_credentials["AccessKeyId"]
temp_secret_key = temp_credentials["SecretAccessKey"]
temp_session_token = temp_credentials["SessionToken"]
print("Successfully set up AWS credentials.")
except Exception as e:
print(f"Error setting up AWS credentials: {e}")
Next we’ll initialize Bedrock clients for the retrieval and generation steps of our RAG pipeline.
from botocore.client import Config
bedrock_config = Config(
connect_timeout=120, read_timeout=120, retries={"max_attempts": 0}
)
BEDROCK_RETRIEVE_CLIENT = boto3.client(
"bedrock-agent-runtime",
config=bedrock_config,
aws_access_key_id=temp_access_key,
aws_secret_access_key=temp_secret_key,
aws_session_token=temp_session_token,
region_name=region_name,
)
BEDROCK_GENERATION_CLIENT = boto3.client(
service_name="bedrock-runtime",
aws_access_key_id=temp_access_key,
aws_secret_access_key=temp_secret_key,
aws_session_token=temp_session_token,
region_name=region_name,
)
Example RAG App: Product Customer Support
Consider a customer support / e-commerce RAG use-case where the Knowledge Base contains product listings like the following:
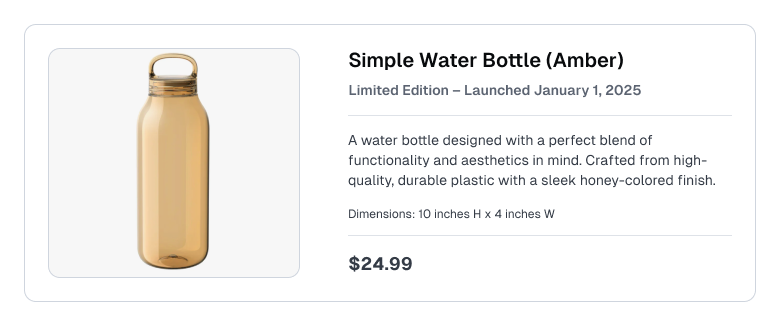
Creating a Knowledge Base
To keep our example simple, we upload the product description to AWS S3 as a single file: simple_water_bottle.txt. This is the sole file our Knowledge Base will contain, but you can populate your actual Knowledge Base with many heterogeneous documents.
To create a Knowledge Base using Amazon Bedrock, refer to the official documentation.
After you’ve created it, add your KNOWLEDGE_BASE_ID below.
KNOWLEDGE_BASE_ID = "DASYAHIOKX" # replace with your own Knowledge Base
Implement a standard RAG pipeline
A RAG pipeline has two key steps – retrieval and generation, which we implement using AWS Bedrock APIs. Building on the most basic RAG pipeline, we’ll add tool calling support to the generation step.
Retrieval in AWS Knowledge Bases
We’ve defined some helper methods for retrieving context from our Knowledge Base below. You may want to modify these or use your own retrieval logic to fit your use case.
Optional: Helper methods for Retrieval in AWS Knowledge Bases
from typing import Any
def retrieve(
bedrock_client: boto3.client,
query: str,
knowledge_base_id: str,
number_of_results: int = 3,
) -> dict[str, Any]:
"""Fetches relevant document chunks to query from Knowledge Base using AWS Bedrock Agent Runtime"""
return bedrock_client.retrieve(
retrievalQuery={"text": query},
knowledgeBaseId=knowledge_base_id,
retrievalConfiguration={
"vectorSearchConfiguration": {
"numberOfResults": number_of_results,
"overrideSearchType": "HYBRID",
}
},
)
def retrieve_and_format_context(
bedrock_client: boto3.client,
query: str,
knowledge_base_id: str,
number_of_results: int = 3,
threshold: float = 0.0,
) -> list[str]:
"""Fetches relevant contexts and does some processing to format results for the subsequent LLM response generation step."""
retrieval_results = retrieve(
bedrock_client, query, knowledge_base_id, number_of_results
)
contexts = []
for result in retrieval_results["retrievalResults"]:
if result["score"] >= threshold:
contexts.append(result["content"]["text"])
return contexts
# Similarity score threshold for retrieving context to use in our RAG app
SCORE_THRESHOLD = 0.3
Let’s test our retrieval component with a query.
query = "What is the Simple Water Bottle?"
results = retrieve_and_format_context(BEDROCK_RETRIEVE_CLIENT, query, KNOWLEDGE_BASE_ID)
results[0]
Response generation with tool calling
To generate responses with an LLM that can also call tools, we pass the user query and retrieved context from our Knowledge Base into the AWS Converse API.
This API can either return a string response from the LLM or a tool call. We define our generation logic so that if the output is a tool call, we keep prompting the Converse API with the result of the tool call until the LLM returns a string response.
Our generation method is defined below. You may want to modify this or use your own response generation logic to fit your use case.
Optional: Helper methods for response generation with tool calling via AWS Converse API
def form_prompt(user_question: str, contexts: list[str]) -> str:
"""Forms the prompt to be used for querying the model."""
context_strings = "\n\n".join(
[f"Context {i + 1}: {context}" for i, context in enumerate(contexts)]
)
query_with_context = f"{context_strings}\n\nQUESTION:\n{user_question}"
indented_question_with_context = "\n".join(
f" {line}" for line in query_with_context.splitlines()
)
return indented_question_with_context
def generate_text(
bedrock_client: boto3.client,
user_question: str,
model: str,
tools: list[dict[str, Any]],
system_prompts: list[dict[str, Any]],
messages: list[dict[str, Any]],
) -> list[dict[str, Any]]:
"""Generates a response from the LLM using AWS Converse API, handling tool calls as necessary.
Params:
bedrock_client: Client to interact with Bedrock API.
user_question: The user's question or query.
model: Identifier for the Amazon Bedrock model.
tools: List of tools the model can call. See https://docs.aws.amazon.com/bedrock/latest/APIReference/API_runtime_Tool.html for expected format.
system_prompts: System message to provide instructions or context to the LLM. See https://docs.aws.amazon.com/bedrock/latest/APIReference/API_runtime_SystemContentBlock.html for expected format.
messages: List of message history in the desired format (see https://docs.aws.amazon.com/bedrock/latest/APIReference/API_runtime_Message.html). This should include the current user question as the latest message.
Returns:
messages: Final updated list of messages including tool interactions and responses.
"""
# Initial call to the model
response = bedrock_client.converse(
modelId=model,
messages=messages,
toolConfig=tools,
system=system_prompts,
)
output_message = response["output"]["message"]
stop_reason = response["stopReason"]
messages.append(output_message)
while stop_reason == "tool_use":
# Extract tool requests from the model response
tool_requests = output_message.get("content", [])
for tool_request in tool_requests:
if "toolUse" in tool_request:
messages.append(
_handle_tool_request(user_question, tool_request["toolUse"])
)
# Send the updated messages back to the model
response = bedrock_client.converse(
modelId=model,
messages=messages,
toolConfig=tools,
system=system_prompts,
)
output_message = response["output"]["message"]
stop_reason = response["stopReason"]
messages.append(output_message)
return messages
def _handle_tool_request(
user_question: str, tool_use_block: dict[str, Any]
) -> dict[str, Any]:
"""Handles a tool request by calling the tool function and returning the result formatted as a ToolResultBlock
(see https://docs.aws.amazon.com/bedrock/latest/APIReference/API_runtime_ToolResultBlock.html).
"""
tool_name = tool_use_block["name"]
tool_input = tool_use_block["input"]
tool_use_id = tool_use_block["toolUseId"]
try:
# If you don't want the original question to be modified, use this instead
if "question" in tool_input.keys():
tool_input["question"] = user_question
print(
f"[internal log] Requesting tool {tool_name} with arguments: {tool_input}."
)
try:
tool_result = _execute_tool_call(tool_name, tool_input)
print(f"[internal log] Tool response: {tool_result}")
return _format_tool_result_message(tool_use_id, tool_result)
except Exception as e:
return _format_tool_error_message(tool_use_id, str(e))
except Exception as e:
# Handle unexpected exceptions during tool handling
return _format_tool_error_message(
tool_use_id, f"Error processing tool: {str(e)}"
)
def _format_tool_result_message(tool_use_id: str, tool_result: Any) -> dict[str, Any]:
"""Formats a tool result message."""
return {
"role": "user",
"content": [
{
"toolResult": {
"toolUseId": tool_use_id,
"content": [{"json": {"response": tool_result}}],
}
}
],
}
def _format_tool_error_message(tool_use_id: str, error_message: str) -> dict[str, Any]:
"""Handles tool errors by returning a dictionary with the error message and arguments."""
return {
"role": "user",
"content": [
{
"toolResult": {
"toolUseId": tool_use_id,
"content": [{"text": error_message}],
"status": "error",
}
}
],
}
def _execute_tool_call(function_name: str, arguments: dict[str, Any]) -> Any:
"""Handles any tool dynamically by calling the function by name and passing in collected arguments.
Returns:
The tool output.
Raises:
Exception: If the tool is not found, not callable, or called incorrectly.
"""
tool_function = globals().get(function_name) or locals().get(function_name)
if callable(tool_function):
try:
# Dynamically call the tool function with arguments
tool_output = tool_function(**arguments)
return tool_output
except Exception as e:
raise Exception(f"Exception while calling tool '{function_name}': {str(e)}")
else:
raise Exception(f"Tool '{function_name}' not found or not callable.")
Define single-turn RAG app
We integrate the above helper methods into a standard RAG app that can respond to any user query, calling tools as the LLM deems necessary. Our rag() method can be called multiple times in a conversation, as long as a messages variable is provided each time to track conversation history.
def rag(
model: str,
user_question: str,
system_prompt: str,
tools: list[dict[str, Any]],
messages: list[dict[str, Any]],
knowledge_base_id: str,
) -> str:
"""Performs Retrieval-Augmented Generation using the provided model and tools.
Params:
model: Model name or ID.
user_question: The user's question or query.
system_prompt: System message to provide instructions or context to the LLM.
tools: List of tools the model can call. See https://docs.aws.amazon.com/bedrock/latest/APIReference/API_runtime_ToolConfiguration.html for expected format.
messages: Optional list of prior conversation history. See https://docs.aws.amazon.com/bedrock/latest/APIReference/API_runtime_Message.html for expected format.
knowledge_base_id: Knowledge base ID for retrieving contexts.
Returns:
Final response text generated by the model.
"""
# Retrieve contexts based on the user query and knowledge base ID
contexts = retrieve_and_format_context(
BEDROCK_RETRIEVE_CLIENT,
user_question,
knowledge_base_id,
threshold=SCORE_THRESHOLD,
)
query_with_context = form_prompt(user_question, contexts)
print(
f"[internal log] Invoking LLM text:\n{query_with_context}\n\n"
)
# Construct the user message with the retrieved contexts and add to message history
user_message = {"role": "user", "content": [{"text": query_with_context}]}
messages.append(user_message)
# Construct system prompt in the format required by the AWS Converse API
system_prompts = [{"text": system_prompt}]
# Call generate_text with the updated messages
final_messages = generate_text(
user_question=user_question,
model=model,
tools=tools,
system_prompts=system_prompts,
messages=messages,
bedrock_client=BEDROCK_GENERATION_CLIENT,
)
# Extract and return the final response text
return final_messages[-1]["content"][-1]["text"]
Example tool: get_todays_date
Let’s define an example tool, get_todays_date(), to use in our RAG system. We provide the corresponding function and instructions on how to use it in the JSON format required by the AWS Converse API.
from datetime import datetime
def get_todays_date(date_format: str) -> str:
"""A tool that returns today's date in the date format requested."""
datetime_str = datetime.now().strftime(date_format)
return datetime_str
todays_date_tool_json = {
"toolSpec": {
"name": "get_todays_date",
"description": "A tool that returns today's date in the date format requested. Options are: '%Y-%m-%d', '%d', '%m', '%Y'.",
"inputSchema": {
"json": {
"type": "object",
"properties": {
"date_format": {
"type": "string",
"description": "The format that the tool requests the date in.",
}
},
"required": ["date_format"],
}
},
}
}
System prompt with tool use instructions
For best performance, add clear instructions on when to use the tool into the system prompt that governs your LLM. In our system prompt below, we add Step 4 to what is otherwise a typical RAG system prompt. The prompt also instructs the LLM on what fallback answer to respond with when it does not know how to answer a user’s query. Such fallback instructions help you reduce hallucinations and more precisely control the AI.
fallback_answer = "Based on the available information, I cannot provide a complete answer to this question."
system_prompt = f"""You are a helpful assistant designed to help users navigate a complex set of documents for question-answering tasks. Answer the user's Question based on the following possibly relevant Context and previous chat history using the tools provided if necessary. Follow these rules in order:
1. NEVER use phrases like "according to the context", "as the context states", etc. Treat the Context as your own knowledge, not something you are referencing.
2. Use only information from the provided Context.
3. Give a clear, short, and accurate Answer. Explain complex terms if needed.
4. If the answer to the question requires today's date, use the following tool: get_todays_date. Return the date in the exact format the tool provides it.
5. If the Context doesn't adequately address the Question or you are unsure how to answer the Question, say: "{fallback_answer}" only, nothing else.
Remember, your purpose is to provide information based on the Context, not to offer original advice.
"""
Conversational RAG with tool calling
Now we’re ready to run our RAG pipeline. Let’s first initialize a messages variable to track conversation history. This variable is updated each time we call the rag() method to respond to a user query.
We’ll also select an LLM for our RAG pipeline and define a list of tools that are available (using the get_todays_date tool we defined above).
After that, we can chat with our RAG app! Here we try a few user queries to evaluate different scenarios.
messages = []
model = "arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-3-5-sonnet-20240620-v1:0"
tool_config = {"tools": [todays_date_tool_json]}
Scenario 1: RAG can answer the question without tools
user_question = "How big is the water bottle?"
rag_response = rag(
model=model,
user_question=user_question,
system_prompt=system_prompt,
tools=tool_config,
messages=messages,
knowledge_base_id=KNOWLEDGE_BASE_ID,
)
print(f"[RAG response] {rag_response}")
For this user query, the necessary information is available in the Knowledge Base (as part of the product description).
Scenario 2: RAG can answer the question using tools
user_question = "Has the limited edition Amber water bottle already launched?"
rag_response = rag(
model=model,
user_question=user_question,
system_prompt=system_prompt,
tools=tool_config,
messages=messages,
knowledge_base_id=KNOWLEDGE_BASE_ID,
)
print(f"[RAG response] {rag_response}")
For this user query, the LLM chose to call our get_todays_date tool to obtain necessary information. Note that a proper answer to this question requires considering information from the Knowledge Base as well.
Scenario 3: RAG can answer the question considering conversation history
user_question = "What is the full name of it?"
rag_response = rag(
model=model,
user_question=user_question,
system_prompt=system_prompt,
tools=tool_config,
messages=messages,
knowledge_base_id=KNOWLEDGE_BASE_ID,
)
print(f"[RAG response] {rag_response}")
This user query only makes sense when taking the conversation history into account.
Scenario 4: RAG cannot answer the question
user_question = "Can I return my simple water bottle?"
rag_response = rag(
model=model,
user_question=user_question,
system_prompt=system_prompt,
tools=tool_config,
messages=messages,
knowledge_base_id=KNOWLEDGE_BASE_ID,
)
print(f"[RAG response] {rag_response}")
Note that the Knowledge Base does not contain information about the return policy, and the get_todays_date tool would not help either. In this case, the best our RAG app can do is to return our fallback response to the user.
Optional: Review full message history (includes tool calls)
# message history
for message in messages:
print(message)
{'role': 'user', 'content': [{'text': ' Context 1: Simple Water Bottle - Amber (limited edition launched Jan 1st 2025) A water bottle designed with a perfect blend of functionality and aesthetics in mind. Crafted from high-quality, durable plastic with a sleek honey-colored finish. Price: $24.99 \\nDimensions: 10 inches height x 4 inches width\n \n QUESTION:\n How big is the water bottle?'}]}
{'role': 'assistant', 'content': [{'text': "The Simple Water Bottle - Amber has the following dimensions:\n\n10 inches in height\n4 inches in width\n\nThese measurements provide a clear picture of the size of the water bottle. It's a relatively tall and slender design, which is common for many reusable water bottles. The 10-inch height would make it suitable for most cup holders, while the 4-inch width ensures it's easy to grip and carry."}]}
{'role': 'user', 'content': [{'text': ' Context 1: Simple Water Bottle - Amber (limited edition launched Jan 1st 2025) A water bottle designed with a perfect blend of functionality and aesthetics in mind. Crafted from high-quality, durable plastic with a sleek honey-colored finish. Price: $24.99 \\nDimensions: 10 inches height x 4 inches width\n \n QUESTION:\n Has the limited edition Amber water bottle already launched?'}]}
{'role': 'assistant', 'content': [{'text': "To answer this question accurately, we need to know today's date and compare it to the launch date of the Simple Water Bottle - Amber limited edition. Let's use the get_todays_date tool to find out the current date."}, {'toolUse': {'toolUseId': 'tooluse_gnYJBA6sSiy2gt7Mr1CJbw', 'name': 'get_todays_date', 'input': {'date_format': '%Y-%m-%d'}}}]}
{'role': 'user', 'content': [{'toolResult': {'toolUseId': 'tooluse_gnYJBA6sSiy2gt7Mr1CJbw', 'content': [{'json': {'response': '2025-02-25'}}]}}]}
{'role': 'assistant', 'content': [{'text': "Based on the information provided in the context and the current date, we can determine that:\n\nThe Simple Water Bottle - Amber limited edition was launched on January 1st, 2025.\nToday's date is February 25, 2025.\n\nSince today's date (February 25, 2025) is after the launch date (January 1st, 2025), the limited edition Amber water bottle has already launched. It has been available for nearly two months at this point."}]}
{'role': 'user', 'content': [{'text': ' Context 1: Simple Water Bottle - Amber (limited edition launched Jan 1st 2025) A water bottle designed with a perfect blend of functionality and aesthetics in mind. Crafted from high-quality, durable plastic with a sleek honey-colored finish. Price: $24.99 \\nDimensions: 10 inches height x 4 inches width\n \n QUESTION:\n What is the full name of it?'}]}
{'role': 'assistant', 'content': [{'text': 'The full name of the product is Simple Water Bottle - Amber. This is a limited edition version of the water bottle that was launched on January 1st, 2025.'}]}
{'role': 'user', 'content': [{'text': ' Context 1: Simple Water Bottle - Amber (limited edition launched Jan 1st 2025) A water bottle designed with a perfect blend of functionality and aesthetics in mind. Crafted from high-quality, durable plastic with a sleek honey-colored finish. Price: $24.99 \\nDimensions: 10 inches height x 4 inches width\n \n QUESTION:\n Can I return my simple water bottle?'}]}
{'role': 'assistant', 'content': [{'text': 'Based on the available information, I cannot provide a complete answer to this question.'}]}
Next Steps
Adding tool calls to your RAG system expands the capabilities of what your AI can do and the types of questions it can answer.
Once you have a RAG app with tools set up, adding Codex as-a-Tool takes only a few lines of code. Codex enables your RAG app to answer questions it previously could not (like Scenario 4 above). Learn how via our tutorial: Integrate Codex as-a-Tool with AWS Bedrock Knowledge Bases.
Need help? Check the FAQ or email us at: support@cleanlab.ai.